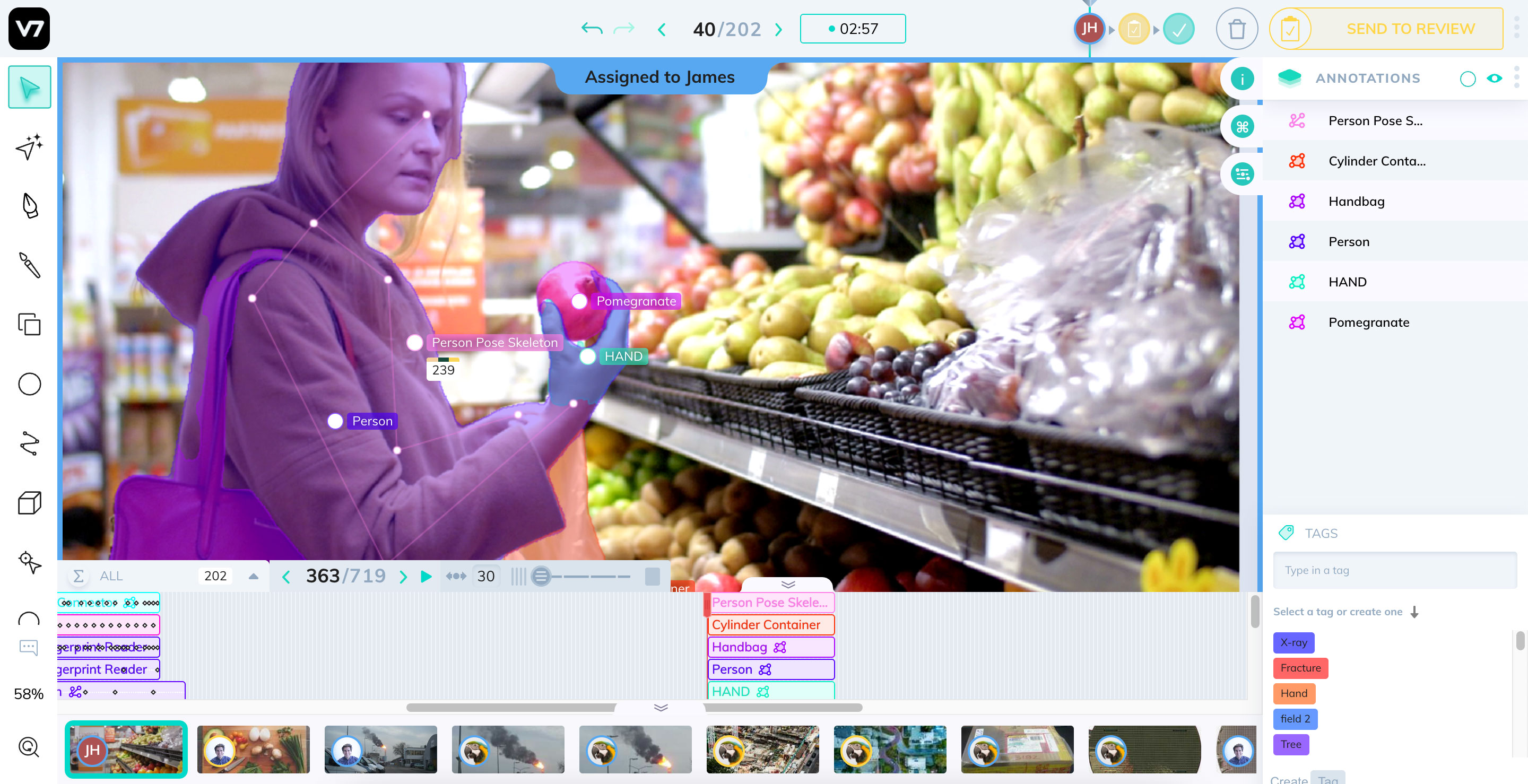
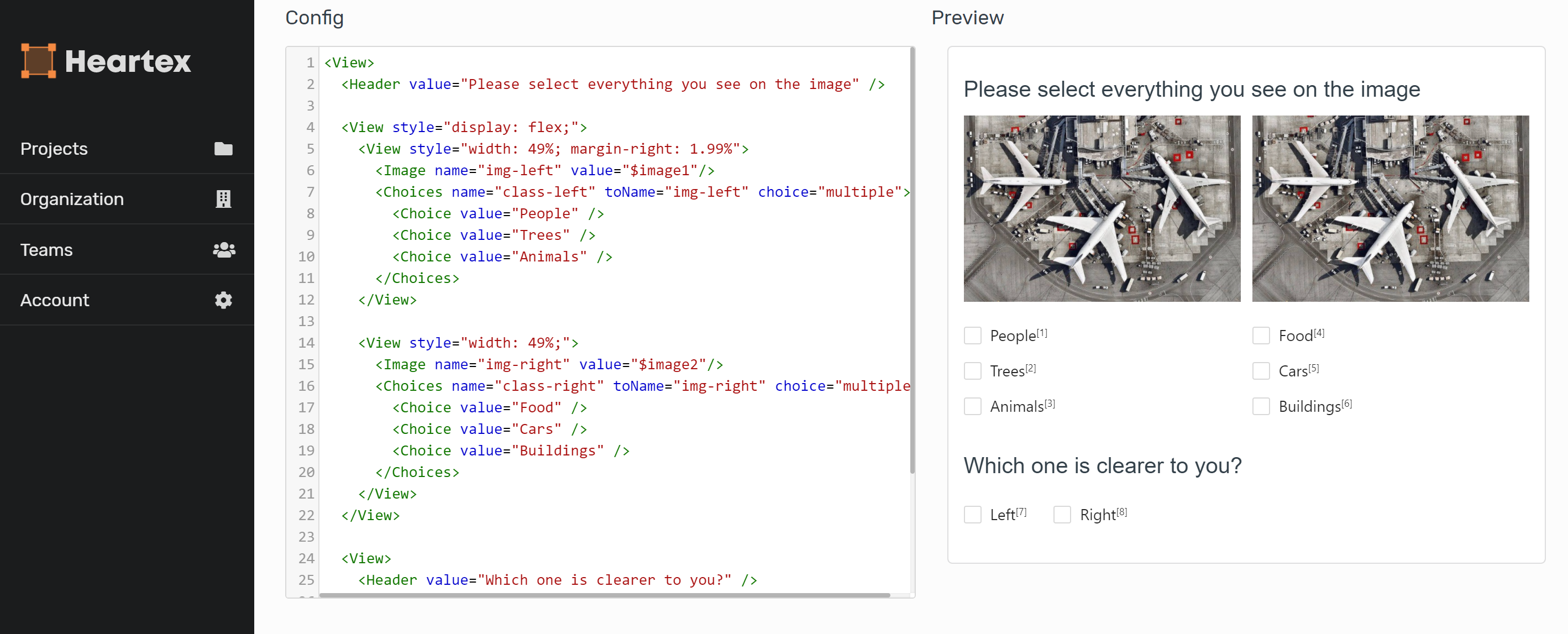
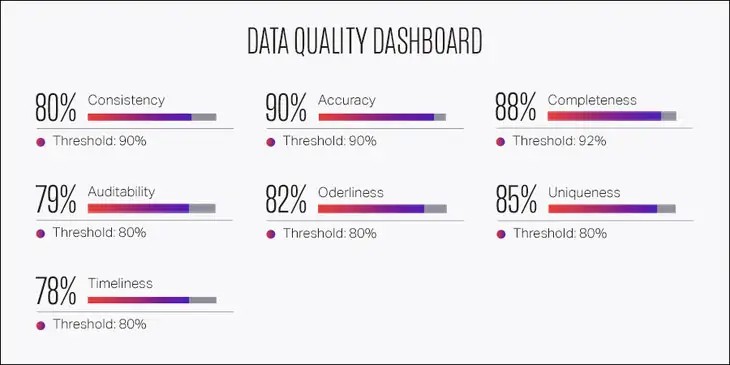
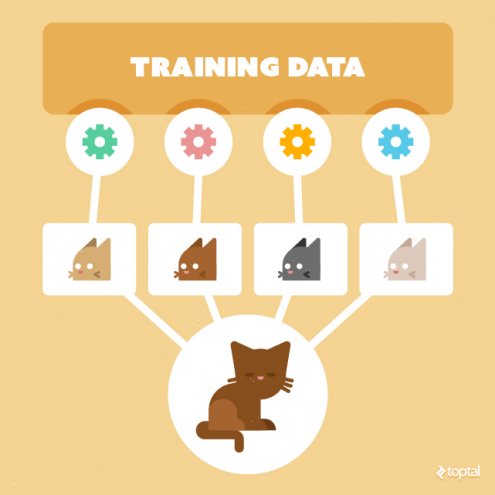
Данные — это душа каждой модели машинного обучения. В этой статье мы расскажем о том, почему лучшие команды мира, занимающиеся машинным обучением, тратят больше 80% своего времени на улучшение тренировочных данных.
Точность ИИ-модели напрямую зависит от качества данных для обучения.
Современные глубокие нейронные сети во время обучения оптимизируют миллиарды параметров.
Но если ваши данные плохо размечены, это выльется в миллиарды ошибочно обученных признаков и многие часы потраченного впустую времени.
Мы не хотим, чтобы такое случилось с вами. В своей статье мы представим лучшие советы и хитрости для улучшения качества вашего датасета.
Точность ИИ-модели напрямую зависит от качества данных для обучения.
Современные глубокие нейронные сети во время обучения оптимизируют миллиарды параметров.
Но если ваши данные плохо размечены, это выльется в миллиарды ошибочно обученных признаков и многие часы потраченного впустую времени.
Мы не хотим, чтобы такое случилось с вами. В своей статье мы представим лучшие советы и хитрости для улучшения качества вашего датасета.