Привет, Хабр!
В наше неспокойное время, когда сфера AI стремительно движется вперёд, хочется немного стабильности и уверенности в завтрашнем дне. Как это связано с темой статьи?
Самым прямым образом — алгоритмы прокачивают умение системно мыслить, искать нестандартные пути решения; человека, у которого эти скиллы на высоте, вряд ли заменит ИИ. Так что, тратя бесценное время на алгоритмы, вы занимаетесь очень полезным делом, расслабьтесь и получайте удовольствие) В качестве бонуса к прокачиванию серого вещества вы получите сверхспособность пройти любой алгособес в FAANG и удовлетворить любые потребности пирамиды Маслоу — довольно приятно)
В этой статье мы разберём графовые алгоритмы типо DFS, Флойда–Уоршелла и строковые наподобие Ахо-Корасик.

Это 2 часть разбора самых основных алгоритмов, а вот 1 часть: «Шпаргалка для алгособеса — алгоритмическая сложность, структуры данных, методы сортировки и Дейкстра»
Приведу ещё раз ту схему со всеми основными понятиями, которые могут всплыть на секции "Алгортимы":

Эта схема может помочь вам сориентироваться в теме алгоритмов.
Разбор огромного количества вопросов с собесов и не только в моем канале, вопросы по машинному обучению, а здесь собрана целая папка с каналами для подготовки к собеседованиям.
Кстати, тут буквально на днях вышел дивный поисковик explorer.globe.engineer, он специализируется на поиске по графикам и схемам, а заодно пытается структурировать выдачу — так что можно без проблем нарулить себе неплохие визуализации какого-нибудь алгоритма. Зацените, как круто:

Ладно, поехали уже к алгоритмам!

Графовые алгоритмы
Ниже это у нас простые (без петель и кратных рёбер) неориентированные графы:

Давайте определимся с основными понятиями, мало ли, может кто не в теме:
Путь – последовательность вершин, в которой каждая вершина соединена со следующей вершиной ребром. На Рис. 1 красными стрелками показан путь от вершины 1 к верешине 3 через вершину 4.
Порядок – количество вершин графа.
Размер – количество ребер графа.
Связность (степень связности) вершины – количество ребер, исходящих из этой вершины.
Изолированная вершина – вершина, не связанная с другими вершинами графа.
Цикл (петля) – ребро от вершины к этой же вершине.
Ориентированный граф – граф, в котором все ребра имеют направление, указывающее, какая из вершин ребра является начальной, а какая – конечной.
Неориентированный граф – граф, в котором у ребер нет направлений.
Взвешенный граф – все ребра графа имеют веса.
Невзвешенный граф – ребра графа не имеют весов.

Граф называют ацикличным, если в нем нет простых циклов.
Ацикличный неориентированный граф называется лесом. Связный лес называется деревом. У деревьев есть другие эквивалентные определения:
Граф является деревом, если в нем n вершин и (n−1) ребер и нет циклов.
Граф является деревом, если из любой вершины можно дойти в любую другую единственным образом.
Дерево называется корневым, если у него есть ровно 1 специальная вершина, называемая корнем. Часто подразумевается, что ребра корневого дерева ориентированы так, что от корня можно дойти от всех остальных вершин.
Граф называется планарным, если его можно разложить на плоскости так, чтобы его ребра не пересекались в точках, отличных от вершин. Граф называется двудольным, если его вершины которого можно разделить на два множества таких, что ребра соединяют только вершины из разных множеств.
Этих определений нам пока хватит. Перейдём к основным графовым алгоритмам.

Поиск в ширину (Breadth First Searching)
Визуализация BFS:

Поиск в ширину — один из основных алгоритмов на графах, позволяющий находить все кратчайшие пути от заданной вершины и решать многие другие задачи.
Поиск в ширину также называют обходом — так же, как поиск в глубину и все другие обходы, он посещает все вершины графа по одному разу, но в другом порядке: по увеличению расстояния до начальной вершины.

Алгоритм. На вход подаётся невзвешенный граф и номер стартовой вершины s. Граф может быть как ориентированным, так и неориентированным — для алгоритма это не важно.
Основную идею алгоритма можно понимать как процесс «поджигания» графа: на нулевом шаге мы поджигаем вершину s, а на каждом следующем шаге огонь с каждой уже горящей вершины перекидывается на всех её соседей, в конечном счете поджигая весь граф.
Если моделировать этот процесс, то за каждую итерацию алгоритма будет происходить расширение «кольца огня» в ширину на единицу. Номер шага, на котором вершина v начинает гореть, в точности равен длине её минимального пути из вершины s.

Моделировать это можно так. Создадим очередь, в которую будут помещаться горящие вершины, а также заведём булевый массив, в котором для каждой вершины будем отмечать, горит она или нет — или иными словами, была ли она уже посещена. Изначально в очередь помещается только вершина s, которая сразу помечается горящей.
Затем алгоритм представляет собой такой цикл: пока очередь не пуста, достать из её головы одну вершину v, просмотреть все рёбра, исходящие из этой вершины, и если какие-то из смежных вершин u ещё не горят, поджечь их и поместить в конец очереди.
В итоге, когда очередь опустеет, мы по одному разу обойдём все достижимые из s вершины, причём до каждой дойдём кратчайшим путём. Длины кратчайших путей можно посчитать, если завести для них отдельный массив d и при добавлении в очередь пересчитывать по правилу  . Также можно компактно сохранить дополнительную информацию для восстановления самих путей, заведя массив «предков», в котором для каждой вершины хранится номер вершины из которой мы в неё попали.
. Также можно компактно сохранить дополнительную информацию для восстановления самих путей, заведя массив «предков», в котором для каждой вершины хранится номер вершины из которой мы в неё попали.

