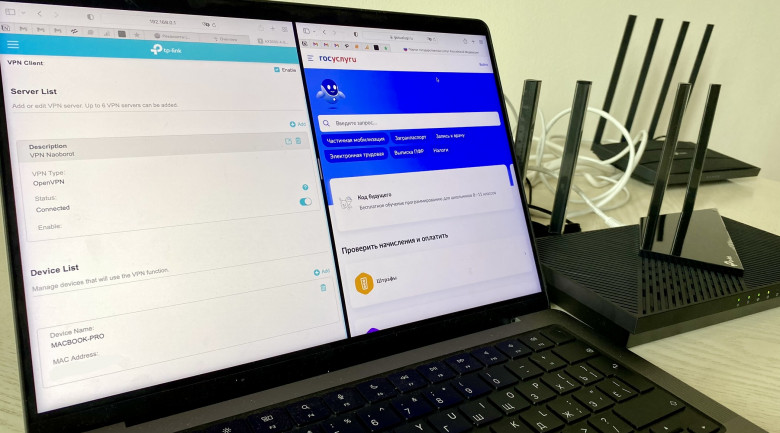
Пару недель назад я запустил "VPN Наоборот" – VPN с российским IP для доступа к сайтам, недоступным из-за рубежа. Ко мне обратились уже больше 1000 человек. Большинству из них я смог помочь. Огромное спасибо всем за донаты и тёплые слова!

Системный инженер
Пару недель назад я запустил "VPN Наоборот" – VPN с российским IP для доступа к сайтам, недоступным из-за рубежа. Ко мне обратились уже больше 1000 человек. Большинству из них я смог помочь. Огромное спасибо всем за донаты и тёплые слова!


Читатели Хабра, категорически вас приветствую! В этой статье я хочу поделиться с вами моделью эффективного изучения английского языка, которую я постарался сформировать исходя из своего n-летнего опыта его изучения.
Расскажу вам насколько это актуально, с чего начать, какие ресурсы и приемы использовать и как эффективно достичь результата.
Привет, Хабр! Мне 16 лет, я студент, учусь на первом курсе колледжа на программиста. Начал увлекаться низкоуровневым программированием на Ассемблере и C/C++
Я заметил что на Хабре есть множество статей о написании своих простых "загрузчиков" для BIOS-MBR, которые выводят на экран "Hello World!". И при этом практически нет ни одной статьи о создании того же самого, но только для UEFI, хотя будущее именно за ним, ведь BIOS уже давно устарел! Это я и хочу исправить в этой статье.



Привет, Хабр! Этой статьёй я открываю цикл материалов, посвящённых работе с большими данными. Зачем? Хочется сохранить накопленный опыт, свой и команды, так скажем, в энциклопедическом формате – наверняка кому-то он будет полезен.
Проблематику больших данных постараемся описывать с разных сторон: основные принципы работы с данными, инструменты, примеры решения практических задач. Отдельное внимание окажем теме машинного обучения.
Начинать надо от простого к сложному, поэтому первая статья – о принципах работы с большими данными и парадигме MapReduce.
Сообщество Open Data Science приветствует участников курса!
В рамках курса мы уже познакомились с несколькими ключевыми алгоритмами машинного обучения. Однако перед тем как переходить к более навороченным алгоритмам и подходам, хочется сделать шаг в сторону и поговорить о подготовке данных для обучения модели. Известный принцип garbage in – garbage out на 100% применим к любой задаче машинного обучения; любой опытный аналитик может вспомнить примеры из практики, когда простая модель, обученная на качественно подготовленных данных, показала себя лучше хитроумного ансамбля, построенного на недостаточно чистых данных.
UPD 01.2022: С февраля 2022 г. ML-курс ODS на русском возрождается под руководством Петра Ермакова couatl. Для русскоязычной аудитории это предпочтительный вариант (c этими статьями на Хабре – в подкрепление), англоговорящим рекомендуется mlcourse.ai в режиме самостоятельного прохождения.

