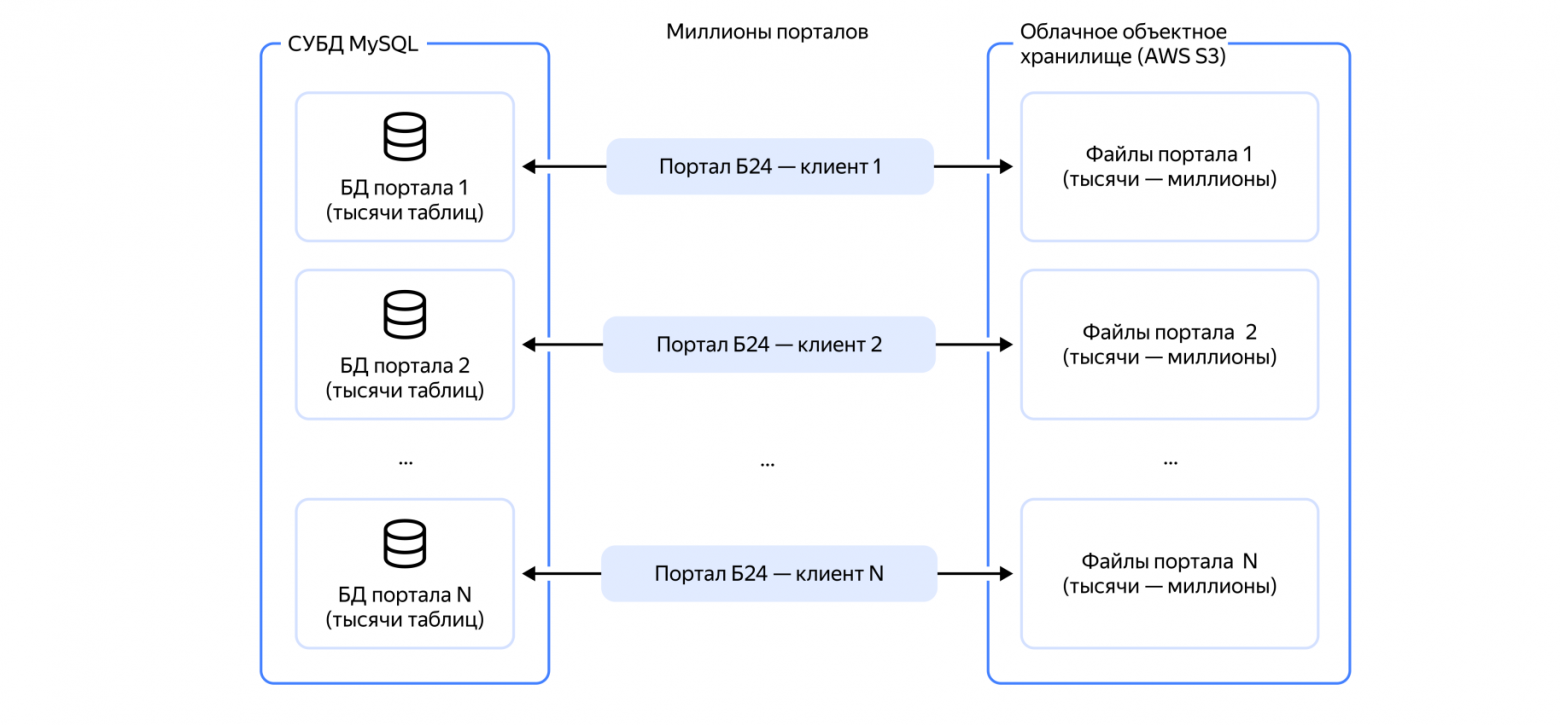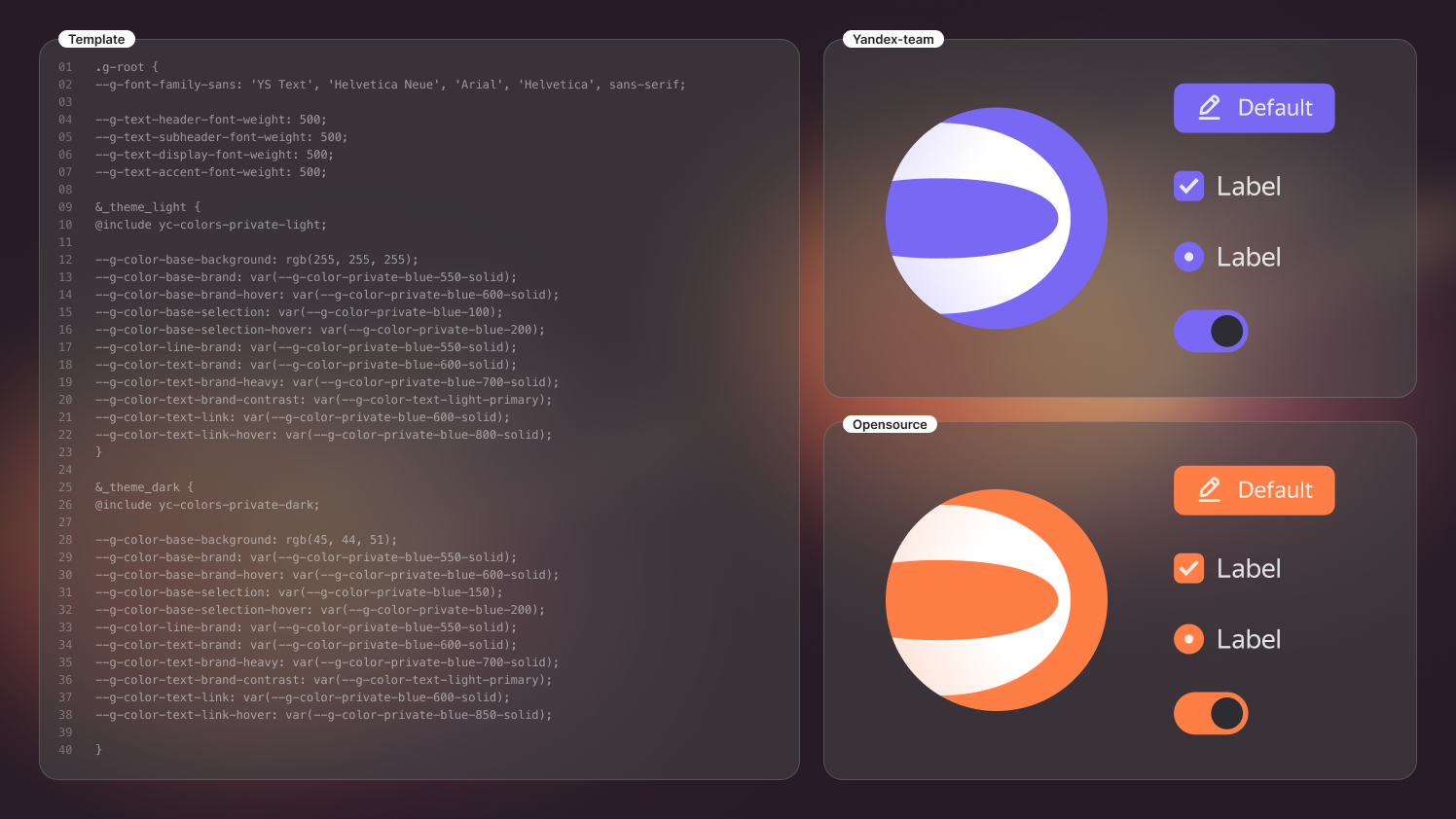
Меня зовут Алексей Афонин, я старший дизайнер продукта в Yandex Cloud. В прошлом году нам понадобилось полностью изменить внешний вид нашего сервиса для бизнес‑аналитики DataLens перед его выходом в опенсорс. Разработчики и дизайнеры интерфейсов часто сталкиваются с подобными задачами: есть уже работающий сервис, но его нужно стилизовать, например, в случае ребрендинга или при необходимости учесть специфический пользовательский опыт.
В наших продуктах мы пользуемся дизайн‑системой и библиотекой компонентов Gravity UI — это проект Yandex Cloud, который не так давно тоже вышел в опенсорс. В этой статье я поделюсь опытом, как мы решили задачу «перекрашивания DataLens» с её помощью. Но даже если вы не используете DataLens и ещё не знакомы с Gravity UI, наши наработки могут пригодиться командам разработчиков и дизайнеров, которые хотят стилизовать свои продукты быстрее и удобнее.