Реализовать алгоритм поиска в ширину на Python можно так:
# Смежность вершин
inc = {
1: [2, 8],
2: [1, 3, 8],
3: [2, 4, 8],
4: [3, 7, 9],
5: [6, 7],
6: [5],
7: [4, 5, 8],
8: [1, 2, 3, 7],
9: [4],
}
visited = set() # Посещена ли вершина?
Q = [] # Очередь
BFS = []
# Поиск в ширину BFS
def bfs(v):
if v in visited: # Если вершина уже посещена, выходим
return
visited.add(v) # Посетили вершину v
BFS.append(v) # Запоминаем порядок обхода
for i in inc[v]: # Все смежные с v вершины
if not i in visited:
Q.append(i)
while Q:
bfs(Q.pop(0))
start = 1
bfs(start) # start - начальная вершина обхода
print(BFS) # [1, 2, 8, 3, 7, 4, 5, 9, 6]

Вообще, одно из применений BFS — поиск минимального расстояния между вершинами; можно сравнить, насколько хорошо он подходит для этой задачи по сравнению с другими алгоритмами:


Поиск в глубину (Depth First Searching)
Алгоритм поиска в глубину (DFS) отличается от поиска в ширину более агрессивным продвижением по графу. Он всегда сразу продвигается к самой отдаленной от стартовой ноды вершине и затем, если не может продвинуться дальше, отступает назад.
Как и BFS, DFS помечает ноду каждый раз, как ее обнаруживает. На каждой итерации алгоритм обходит в произвольном порядке ноды, ближайшие к текущей. На первой же найденной вершине алгоритм будет пытаться найти ближайшие ноды к уже разведанной (в этом он отличается от BFS, который исследует ноды, ближайшие к стартовой) и будет делать это на каждой последующей итерации до тех пор, пока не окажется в ноде, из которой ему некуда уйти. Тогда алгоритм отступает назад и пытается продвинуться дальше по другому пути. Алгоритм так же останавливается, когда все доступные ноды будут разведаны.
DFS реализуется на основе стека LIFO (last in, first out, «последним пришёл — первым ушёл»).

DFS алгоритм. Вход: граф  , где
, где  это множество нод, а
это множество нод, а  множество ребер. Стартовая вершина
множество ребер. Стартовая вершина  .
.
Выход: граф  , при условии, что каждая вершина такого графа достижима из s тогда и только тогда, когда она размечена алгоритмом как «разведанная».
, при условии, что каждая вершина такого графа достижима из s тогда и только тогда, когда она размечена алгоритмом как «разведанная».
Алгоритм DFS
пометить s как разведанную вершину, все остальные как неразведанные
определить стек S, инициализированный вершиной s
до тех пор, пока стек S непустой:
удалить вершину сверху стека S, обозначив ее как v
если v не разведана:
пометить v как разведанную
для каждого ребра (v,w) в списке смежности v:
добавить w наверх стека S
Кроме того, алгоритм может быть реализован рекурсивно.

Разберём DFS на примере:

Реализация DFS на Python может выглядеть как-то так:
def dfs(graph, start, visited=None):
if visited is None:
visited = set()
visited.add(start)
for next in graph[start] - visited:
dfs(graph, next, visited)
return visited
graph = {'0': {'1', '2'},
'1': {'0', '3', '4'},
'2': {'0'},
'3': {'1'},
'4': {'2', '3'}}
visited = dfs(graph, '0')
print(visited)
# {'0', '1', '4', '2', '3'}

Задача топологической сортировки (Topological Sorting)

Задача топологической сортировки — как пронумеровать вершины ориентированного графа, чтобы каждое ребро вело из вершины с меньшим номером в вершину с большим номером. Для решения этой задачи можно использовать разные алгоритмы, в частности DFS и алгоритм Кана.
Сразу заметим, что граф с циклом топологически отсортировать не получится — как ни располагай цикл в массиве, все время идти вправо по ребрам цикла не получится. Верно обратное — если цикла нет, то его обязательно можно топологически отсортировать.
Для одного графа может существовать несколько способов топологической сортировки (например когда он несвязный).

Способы топологической сортировки. Заметим, что вершину, из которой не ведет ни одно ребро, можно всегда поставить последней, а такая вершина в ациклическом графе всегда есть (иначе можно было бы идти по обратным рёбрам бесконечно). Из этого сразу следует конструктивное доказательство: будем итеративно класть в массив вершину, из которой ничего не ведет, и убирать ее из графа. После этого процесса массив надо будет развернуть.
Этот алгоритм проще реализовать, обратив внимание на времена выхода вершин в DFS. Вершина, из которой мы выйдем первой — та, у которой нет новых исходящих ребер. Дальше мы будем выходить только из тех вершин, которые если и имеют исходящие ребра, то только в те вершины, из которых мы уже вышли. Следовательно, достаточно просто выписать вершины в порядке выхода из DFS, а затем полученный список развернуть, и мы получим какую-то из корректных топологических сортировок.

Топологическая сортировка на Python на основе DFS.
Итак, сперва увеличим глубину рекурсии.
import sys
sys.setrecursionlimit(10000)
Функция dfs реализует обход в глубину из вершины v.
def dfs(v):
Зашли в вершину v. Делаем ее серой.
used[v] = 1
Перебираем вершины to, в которые можно зайти из v.
for to in g[v]:
Если ориентированное ребро (v, to) ведет в серую вершину, то в графе присутствует цикл. Устанавливаем flag = 1.
if used[to] == 1:
global flag
flag = 1
Если вершина to еще не просмотрена, то рекурсивно запускаем из нее поиск в глубину.
if used[to] == 0:
dfs(to)
Завершаем обработку вершины v. Делаем ее черной и заносим в массив top.
used[v] = 2
top.append(v)
Основная часть программы. Читаем количество вершин n и количество ребер m.
n, m = map(int, input().split())
Входной граф храним в списке смежности g. Обьявим список used.
g = [[] for _ in range(n + 1)]
used = [0] * (n + 1)
Читаем список ребер. Строим список смежности графа.
for _ in range(m):
a, b = map(int, input().split())
g[a].append(b)
Совершаем обход в глубину ориентированного графа.
flag = 0
top = []
for i in range(1, n + 1):
if used[i] == 0: dfs(i)
Если в графе присутствует цикл (при обходе в глубину установлено flag = 1), то выводим -1.
if flag == 1:
print("-1")
else:
Выводим вершины графа в порядке, обратном тому, в котором они заносились в список top.
for i in range(len(top) - 1, -1, -1):
print(top[i], end=" ")
print()