Эта статья появилась по нескольким причинам.
Во-первых, в подавляющем большинстве книг, интернет-ресурсов и уроков по Data Science нюансы, изъяны разных типов нормализации данных и их причины либо не рассматриваются вообще, либо упоминаются лишь мельком и без раскрытия сути.
Во-вторых, имеет место «слепое» использование, например, стандартизации для наборов с большим количеством признаков — “чтобы для всех одинаково”. Особенно у новичков (сам был таким же). На первый взгляд ничего страшного. Но при детальном рассмотрении может выясниться, что какие-то признаки были неосознанно поставлены в привилегированное положение и стали влиять на результат значительно сильнее, чем должны.
И, в-третьих, мне всегда хотелось получить универсальный метод учитывающий проблемные места.

В поисках правильного решения для поддержки, развития и расширения возможностей вашего SOC, вот что необходимо знать при оценке XDR и SOAR.
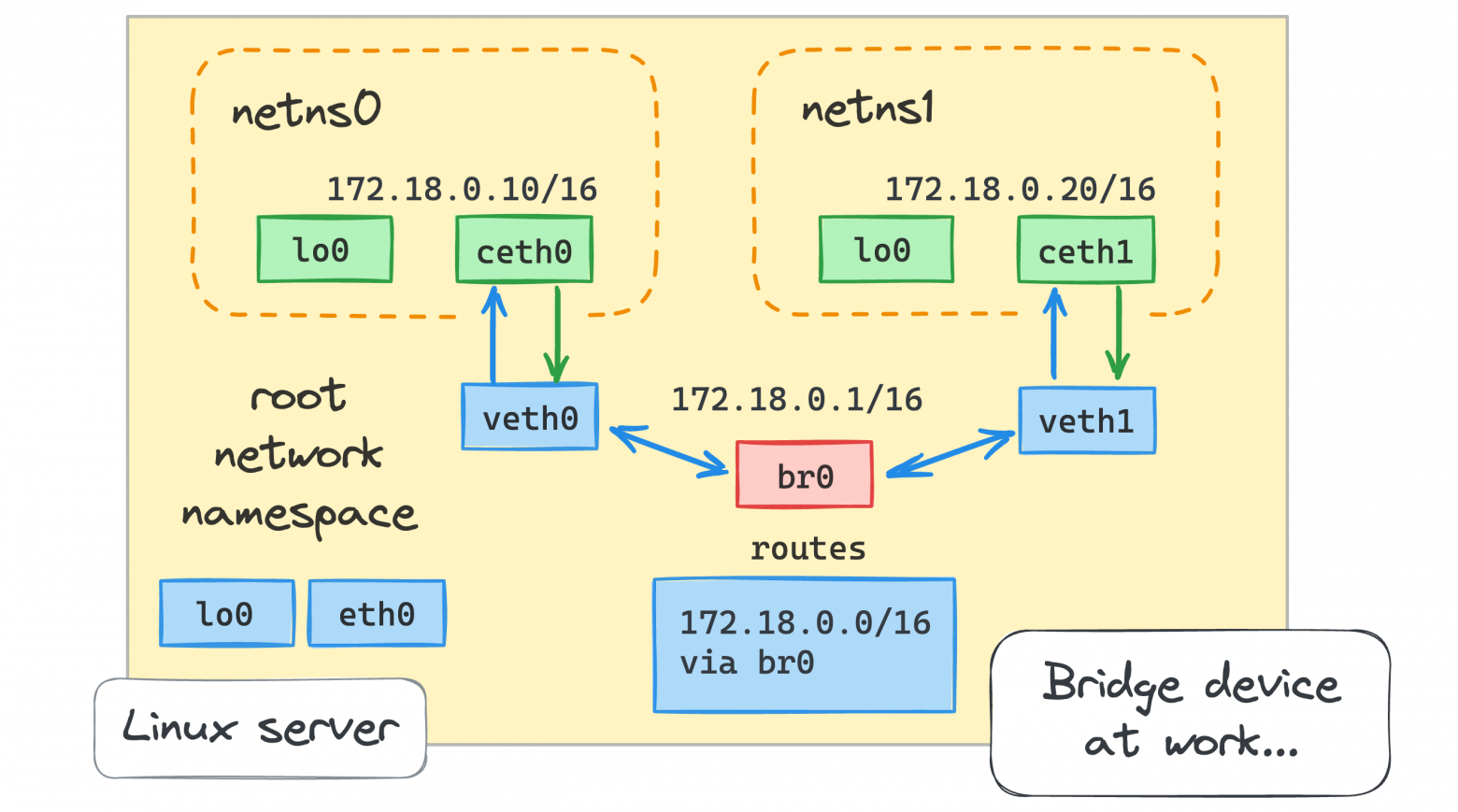
В этой статье мы собираемся разобраться со следующими вопросами:
* Как виртуализировать сетевые ресурсы, чтобы контейнеры думали, что у них есть отдельные сетевые среды?
* Как превратить контейнеры в дружелюбных соседей и научить общаться друг с другом?
* Как выйти во внешний мир (например, в Интернет) изнутри контейнера?
* Как связаться с контейнерами, работающими на хосте Linux, из внешнего мира?
* Как реализовать публикацию портов, подобную Docker?
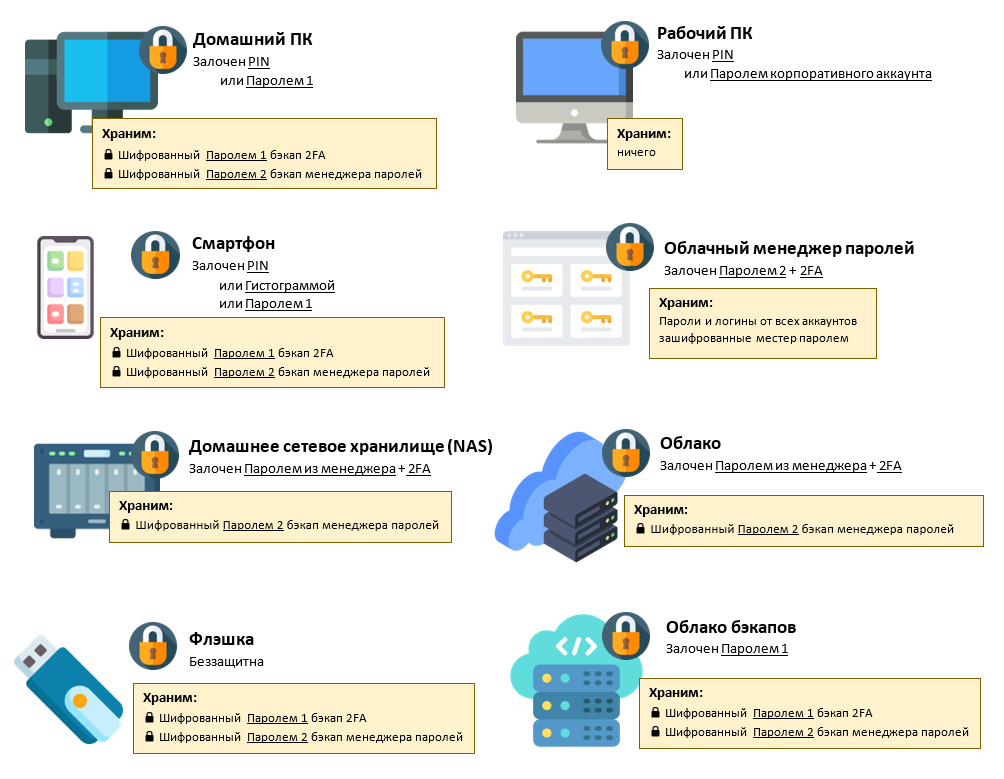
Я долго собирал информацию о том, как организовать свои аккаунты. Как сделать доступ к ним достаточно надёжным и стойким к утере девайсов.
Меня интересовало, как я могу залогиниться туда, где многофакторная авторизация через телефон, в случае потери телефона.
Или, как обезопасить себя от забывания мастер пароля от менеджера паролей? На моей практике я несколько раз забывал пин-код от банковской карты, состоящий из 4-ёх цифр, после ежедневного использования на протяжении многих месяцев. Мозг - странная штука.
В итоге, спустя месяцы изучения темы, я пришёл к следующему сетапу, который решил описать в виде мануала.

