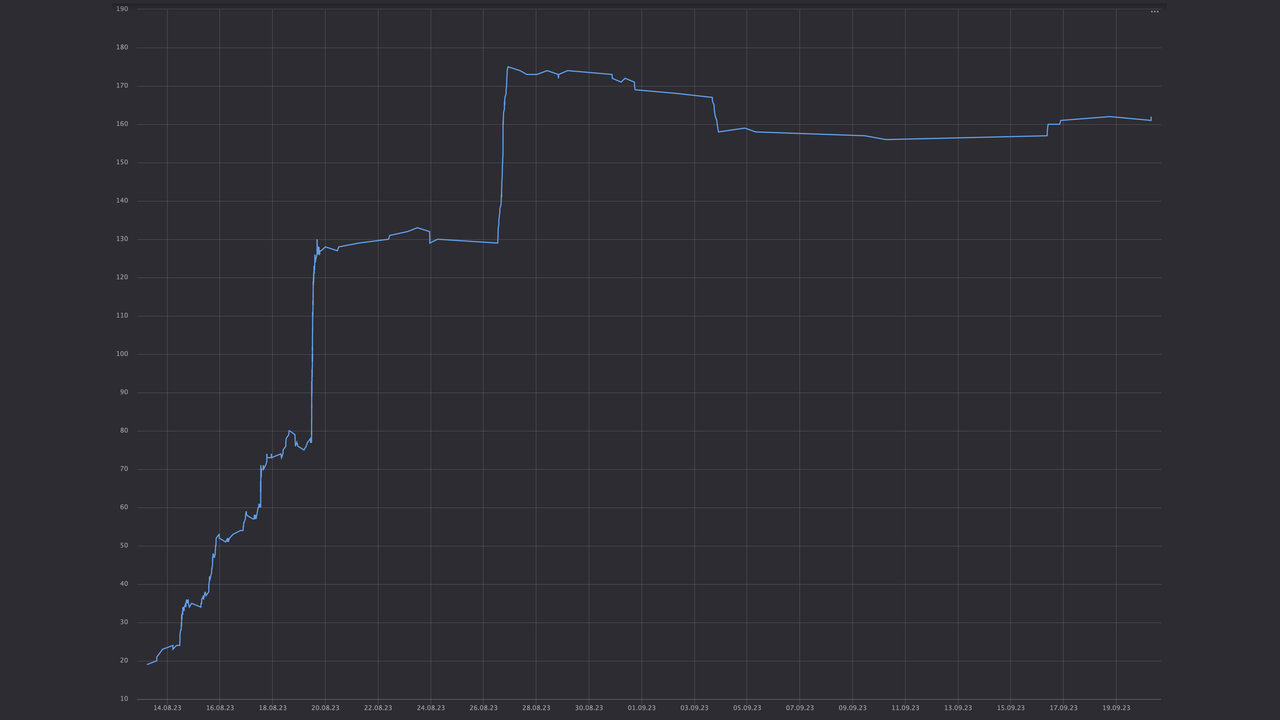
Сетевой стек Linux не прост даже на первый взгляд: приложение — в юзерспейсе, а всё, что после сокета, — в ядре операционки. И там тысяча реализаций TCP. Любое взаимодействие с сетью — системный вызов с переключением контекста в ядре.
Чтобы лишний раз не дёргать ядро прерываниями, придумали DMA — Direct Memory Access. И это дало жизнь классу софта с режимом работы kernel bypass: например при DPDK (Intel Data Plane Development Kit). Потом был BPF. А за ним — eBPF.
Но даже помимо хаков работы с ядром есть такие штуки, как sk_buff, в которой хранятся метаданные всех миллионов протоколов. Есть NAPI (New API), которая призвана уменьшить число прерываний. Есть 100500 вариантов разных tables.
И копать можно безгранично далеко. Но сегодня мы всё же поговорим о вещах более приземлённых и повседневных, которые лишь приоткрывают вход в эту разветвлённую сеть кроличьих нор. Мы разберём одну любопытную задачку, на примере которой ужаснёмся тому, как сложно может быть реализован такой простой протокол, как DHCP.