Топологическая сортировка с помощью алгоритма Кана.
Объявим очередь q.
from collections import deque
q = deque()
Читаем количество вершин n и количество ребер m.
n, m = map(int, input().split())
Входной граф храним в списке смежности graph.
Входящие степени вершин храним в списке InDegree.
Топологически отсортированные вершины графа заносим в список top.
graph = [[] for _ in range(n + 1)]
InDegree = [0] * (n + 1)
top = []
Читаем m ребер графа.
for _ in range(m):
a, b = map(int, input().split())
graph[a].append(b)
Для каждого ребра (a, b) увеличим InDegree[b] на 1.
InDegree[b] += 1
Все вершины, входящие степени которых равны нулю, заносим в очередь q.
for i in range(1, len(InDegree)):
if not InDegree[i]: q.append(i)
Продолжаем работу алгоритма, пока очередь q не пуста.
while q:
Извлекаем вершину v из очереди и заносим ее в конец топологического порядка.
v = q.popleft()
top.append(v)
Удаляем из графа ребра (v, to). Для каждого такого ребра уменьшаем входящую степень вершины to.
for to in graph[v]:
InDegree[to] -= 1
Если степень вершины to станет нулевой, то заносим ее в очередь, откуда она прямиком попадет в список топологического порядка.
if not InDegree[to]: q.append(to)
Если в список top занесены не все n вершин, то граф содержит цикл и топологическая сортировка невозможна.
if len(top) < n:
print("-1")
else:
Выводим вершины графа в топологическом порядке.
for i in top:
print(i, end=" ")
print()

Задача раскраски графа
Раскраска графа назначает цвета элементам графа, обеспечивая выполнение определенных условий. Чаще всего используется раскраска вершин, при которой мы пытаемся раскрасить вершины графа, используя k цветов, чтобы соседние вершины никогда не имели один и тот же цвет. Другие виды раскраски включают раскраску ребер и раскраску граней.
Хроматическое число графа – это минимальное количество цветов, необходимое для его раскраски. Тут ниже изображена раскраска вершин графа 4 цветами.
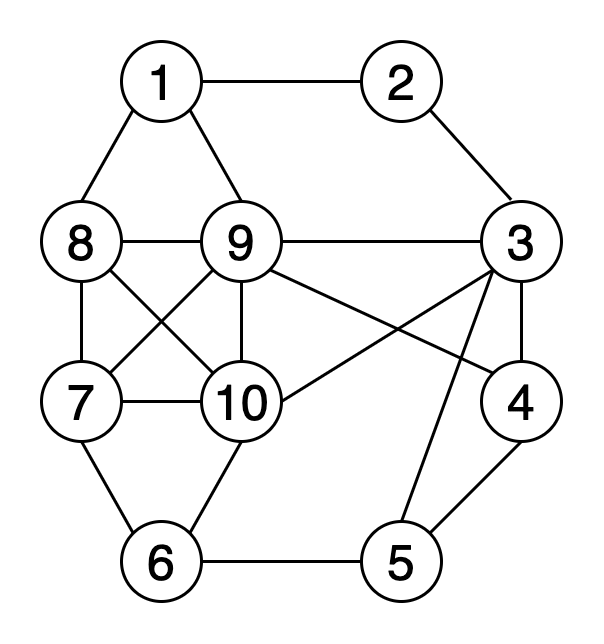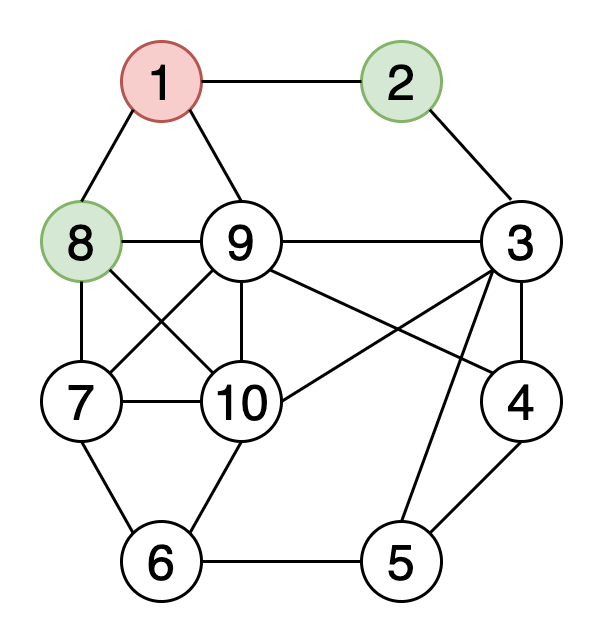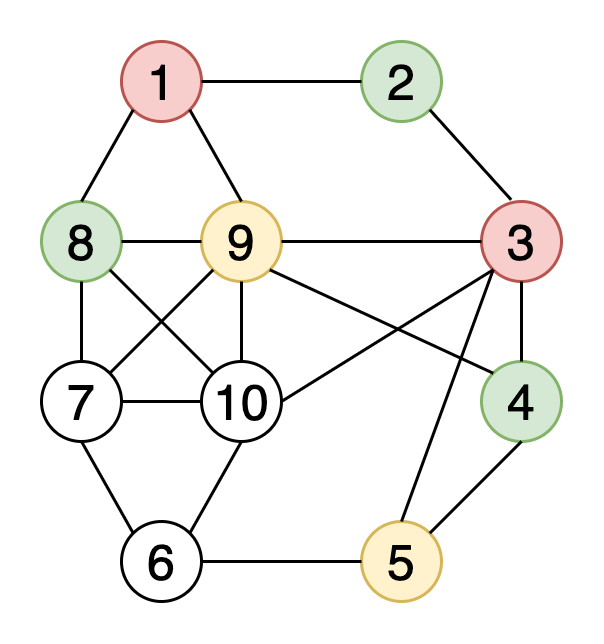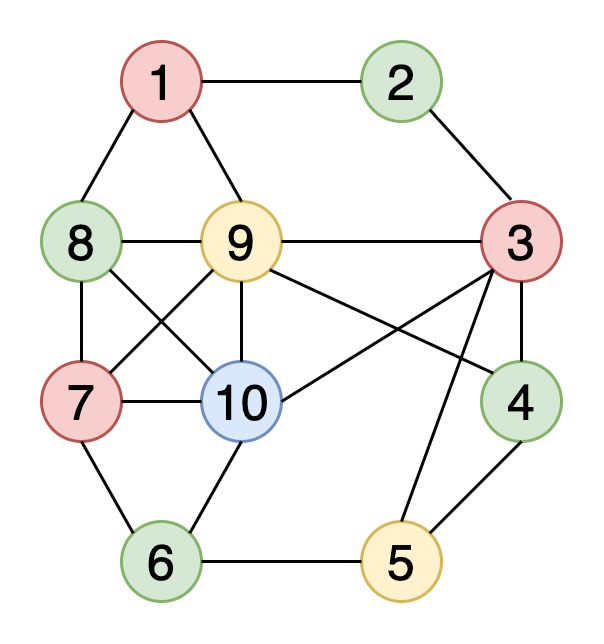
Алгоритмы, используемые для раскраски:
Алгоритмы, использующие поиск в ширину или в глубину.
"Жадная" раскраска.

