Есть отечественный файрвол (NGFW) и есть документация для пользователей powered by GitBook. В этой документации работает простой поиск — только по словам и словосочетаниям. И это плохо, потому что нет ответов на вопросы: "Какие алгоритмы шифрования ipsec поддерживаются у вас?", "Как заблокировать ютуб?", "Как настроить DMZ?".
Хочется, чтобы поиск был “умным” и чтобы пользователи могли обращаться с подобными вопросами именно к поиску, а не к инженерам тех. поддержки. AI или ML внутри — не важно, как это называть. Но на простые вопросы из списка выше поиск должен отвечать.
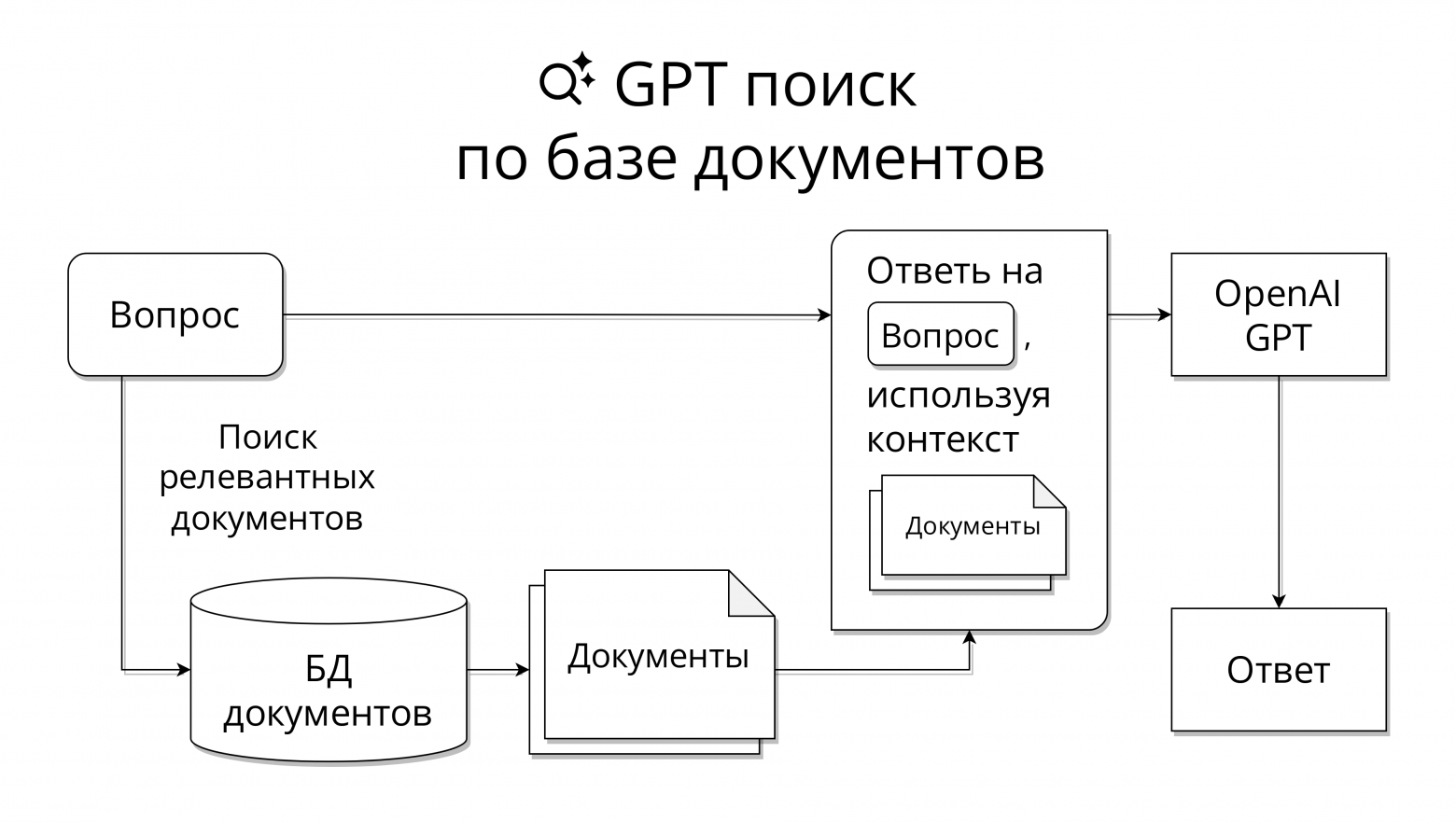
Я решил эту задачу (Retrieval Question Answering), используя OpenAI API. Казалось бы, уже опубликованы сотни похожих инструкций, как это сделать. Но под катом будет не инструкция, а рассказ про сложности, которые пришлось решить на пути от идеи до запуска поиска.