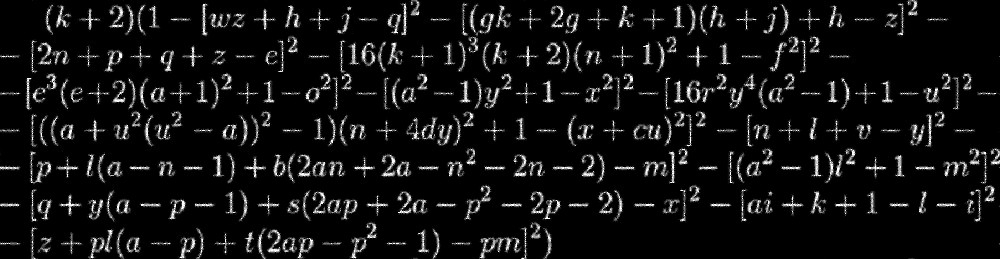Вероятно, самое сложное в любом Data Science-проекте — это придумать оригинальную, но реализуемую идею. Специалист, который ищет такую идею, легко может попасться в «ловушку наборов данных». Он тратит многие часы, просматривая существующие наборы данных и пытаясь выйти на новые интересные идеи. Но у такого подхода есть одна проблема. Дело в том, что тот, кто смотрит лишь на существующие наборы данных (c Kaggle, Google Datasets, FiveThirtyEight), ограничивает свою креативность, видя лишь небольшой набор задач, на которые ориентированы изучаемые им наборы данных.
Иногда мне нравится изучать интересующие меня наборы данных. Если я построю удачную модель для данных, взятых с Kaggle, для которых уже создано бесчисленное множество моделей, практической ценности в этом не будет, но это, по крайней мере, позволит мне научиться чему-то новому. Но дата-сайентисты — это люди, которые стремятся создавать что-то новое, уникальное, что-то такое, что способно принести миру реальную пользу.

Как вырабатывать новые идеи? Для того чтобы найти ответ на этот вопрос, я совместила собственный опыт и результаты исследований креативности. Это привело к тому, что мне удалось сформировать 5 вопросов, ответы на которые помогают находить новые идеи. Тут же я приведу и примеры идей, найденных благодаря предложенной мной методике. В процессе поиска ответов на представленные здесь вопросы вы пройдёте по пути создания новых идей и сможете задействовать свои креативные возможности на полную мощность. В результате у вас будут новые уникальные идеи, которые вы сможете реализовать в ваших Data Science-проектах.
Иногда мне нравится изучать интересующие меня наборы данных. Если я построю удачную модель для данных, взятых с Kaggle, для которых уже создано бесчисленное множество моделей, практической ценности в этом не будет, но это, по крайней мере, позволит мне научиться чему-то новому. Но дата-сайентисты — это люди, которые стремятся создавать что-то новое, уникальное, что-то такое, что способно принести миру реальную пользу.
Как вырабатывать новые идеи? Для того чтобы найти ответ на этот вопрос, я совместила собственный опыт и результаты исследований креативности. Это привело к тому, что мне удалось сформировать 5 вопросов, ответы на которые помогают находить новые идеи. Тут же я приведу и примеры идей, найденных благодаря предложенной мной методике. В процессе поиска ответов на представленные здесь вопросы вы пройдёте по пути создания новых идей и сможете задействовать свои креативные возможности на полную мощность. В результате у вас будут новые уникальные идеи, которые вы сможете реализовать в ваших Data Science-проектах.