Раскраска графов используется:
для составления расписаний;
для назначения радиочастот мобильным сетям;
для моделирования и решения игр вроде судоку;
для проверки, является ли граф двучастным;
для раскраски географических карт, чтобы соседние страны всегда имели разные цвета.

Алгоритм Беллмана-Форда (Bellman Ford's Algorithm)

Алгоритм Форда-Беллмана позволяет найти кратчайшие пути из одной вершины графа до всех остальных, даже для графов, в которых веса ребер могут быть отрицательными. Тем не менее, в графе не должно быть циклов отрицательного веса, достижимых из начальной вершины, иначе вопрос о кратчайших путях является бессмысленным. При этом алгоритм Форда-Беллмана позволяет определить наличие циклов отрицательного веса, достижимых из начальной вершины.
Алгоритм Беллмана-Форда можно описать так:

Алгоритм использует динамическое программирование. Введем F:
F[k][i] — длина кратчайшего пути из начальной вершины до вершины i, содержащего не более k ребер.
Начальные значения зададим для случая k=0. В этом случае F[0][start] = 0, а для всех остальных вершин i F[0][i] = INF, то есть путь, состоящий из нуля ребер существует только от вершины start до вершины start, а до остальных вершин пути из нуля ребер не существует, что будем отмечать значением INF.
Далее будем вычислять значения функции F увеличивая число ребер в пути k, то есть вычислим кратчайшие пути, содержащие не более 1 ребра, кратчайшие пути, содержащие не более 2 ребер и т. д. Если в графе нет циклов отрицательного веса, то кратчайший путь между любыми двумя вершинами содержит не более n-1 ребра (n - число вершин в графе), поэтому нужно вычислить значения F[n-1][i], которые и будут длинами кратчайших путей от вершины start до вершины i).
Рассмотрим, как вычисляется значение F[k][i]. Пусть есть кратчайший маршрут из вершины start до вершины i, содержащий не более k ребер. Пусть последнее ребро этого маршрута есть ребро j-i. Тогда путь до вершины j содержит не более k-1 ребра и является кратчайшим путем из всех таких путей, значит, его длина равна F[k-1][j], а длина пути до вершины i равна F[k-1][j] + W[j][i], где W[j][i] есть вес ребра j-i. Дальше необходимо перебрать все вершины j, которые могут выступать в качестве предыдущих, и выбрать минимальное значение F[k-1][j] + W[j][i].
Получаем следующий алгоритм:
INF = 10 ** 9
F = [[INF] * N for i in range(N)]
F[0][start] = 0
for k in range(1, N):
for i in range(N):
F[k][i] = F[k - 1][i]
for j in range(N):
if F[k - 1][j] + W[j][i] < F[k][i]:
F[k][i] = F[k - 1][j] + W[j][i]
Очевидно, что сложность такого алгоритма O(n^3).
Теперь модифицируем этот алгоритм. Прежде всего, сделаем массив F одномерным - «склеим» значения F[k][i] для разных значений k, будем хранить в массиве F[i] кратчайшее известное расстояние до вершины i, улучшая его по ходу. Получим следующий код:
INF = 10 ** 9
F = [INF] * N
F[start] = 0
for k in range(1, N):
for i in range(N):
for j in range(N):
if F[j] + W[j][i] < F[i]:
F[i] = F[j] + W[j][i]
Последние две строчки есть ни что иное, как релаксация ребра j-i, как это делается в алгоритме Дейкстры. А два последних цикла по вершинам j и i с релаксацией ребра j-i просто являются релаксацией всех ребер в графе. Но если граф «разреженный», то его удобно хранить не в виде матрицы смежности, а в виде списков смежности, тогда перебор всех ребер в графе можно осуществить быстрее, чем перебирая все пары вершин.

Кстати, вот годная хабростатья о применении алгоритма Беллмана-Форда в арбитражной торговле.

Алгоритм Флойда-Уоршелла (Floyd-Warshall Algorithm)
Алгоритм Флойда–Уоршелла — алгоритм нахождения длин кратчайших путей между всеми парами вершин во взвешенном ориентированном графе. Работает корректно, если в графе нет циклов отрицательной величины, а в случае, когда такой цикл есть, позволяет найти хотя бы один такой цикл. Алгоритм работает за O(n^3) времени и использует O(n^2) памяти.
Пример работы такого алгоритма:


Реализация на Python очень проста:
A = [[[INF for j in range(n)] for i in range(n)] for k in range(n + 1)]
for i in range(n):
for j in range(n):
A[0][i][j] = W[i][j]
for k in range(1, n + 1):
for i in range(n):
for j in range(n):
A[k][i][j] = min(A[k-1][i][j], A[k-1][i][k-1] + A[k-1][k-1][j])
Внешний цикл в этом алгоритме последовательно перебирает все вершины, затем пытается улучшить пути из i в j, разрешив им проходить через выбранную вершину.
Упростим этот алгоритм, избавившись от «трехмерности» массива A: будем только хранить значение кратчайшего пути из i в j в A[i][j], а при улучшении пути будем записать новую длину пути также в A[i][j]. Также изменим определение цикла по переменной k, заменив значение k-1 на k. Получается так:
A = [[W[i][j] for j in range(n)] for i in range(n)]
for k in range(n):
for i in range(n):
for j in range(n):
A[i][j] = min(A[i][j], A[i][k] + A[k][j])

