Привет, Хабр! Продолжаем публиковать рецензии на научные статьи от членов сообщества Open Data Science из канала #article_essense. Хотите получать их раньше всех — вступайте в сообщество!
Статьи на сегодня:
- ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks (China, 2020)
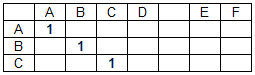
- TAPAS: Weakly Supervised Table Parsing via Pre-training (Google, 2020)
- DeepFaceLab: A simple, flexible and extensible faceswapping framework (2020)
- End-to-End Object Detection with Transformers (Facebook AI, 2020)
- Language Models are Few-Shot Learners (OpenAI, 2020)
- TabNet: Attentive Interpretable Tabular Learning (Google Cloud AI, 2020)