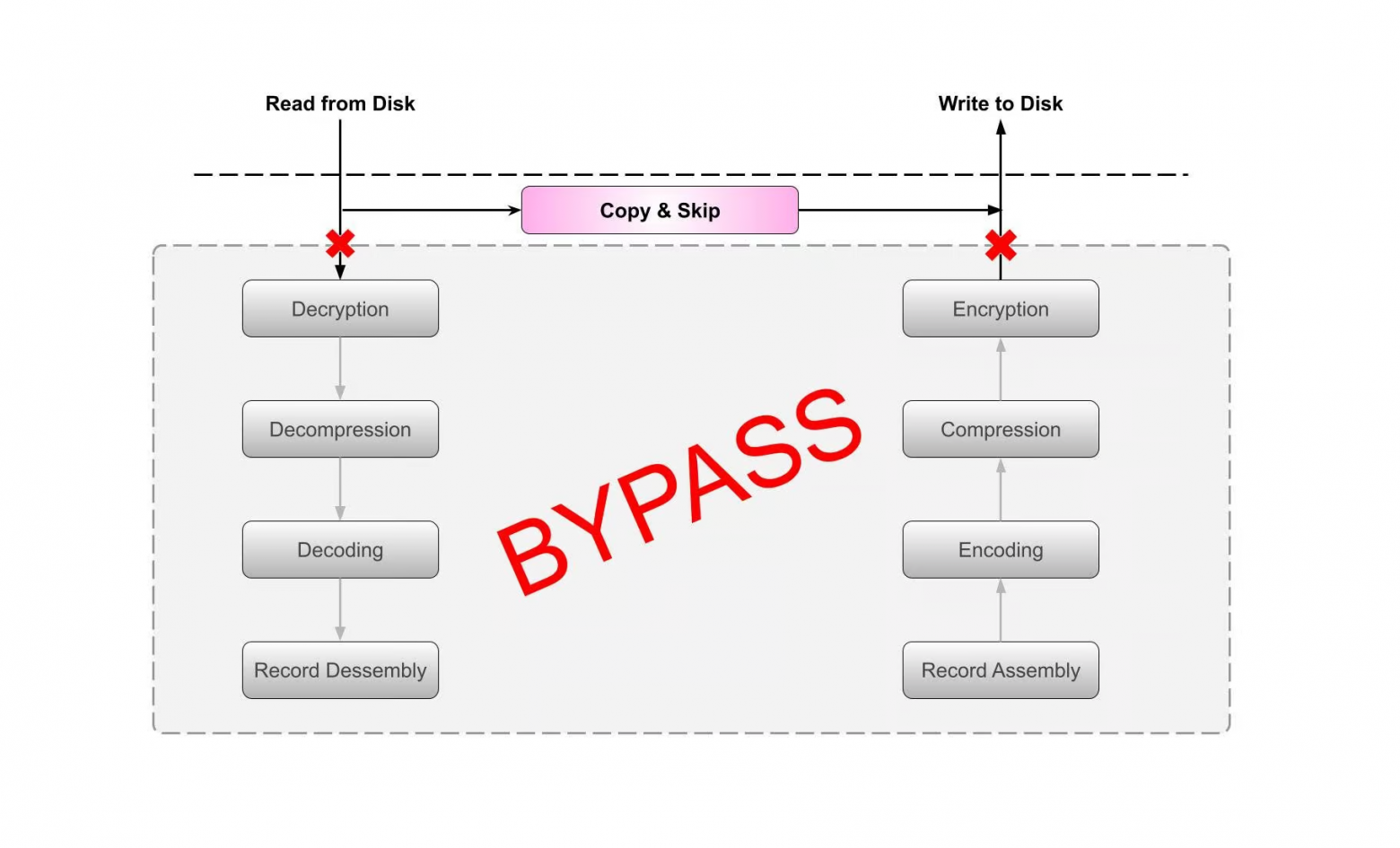
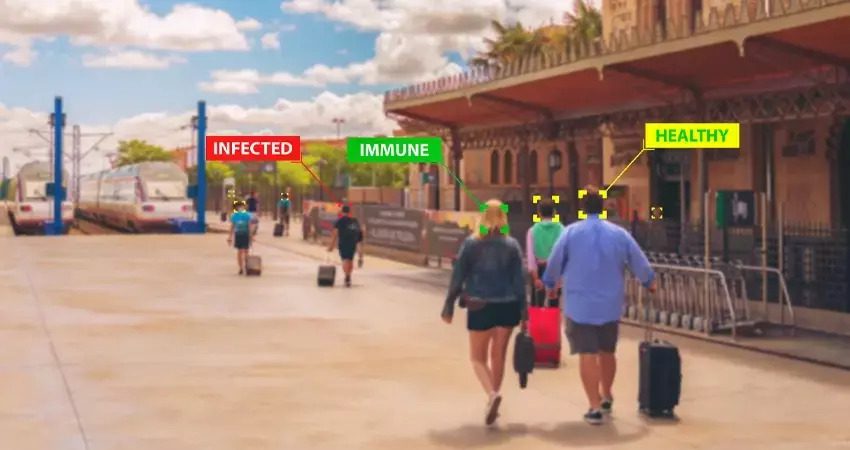
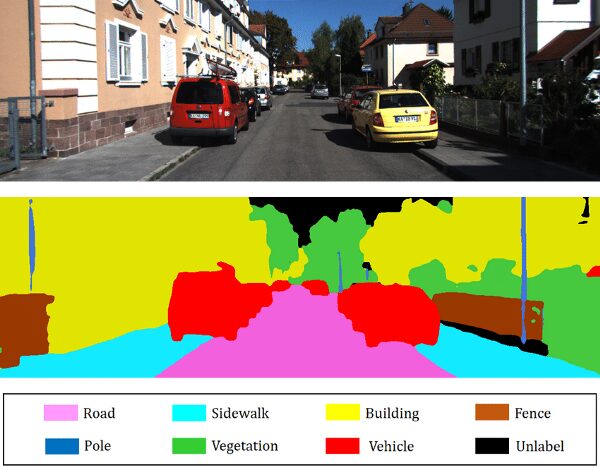
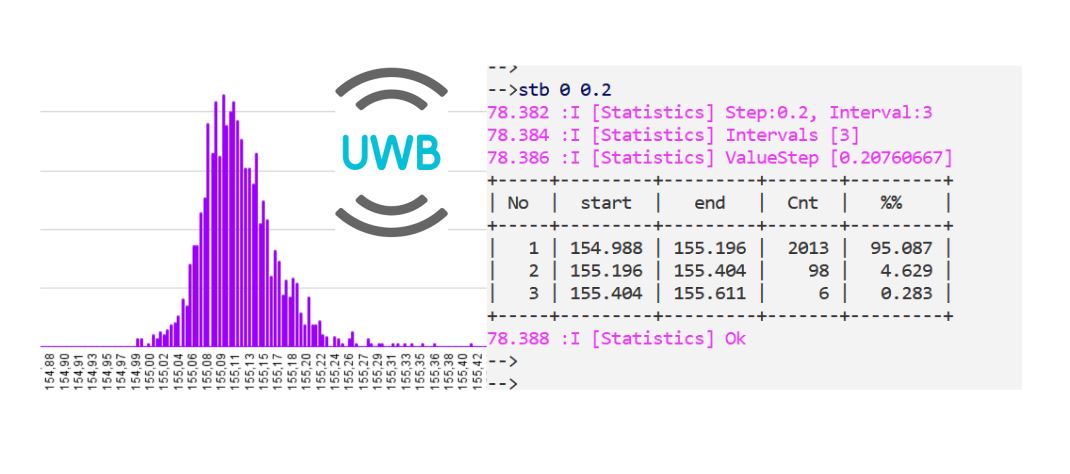
Когда слушаешь доклады на больших ML-конференциях, то часть докладов вызывает восторг, но другая часть на послевкусии вызывает странное чувство. Да, доклад может быть очень крутым, математика блестящей, сложность крышесносной, но что-то как будто бы не так.
Эта статья — развлекательно-философская, все совпадения с реальностью — случайны, персонажи вымышлены, с точкой зрения — можно не соглашаться, но поразмышлять — стоит.
Да при чем здесь вообще деривативы? А просто у деривативов, дженги и машинного обучения — много общего, давайте разбираться.