Алгоритм Прима (Prim's Algorithm)

Алгоритм Прима — алгоритм построения минимального остовного дерева взвешенного связного неориентированного графа. Был открыт Ярником, потом переоткрыт Примом и Дейкстрой, но большинству известен именно как алгоритм Прима.
Похож на алгоритм Дейкстры для нахождения путей из одной вершины. Здесь дерево строится, начиная с произвольно выбранной начальной вершины. Текущее подмножество — всегда дерево. На каждом шаге к дереву добавляется ребро из одной из уже имеющихся в нём вершин в некоторую ещё не задействованную вершину — короче, такое ребро, которое не приведёт к образованию цикла. Из всех возможных рёбер выбирается ребро с наименьшим весом.
Структура данных: очередь с приоритетами, в которой хранятся все вершины, ещё не попавшие в дерево. Значение каждой вершины — это наименьший вес ребра, соединяющий её с деревом. Выполняется |V| итераций внешнего цикла. Операции над очередью с приоритетами — log |V|. Внутренний цикл по v: за всё время работы алгоритма выполняется 2|E| итераций, а внутри — операция над очередью с приоритетами, log |V|. Время: |E| log |V|.
Алгоритм можно описать так:

Реализация алгоритма Прима на Python:
import math
def get_min(R, U):
rm = (math.inf, -1, -1)
for v in U:
rr = min(R, key=lambda x: x[0] if (x[1] == v or x[2] == v) and (x[1] not in U or x[2] not in U) else math.inf)
if rm[0] > rr[0]:
rm = rr
return rm
# список ребер графа (длина, вершина 1, вершина 2)
# первое значение возвращается, если нет минимальных ребер
R = [(math.inf, -1, -1), (13, 1, 2), (18, 1, 3), (17, 1, 4), (14, 1, 5), (22, 1, 6),
(26, 2, 3), (19, 2, 5), (30, 3, 4), (22, 4, 6)]
N = 6 # число вершин в графе
U = {1} # множество соединенных вершин
T = [] # список ребер остова
while len(U) < N:
r = get_min(R, U) # ребро с минимальным весом
if r[0] == math.inf: # если ребер нет, то остов построен
break
T.append(r) # добавляем ребро в остов
U.add(r[1]) # добавляем вершины в множество U
U.add(r[2])
print(T)
# [(13, 1, 2), (14, 1, 5), (17, 1, 4), (18, 1, 3), (22, 1, 6)]

Алгоритм Краскала (Kruskal's Algorithm)
Алгоритм Краскала можно описать так:


Алгоритм Краскала — это алгоритм поиска минимального остовного дерева (minimum spanning tree, MST) во взвешенном неориентированном связном графе.
(minimum spanning tree, MST) во взвешенном неориентированном связном графе.
 остовным деревом графа называется дерево, которое можно получить из него путём удаления некоторых рёбер. У графа может существовать несколько остовных деревьев, и чаще всех их достаточно много.
остовным деревом графа называется дерево, которое можно получить из него путём удаления некоторых рёбер. У графа может существовать несколько остовных деревьев, и чаще всех их достаточно много.

Вот, например, одно из остовных деревьев (рёбра выделены синим цветом) решёткообразного графа.

Для взвешенных графов существует понятие веса остовного дерева, которое определено как сумма весов всех рёбер, входящих в остовное дерево. Из него натурально вытекает понятие минимального остовного дерева — остовного дерева с минимальным возможным весом.

Для нахождения минимального остовного дерева графа существуют два основных алгоритма: алгоритм Прима и алгоритм Краскала. Они оба имеют сложность O(M log(N)), поэтому выбор одного из них зависит от ваших личных предпочтений.

Ещё одна визуализация работы алгоритма Краскала:

А вот действия по шагам:

Реализовать алгоритма Краскала на Python можно так, например:
# список ребер графа (длина, вершина 1, вершина 2)
R = [(13, 1, 2), (18, 1, 3), (17, 1, 4), (14, 1, 5), (22, 1, 6),
(26, 2, 3), (22, 2, 5), (3, 3, 4), (19, 4, 6)]
Rs = sorted(R, key=lambda x: x[0])
U = set() # список соединенных вершин
D = {} # словарь списка изолированных групп вершин
T = [] # список ребер остова
for r in Rs:
if r[1] not in U or r[2] not in U: # проверка для исключения циклов в остове
if r[1] not in U and r[2] not in U: # если обе вершины не соединены, то
D[r[1]] = [r[1], r[2]] # формируем в словаре ключ с номерами вершин
D[r[2]] = D[r[1]] # и связываем их с одними и теми же вершинами
else: # иначе
if not D.get(r[1]): # если в словаре нет первой вершины, то
D[r[2]].append(r[1]) # добавляем в список первую вершину
D[r[1]] = D[r[2]] # и добавляем ключ с номером первой вершины
else:
D[r[1]].append(r[2]) # иначе, все то же самое делаем со 2 вершиной
D[r[2]] = D[r[1]]
T.append(r) # добавляем ребро в остов
U.add(r[1]) # добавляем вершины в множество U
U.add(r[2])
for r in Rs: # проходим по ребрам второй раз и объединяем разрозненные группы вершин
if r[2] not in D[r[1]]: # если вершины принадлежат разным группам, то объединяем
T.append(r) # добавляем ребро в остов
gr1 = D[r[1]]
D[r[1]] += D[r[2]] # объединем списки двух групп вершин
D[r[2]] += gr1
print(T)
# [(3, 3, 4), (13, 1, 2), (14, 1, 5), (19, 4, 6), (17, 1, 4)]

Алгоритм Косараджу (Kosaraju's Algorithm)
Алгоритм Косараджу — алгоритм поиска областей сильной связности в ориентированном графе.

