Всем привет! Я — Никита Колганов из группы компаний «АСНА». Группа компаний «АСНА» — это современная экосистема сервисов и решений для фармацевтического рынка, позволяющая нам развиваться самим и способствовать развитию партнеров.
Зачем мы вообще внедряли BI‑систему?
В компании ежедневно делается множество отчетов, значительная часть которых — средствами Excel. Помимо того, что ручной сбор отчетов занимает массу времени, так и сам Excel, как контейнер доставки отчетности, обладает рядом недостатков. Это, как минимум:
Проблема централизации — в каждом Excel может быть как свой набор исходных данных, так и свои методики расчета;
Проблема доставки — расшарить файл на большое количество участников бывает проблематично. Особенно, если он большой и не пролезает в почту;
Проблема безопасности — непросто ограничить доступ к Excel‑файлу для определенного круга лиц
Отсутствие автоматизации алертов — на уровне Excel сложно настраивать оповещения в почту или корпоративные мессенджеры в случае изменения того или иного показателя.
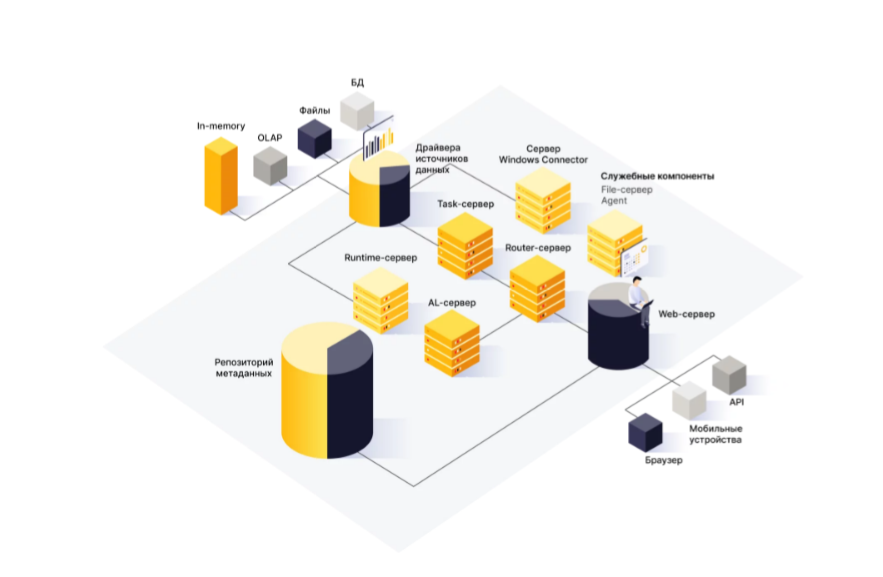
Изначально в качестве BI‑системы мы хотели использовать Tableau и даже успели сделать несколько дашбордов, но случился февраль 2022 года, и Tableau стал недоступен. Вместе с тем, в компании назрела необходимость BI в концепции self‑service.