Позавчера, 15 января ночью, по всему Рунету пошли сигналы, что протоколы WireGuard/OpenVPN массово «отвалились». Судя по всему, с понедельника Роскомнадзор снова взялся за VPN, экспериментируя с блокировками OpenVPN и Wireguard в новом масштабе.
Мы в Xeovo заметили это по большому наплыву пользователей, которые вообще не знали что протоколы блокируются (где они были все это время). Уже учения были много раз, и мы предупреждали клиентов, но, видимо, OpenVPN и WireGuard до сих пор очень хорошо работали у всех. На настоящий момент блокировка продолжается. Возможно, тестируют, как все работает перед выборами.

О сложных системах простыми словами.
В шпаргалке на высоком уровне рассматриваются такие вещи, как протоколы коммуникации, DevOps, CI/CD, архитектурные паттерны, базы данных, кэширование, микросервисы (и монолиты), платежные системы, Git, облачные сервисы etc. Особую ценность представляют диаграммы — рекомендую уделить им пристальное внимание. Полагаю, шпаргалка будет интересна всем, кто хоть как-то связан с разработкой программного обеспечения и, прежде всего, веб-приложений. Буду признателен за помощь в уточнении/исправлении понятий, терминологии, логики/алгоритмов работы систем (в рамках того, что по этому поводу содержится в оригинале), а также в обнаружении очепяток.
Выражаю благодарность Анне Неустроевой за помощь в редактировании материала.
Возможно, немного другой формат шпаргалки покажется вам более удобным.

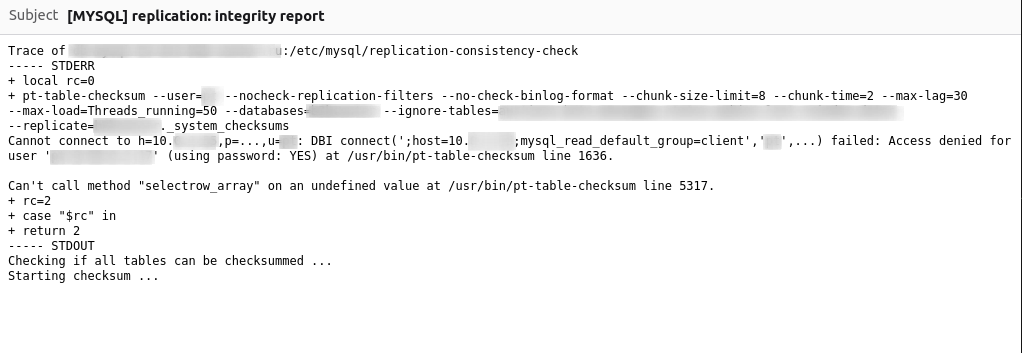
Хочу поделиться с сообществом простым и полезным шаблоном скрипта-обёртки на bash для запуска заданий по cron (а сейчас и systemd timers), который моя команда повсеместно использует много лет.
Сначала пара слов о том зачем это нужно, какие проблемы решает. С самого начала моей работы системным администратором linux, я обнаружил, что cron не очень удобный планировщик задач. При этом практически безальтернативный. Чем больше становился мой парк серверов и виртуальных машин, тем больше я получал абсолютно бесполезных почтовых сообщений "From: Cron Daemon". Задание завершилось с ошибкой - cron напишет об этом. Задание выполнено успешно, но напечатало что-нибудь в STDOUT/STDERR - cron всё равно напишет об этом. При этом даже нельзя отформатировать тему почтового сообщения для удобной автосортировки. Сначала были годы борьбы с использованием разных вариаций из > /dev/null, 2> /dev/null, > /dev/null 2>&1, | mail -E -s '<Subject>' root@.


Привет! Меня зовут Петр и мы в компании Nixys очень любим Redis. Эта база используется, если не на каждом нашем проекте, то на подавляющем большинстве. Мы работали как с разными инсталляциями Redis, так и с разными версиями, вплоть до самых дремучих, вроде 2.2. Несмотря на то, что в Интернете очень много статей и докладов по этой БД, мы в своей практике достаточно часто встречаемся с непониманием некоторых основных концепций Redis и со стороны разработчиков, и со стороны системных администраторов.
В серии статей я попытаюсь осветить неочевидные нюансы при работе с Redis и сегодня начну с основных концепций и понятий. А еще в конце статьи приведу небольшой чек-лист, который может помочь вам в оптимизации этого NoSQL решения.