Пример работы алгоритма Косараджу пошагово. Дан следующий граф:
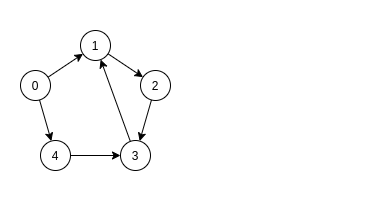
Шаг 1. Непомеченные вершины имеют метку '?' Справа от исходного графа находится лес DFS. Стартовая вершина выбирается в порядке возрастания индексов.
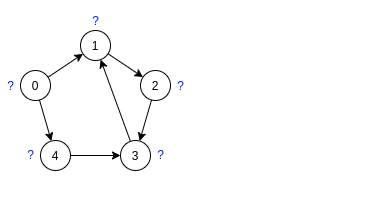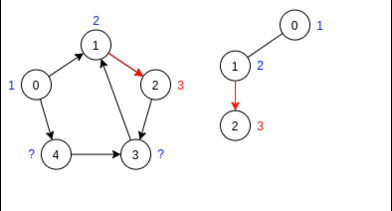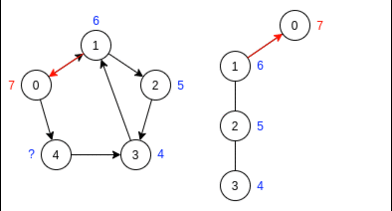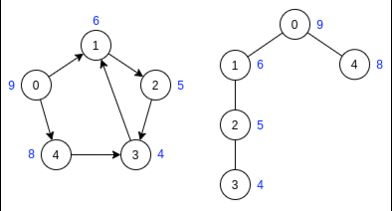
Шаг 2. Инвертируем рёбра

Шаг 3. Выбираем стартовую вершину в порядке убывания меток. Так как теперь нам интересен лишь лес тактов DFS, то нет смысла считать время выхода из вершин, поэтому я не показал рекурсивных переходов.
Справа от инвертированного графа показан лес тактов DFS.
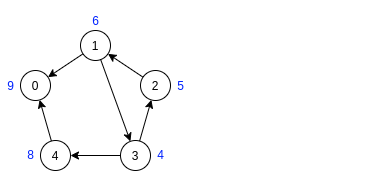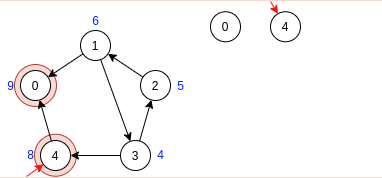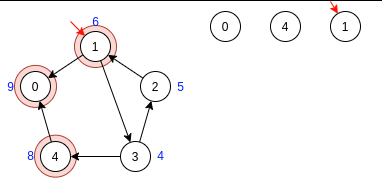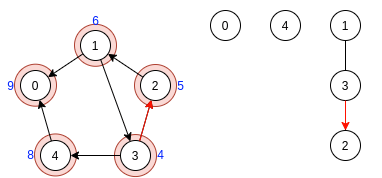
Готово. После завершения алгоритма имеем 3 компоненты сильной связности.
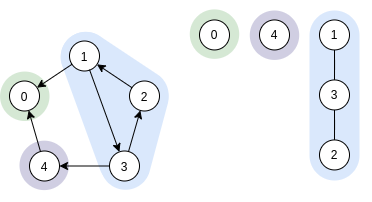
Имплементация алгоритма Косараджу на Python может выглядеть так:
class Graph:
def __init__(self, edge_list, num_nodes):
self.graph = edge_list
self.rev_graph = self.reverse_graph()
self.num_nodes = num_nodes
self.traversed_nodes_p1 = []
self.traversed_nodes_p2 = []
self.counter = 0;
self.scc_size_list = []
self.scc_sl()
def reverse_graph(self):
r_graph = [];
for e in self.graph:
tail = e[0];
head = e[1];
r_graph.append([head, tail])
r_graph = sorted(r_graph, key = lambda x: x[0])
return r_graph
def dfs_p1(self, starting_node, g, t_nodes):
if (starting_node not in t_nodes):
t_nodes.insert(0, starting_node)
for i in range (len(g)):
if (g[i][0] == starting_node and g[i][1] not in t_nodes):
self.dfs_p1(g[i][1], g, t_nodes)
def dfs_loop_p1 (self):
for i in range (1, self.num_nodes+1):
self.dfs_p1(i, self.rev_graph, self.traversed_nodes_p1)
def dfs_p2(self, starting_node, g, t_nodes):
if (starting_node not in t_nodes):
self.counter += 1
t_nodes.append(starting_node)
for i in range (len(g)):
if (g[i][0] == starting_node and g[i][1] not in t_nodes):
self.dfs_p2(g[i][1], g, t_nodes)
def dfs_loop_p2 (self):
for i in self.traversed_nodes_p1:
self.counter = 0
self.dfs_p2(i, self.graph, self.traversed_nodes_p2)
if self.counter > 0:
self.scc_size_list.append(self.counter)
def scc_sl (self):
self.dfs_loop_p1()
self.dfs_loop_p2()
self.scc_size_list.sort()
self.scc_size_list.reverse()
test_edge_list = [[1,2], [1,9], [2,3], [2,8], [3,4], [3,5], [4,5], [6,5], [6,8], [7,6], [7,9], [8,3], [8,7], [9,2], [9,8]]
test = Graph(test_edge_list, 9)
print(test.scc_size_list)
# [5, 1, 1, 1, 1]

Строковые алгоритмы
Задача поиска подстроки
Сравнение разных алгоритмов поиска подстроки (подробнее здесь)

Важность задачи поиска подстроки очевидна — это неотъемлемый компонент поисковых движков, СУБД, текстовых редакторов и ещё много чего. В некоторых областях это одна из базовых задач, скажем, в биоинформатике.

Давайте же рассмотрим некоторые алгоритмы поиска подстроки.

Алгоритм Кнута-Морриса-Пратта

Алгоритм Кнута-Морриса-Пратта (КМП) — эффективный алгоритм, осуществляющий поиск подстроки в строке. Время работы алгоритма линейно зависит от объёма входных данных.

