Мы получили 1022 заявки, приняли из них 918, в шорт‑листы попало более 300 статей. Точной цифры по шорт‑листам нет неслучайно: поскольку наш естественный интеллект это вам не ChatGPT склонен уставать и ошибаться, несколько статей могут попасть в шорты, но, скорее всего, выпадут из них — так, во время подготовки этой статьи выяснилось, что из финала выбыли двое участников, скрывшие свои публикации в черновики.
Вообще, такого «Технотекста», как в этот раз, ещё не было: обычно мы сравнительно легко отсеивали участников и выбирали финалистов, разница в уровне материалов была очевидной. В этот раз номинанты сильные — и многие статьи не вышли в финал не потому, что они какие-то не такие, а потому что они объективно слабее лучших из лучших — но очевидно, что сильнее большей части статей на Хабре. Хотя участники «Технотекста» из года в год находят отличные способы добить нервную систему модераторов конкурса 😃











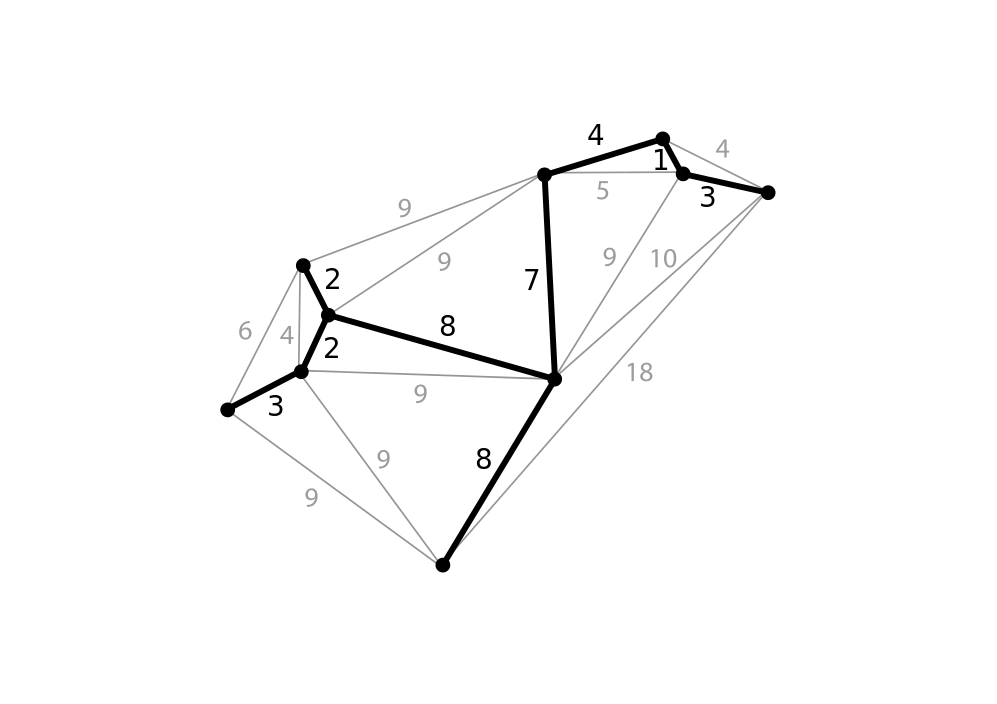
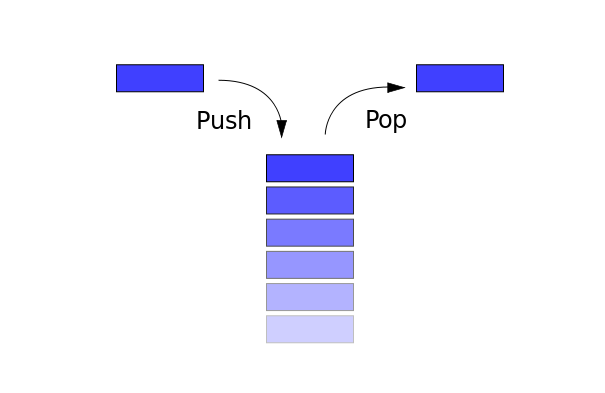
 методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.
методики FAANG — по этой причине практически во всех IT-собесах есть она: секция алгоритмов. Кто-то ей рад, кто-то не очень, но секция есть и уходить пока не планирует. Поэтому нужно закатать рукава и достойно встретить суровую реальность.