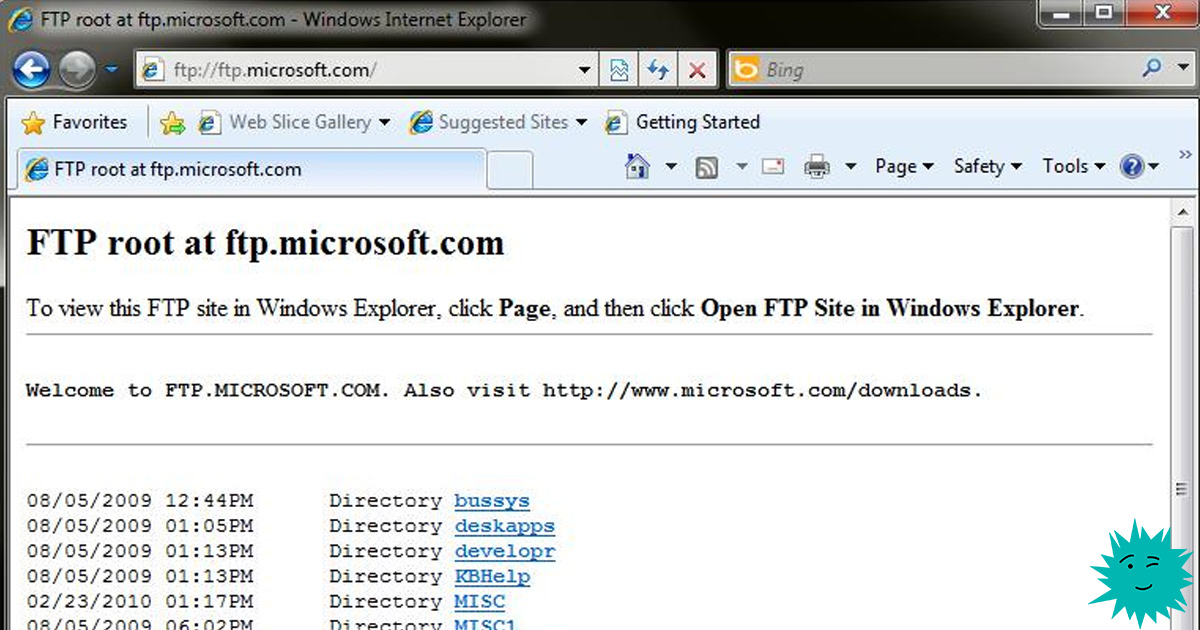
Вот небольшое известие, которое вы могли пропустить, восстанавливая свою жизнь после начала кризиса COVID: из-за того, что вирус перемешал всем карты, Google пропустила выпуск Chrome версии 82. «Да кого это волнует?», — спросите вы. Ну, хотя бы пользователей FTP, или File Transfer Protocol. Во время пандемии Google отложила свои планы по убийству FTP, и теперь, когда буря немного успокоилась,
Google недавно объявила о том, что возвращается к мысли об убийстве в Chrome версии 86, которая снова сократит поддержку протокола, и окончательно убьёт его в Chrome 88. (Mozilla объявила о похожих планах на Firefox,
утверждая, что дело в безопасности и возрасте поддерживающего протокол кода.) Это один из старейших протоколов, который поддерживает мейнстримный Интернет (в следующем году ему исполнится 50 лет), но эти популярные приложения хотят оставить его в прошлом. Сегодня мы поговорим об истории FTP, сетевого протокола, который продержался дольше, чем почти все остальные.




 NUMA (Non-Uniform Memory Access — «Неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — технология совсем не новая. Я бы даже сказала, что совсем старая. То есть, в терминах музыкальных инструментов, это уже даже не баян, а, скорее,
NUMA (Non-Uniform Memory Access — «Неравномерный доступ к памяти» или Non-Uniform Memory Architecture — «Архитектура с неравномерной памятью») — технология совсем не новая. Я бы даже сказала, что совсем старая. То есть, в терминах музыкальных инструментов, это уже даже не баян, а, скорее, 








{kind=link}