КМП-алгоритм основывается на том соображении, что после частичного совпадения начальной части подстроки с соответствующими символами текста фактически известна пройденная часть текста и можно “вычислить” некоторые сведения (на основе самой подстроки), с помощью которых потом можно быстро продвинуться по тексту.
Основным отличием КМП-алгоритма от алгоритма прямого поиска является осуществления сдвига слова не на один символ на каждом шаге алгоритма, а на некоторое переменное количество символов. Таким образом, перед тем как осуществлять очередной сдвиг, необходимо определить величину сдвига. Для повышения эффективности алгоритма необходимо, чтобы сдвиг на каждом шаге был бы как можно большим.
Если j определяет позицию в подстроке W, содержащую первый несовпадающий символ (как в алгоритме прямого поиска), то величина сдвига определяется как j-LPS. Значение LPS определяется как размер самой длинной последовательности символов слова, непосредственно предшествующих позиции j, которая полностью совпадает с началом подстроки. LPS зависит только от подстроки и не зависит от текста. Для каждого j будет своя величина LPS.
Так как величины LPS зависят только от подстроки W, то перед началом фактического поиска нужно вычислить вспомогательный массив из отдельных LPS вот так:

После вычисления LPS-массива для подстроки W можно перейти к непосредственному поиску W в тексте:

Общая временная сложность для алгоритма KMP составляет O(n+m), где n - длина текста T, а m - длина слова W. Это связано с тем, что для каждого поиска KMP мы сначала вычисляем массив LPS, а затем выполняем процесс поиска KMP.

Пример. Предположим, что текст T равен aaaab, а слово W равно aab. Сначала давайте взглянем на таблицу LPS для слова W.

...и на результат применения алгоритма поиска KMP к заданному тексту.

Как мы видим, на 3 и 4 этапах алгоритм использовал LPS массив для установки j в правильное положение. Следовательно, алгоритму не нужно было начинать сопоставление слова W с самого начала, когда было обнаружено несоответствие. Это помогло алгоритму эффективно найти вхождение слова W на последнем шаге.

Ок, с принципами работы КМП разобрались, а вот так может выглядеть его реализация на Python:
# Префикс-функция для КМП
def pref_func(x):
# Инициализация массива-результата длиной X
res = [0] * len(x)
i = 0
j = -1
res[0] = -1
# Вычисление префикс-функции
while i < len(x) - 1:
while j >= 0 and x[j] != x[i]:
j = res[j]
i += 1
j += 1
if x[i] == x[j]:
res[i] = res[j]
else:
res[i] = j
return res # Возвращение префикс-функции
# Функция поиска алгоритмом КМП
def kmp(x, s):
nom = "" # Объявление строки с номерами позиций
if len(x) > len(s):
return nom # Возвращает 0 поиск если образец больше исходной строки
# Вызов префикс-функции
d = pref_func(x)
i = 0
while i < len(s):
j = 0
while i < len(s) and j < len(x):
if x[j] != s[i]:
j = d[j]
i += 1
j += 1
if j == len(x):
nom += str(i - j) + ", "
if nom != "":
nom = nom[:-2] # Удаление последней запятой и пробела
return nom # Возвращение результата поиска
В тему, вот подробная лекция по КМП от Александра Охотина. И вот, годное видео, очень понятно всё объясняется.

Алгоритм Ахо-Корасик
Алгоритм Ахо-Корасик реализует эффективный поиск всех вхождений всех строк-образцов в заданную строку. Этот алгоритм используется в разных утилитах и приложениях, например, в grep.
Ахо-Корасик строит конечный автомат, которому затем передаёт строку поиска. Автомат получает по очереди все символы строки и переходит по соответствующим рёбрам. Если автомат пришёл в конечное состояние, то соответствующая строка словаря присутствует в строке поиска.
Тут ниже недетерминированный автомат для словаря {a, ab, bc, bca, c, caa}. Серые вершины промежуточные, белые конечные. Синие стрелки — суффиксные ссылки, зелёные — конечные.

Реализация Ахо-Корасик на Python может выглядеть так, в принципе, тут из кода кристально ясно, как работает алгоритм:
class AhoNode:
''' Вспомогательный класс для построения дерева'''
def __init__(self):
self.goto = {}
self.out = []
self.fail = None
def aho_create_forest(patterns):
'''Создать бор - дерево паттернов'''
root = AhoNode()
for path in patterns:
node = root
for symbol in path:
node = node.goto.setdefault(symbol, AhoNode())
node.out.append(path)
return root
def aho_create_statemachine(patterns):
'''Создать автомат Ахо-Корасика.
Фактически создает бор и инициализирует fail-функции
всех узлов, обходя дерево в ширину.'''
# Создаем бор, инициализируем непосредственных потомков корневого узла
root = aho_create_forest(patterns)
queue = []
for node in root.goto.itervalues():
queue.append(node)
node.fail = root
# Инициализируем остальные узлы:
# 1. Берем очередной узел (важно, что проход в ширину)
# 2. Находим самую длинную суффиксную ссылку для этой вершины - это и будет fail-функция
# 3. Если таковой не нашлось - устанавливаем fail-функцию в корневой узел
while len(queue) > 0:
rnode = queue.pop(0)
for key, unode in rnode.goto.iteritems():
queue.append(unode)
fnode = rnode.fail
while fnode is not None and key not in fnode.goto:
fnode = fnode.fail
unode.fail = fnode.goto[key] if fnode else root
unode.out += unode.fail.out
return root
def aho_find_all(s, root, callback):
'''Находит все возможные подстроки из набора паттернов в строке.'''
node = root
for i in xrange(len(s)):
while node is not None and s[i] not in node.goto:
node = node.fail
if node is None:
node = root
continue
node = node.goto[s[i]]
for pattern in node.out:
callback(i - len(pattern) + 1, pattern)
# И вот так это работает
def on_occurence(pos, patterns):
print "At pos %s found pattern: %s" % (pos, patterns)
patterns = ['a', 'ab', 'abc', 'bc', 'c', 'cba']
s = "abcba"
root = aho_create_statemachine(patterns)
aho_find_all(s, root, on_occurence)
# At pos 0 found pattern: a
# At pos 0 found pattern: ab
# At pos 0 found pattern: abc
# At pos 1 found pattern: bc
# At pos 2 found pattern: c
# At pos 2 found pattern: cba
# At pos 4 found pattern: a
By the way, вот неплохая лекция от ВШЭ по этому алгоритму.
А вот здесь можно построить конечный автомат Ахо-Корасик для каких-то подстрок, зацените:


Алгоритм кодирования Хаффмана
Кстати, пару месяцев назад вышла хабростатья «Ещё раз про алгоритм сжатия Хаффмана» — там детально поясняется, что есть что.

