
Большинство двухмерных квазислучайных методов рассчитано на сэмплирование в единичном квадрате. Однако в компьютерной графике также очень важны треугольники. Поэтому я описал простой метод прямого построения для равномерного покрытия последовательностью точек треугольника произвольной формы.

Рисунок 1. Новый прямой метод построения открытой (бесконечной) квазислучайной последовательности с низким расхождением в треугольнике произвольной формы и размера. На рисунке показаны распределения точек в пятнадцати случайных треугольниках для первых 150 точек.
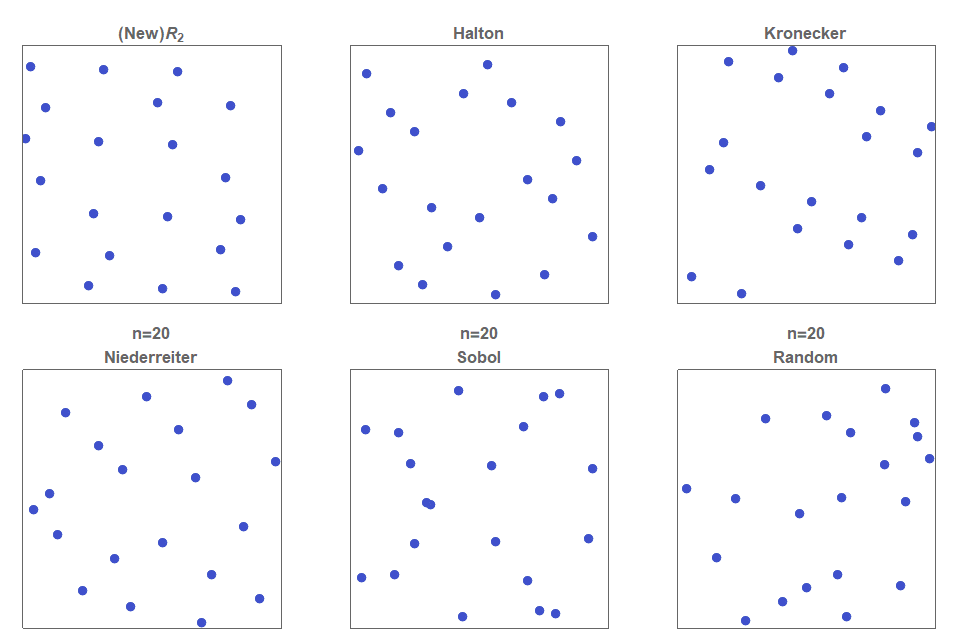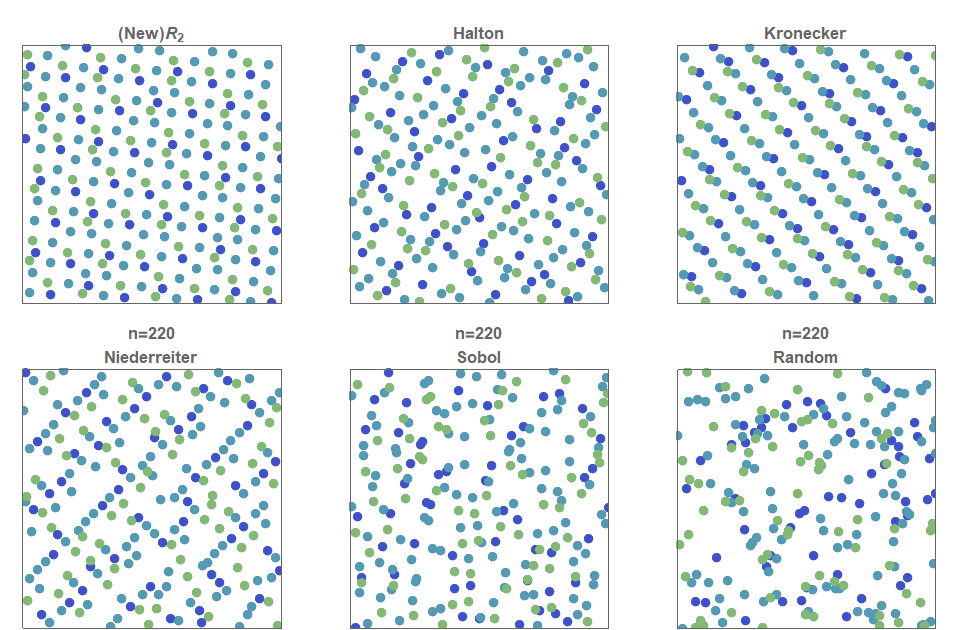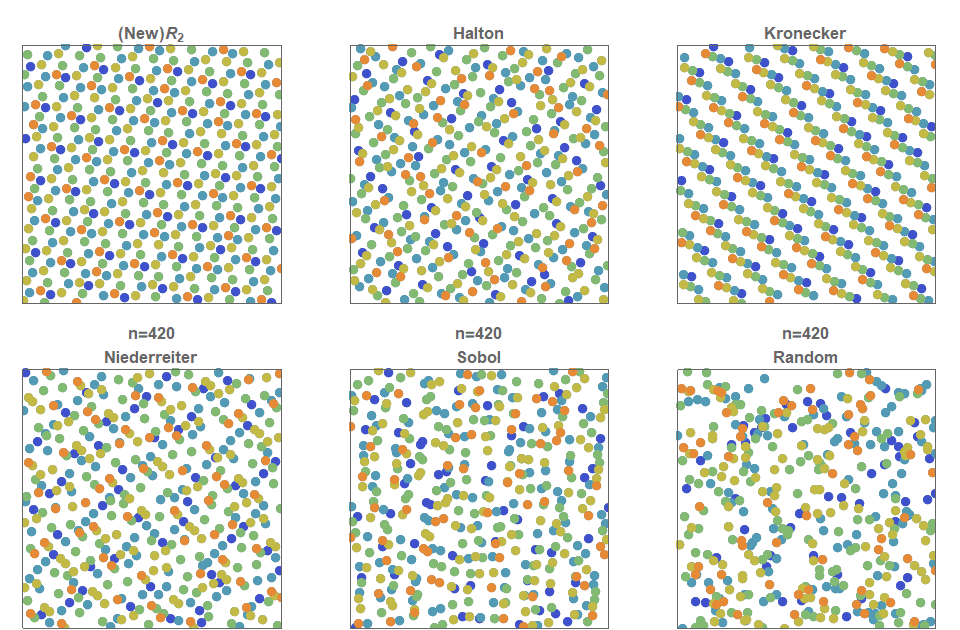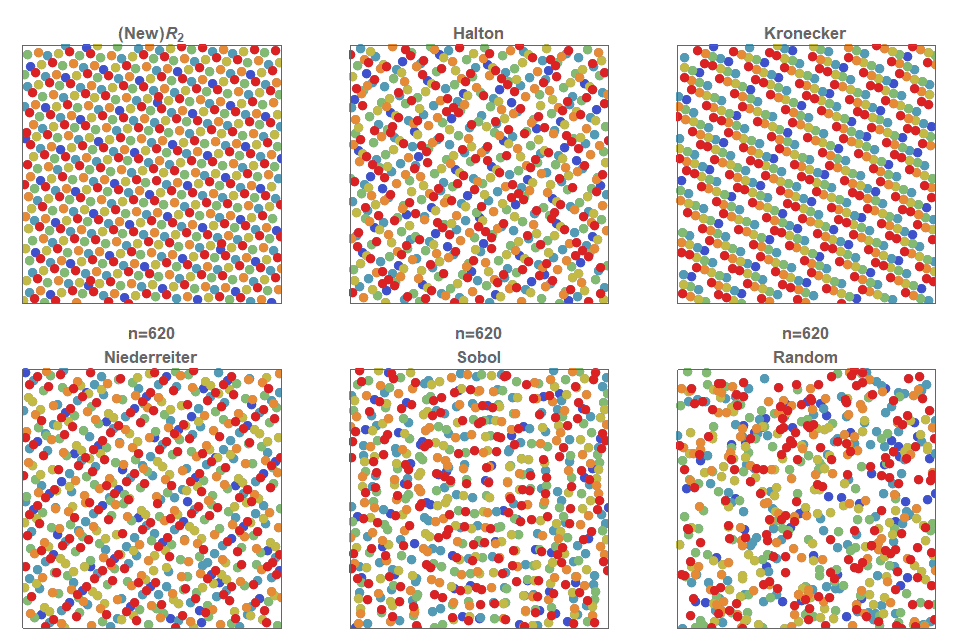
Последовательности с низким расхождением (low discrepancy), равномерно сэмплирующие/заполняющие квадрат, активно изучались почти сотню лет. БОльшую часть этих квазислучайных последовательностей можно расширить до прямоугольников простым растягиванием, не сильно повредив при этом расхождению.
Однако в этом посте мы рассмотрим интересное и важное расширение последовательностей с низким расхождением на произвольный треугольник.
Рисунок 1. Новый прямой метод построения открытой (бесконечной) квазислучайной последовательности с низким расхождением в треугольнике произвольной формы и размера. На рисунке показаны распределения точек в пятнадцати случайных треугольниках для первых 150 точек.
Краткий обзор
Последовательности с низким расхождением (low discrepancy), равномерно сэмплирующие/заполняющие квадрат, активно изучались почти сотню лет. БОльшую часть этих квазислучайных последовательностей можно расширить до прямоугольников простым растягиванием, не сильно повредив при этом расхождению.
Однако в этом посте мы рассмотрим интересное и важное расширение последовательностей с низким расхождением на произвольный треугольник.








 Как то раз появилась следующая задача: создать локального пользователя в ОС Linux, с ограниченным доступом к папкам и файлам, включая не только редактирование, но и просмотр, а также возможность использовать только разрешенные утилиты. Предусматривается только локальный доступ, сетевого доступа нет.
Как то раз появилась следующая задача: создать локального пользователя в ОС Linux, с ограниченным доступом к папкам и файлам, включая не только редактирование, но и просмотр, а также возможность использовать только разрешенные утилиты. Предусматривается только локальный доступ, сетевого доступа нет.