Алгоритм Хаффмана — жадный алгоритм оптимального префиксного кодирования алфавита с минимальной избыточностью.
Идея, положенная в основу кодировании Хаффмана, основана на частоте появления символа в последовательности. Символ, который встречается в последовательности чаще всего, получает новый очень маленький код, а символ, который встречается реже всего, получает, наоборот, очень длинный код.
Коды Хаффмана обладают свойством префиксности (т. е. ни одно кодовое слово не является префиксом другого), что позволяет однозначно их декодировать.
Классический алгоритм Хаффмана на входе получает таблицу частот встречаемости символов в сообщении. Далее на основании этой таблицы строится дерево кодирования Хаффмана (Н-дерево).
Символы входного алфавита образуют список свободных узлов. Каждый лист имеет вес, который может быть равен либо вероятности, либо количеству вхождений символа в сжимаемое сообщение.
Выбираются два свободных узла дерева с наименьшими весами.
Создается их родитель с весом, равным их суммарному весу.
Родитель добавляется в список свободных узлов, а два его потомка удаляются из этого списка.
Одной дуге, выходящей из родителя, ставится в соответствие бит 1, другой — бит 0.
Шаги, начиная со второго, повторяются до тех пор, пока в списке свободных узлов не останется только один свободный узел. Он и будет считаться корнем дерева.
Этот процесс можно представить как построение дерева, корень которого — символ с суммой вероятностей объединенных символов, получившийся при объединении символов из последнего шага, его n0 потомков — символы из предыдущего шага и т. д.
Чтобы определить код для каждого из символов, входящих в сообщение, мы должны пройти путь от корня до листа дерева, соответствующего текущему символу, накапливая биты при перемещении по ветвям дерева (первая ветвь в пути соответствует младшему биту). Полученная таким образом последовательность битов является кодом данного символа, записанным в обратном порядке.

Реализация алгоритма Хаффмана на Python может выглядеть так:
import heapq # для работы с мин. кучей из стандартной библиотеки
from collections import Counter # словарь, для каждого объекта поддерживается счетчик
from collections import namedtuple # классы для хранения информации о структуре дерева
class Node(namedtuple("Node", ["left", "right"])): # класс для ветвей - внутренних узлов
def walk(self, code, acc):
# чтобы обойти дерево нам нужно:
self.left.walk(code, acc + "0") # пойти в левого потомка, к префиксу +"0"
self.right.walk(code, acc + "1") # пойти в правого п., к префиксу +"1"
class Leaf(namedtuple("Leaf", ["char"])): # класс для листьев дерева без потомков
def walk(self, code, acc):
code[self.char] = acc or "0"
def huffman_encode(s): # кодирование в коды Хаффмана
h = [] # очередь с приоритетами
for ch, freq in Counter(s).items(): # счетчик, уникальный для всех листьев
h.append((freq, len(h), Leaf(ch))) # частота символа, счетчик, символ
heapq.heapify(h) # очередь с приоритетами
count = len(h) # счетчик длиной очереди
while len(h) > 1: # пока есть хотя бы 2 элемента
freq1, _count1, left = heapq.heappop(h) # с минимальной частотой - левый узел
freq2, _count2, right = heapq.heappop(h) # следующий с минимальной ч. - правый
# поместим новый элемент, у которого частота = сумме частот вытащенных элементов
heapq.heappush(h, (freq1 + freq2, count,
Node(left, right))) # добавим новый внутренний узел
count += 1
code = {} # словарь кодов символов
if h: # если строка пустая, то очередь тоже
[(_freq, _count, root)] = h
root.walk(code, "") # обойдем дерева от корня и заполним словарь
return code # словарь символов и кодов
def main():
s = input() # читаем строку длиной до 10**4
code = huffman_encode(s) # кодируем строку
encoded = "".join(code[ch] for ch in s) # закодированная версия
# конкатенируем результат
print(len(code), len(encoded)) # число символов и длина кода
for ch in sorted(code):
print("{}: {}".format(ch, code[ch])) # символ и его код
print(encoded)
if __name__ == "__main__":
main()
Теперь можем выполнить проверку нашего алгоритма, для этого напишем функцию декодирования строки и функцию тестирования. В функции тестирования будем генерировать строку произвольных символов произвольной длины.
def huffman_decode(encoded, code): # функция декодирования по кодам Хаффмана
sx =[] # массив символов раскодированной строки
enc_ch = "" # значение закодированного символа
for ch in encoded: # обход закодированной строки по символам
enc_ch += ch # добавим текущий символ к строке кода
for dec_ch in code: # ищем закодированный символ в словаре кодов
if code.get(dec_ch) == enc_ch: # если закодированный символ найден,
sx.append(dec_ch) # значение раскодированного + к массиву строки
enc_ch = "" # обнулим значение закодированного символа
break
return "".join(sx) # вернем значение раскодированной строки
def test(n_iter=100): # добавим тест для проверки алгоритма
import random # нам понадобится генератор случайных чисел
import string # string - чтобы получить значения символов по их коду
# строка из ascii-символов
for i in range(n_iter): # краевые случаи
length = random.randint(0, 32) # код символа
s = "".join(random.choice(string.ascii_letters) \
for _ in range(length)) # символ по коду, + к строке
code = huffman_encode(s) # кодирование строки
encoded = "".join(code[ch] for ch in s) # закодированная строка
assert huffman_decode(encoded, code) == s # раскодируем строку и сравним

хабр_торт_или_не_торт:

The end
Что ж, это были графовые и строковые алгоритмы, пусть эта шпаргалка поможет вам в подготовке к собесу.
Детально о том, как вообще проходит алгоритмическая секция, можно почитать в этой хабростатье — «План алгоритмического собеседования...»

А вот некоторые полезные ресурсы для изучения алгоритмов.
Во-первых, это лекции от Александра Охотина — нереально полезно (хотя местами слишком теоретизированно):


Также много всего годного можно найти тут — ru.algorithmica.org/cs/

...и вот здесь — eecs376.github.io/notes/algorithms.html


Отличного всем дня, новых горизонтов, и да не заменит вас ИИ)













