Peace, Хабр!
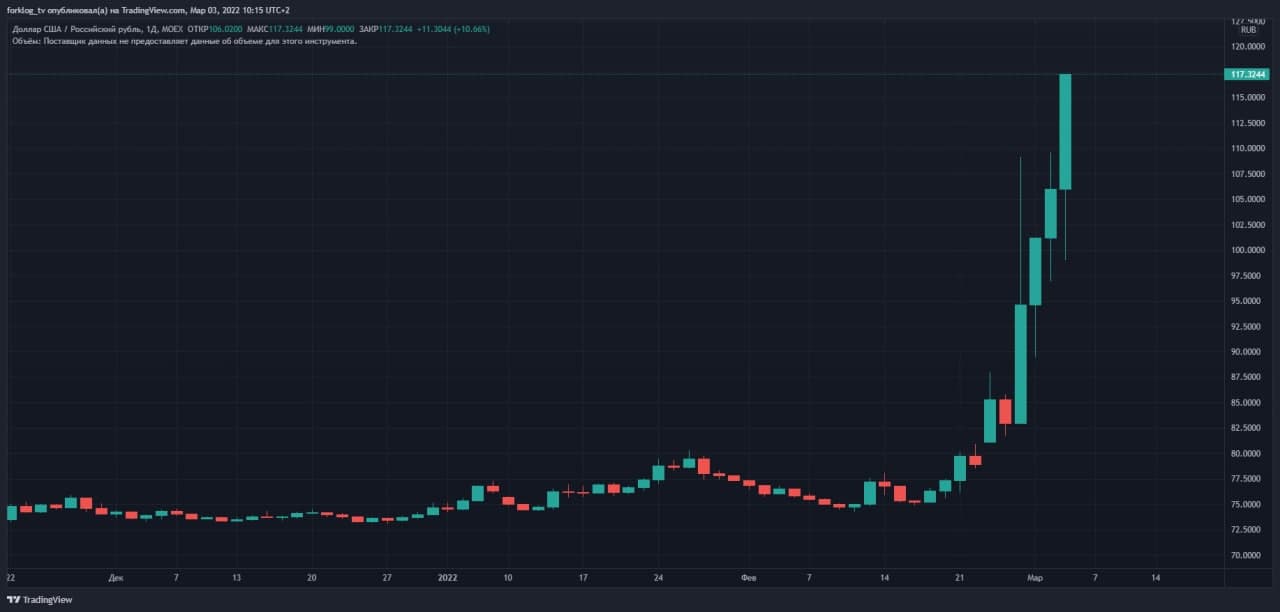
Последние дни много разговоров, что криптовалюта — способ: a) сберечь свои рублевые сбережения от обесценивания, b) вывести из под риска национализации валютные сбережения.
И действительно (хорошая новость): на текущий момент ограничений по покупке и хранению криптовалют для резидентов РФ нет. Ну почти нет. По сравнению с фиатными биржами — нет.
Но (плохие новости):
- Американские сенаторы уже обсуждают меры по ограничению использованию криптовалют для обхода санкций со стороны России [1],
- Евросоюз занят тем же самым [2],
- ФБР появилось подразделение по контролю за оборотом криптовалюты ([3], анонс от 17 февраля 2022, хотя межгосударственные финансовые дела вряд ли в их юрисдикции).
Еще хорошая новость (последняя):
Хрустальный шар/магический кристалл Гарри Поттер еще не подвез, поэтому сценарий с обходом санкций через криптовалютные переводы и с противостоянием этому обходу — это потенциальное будущее.
Снова плохая новость (не последняя):
Если Вам кажется, что риски в этом потенциальном будущем для Вас, как для частного инвестора, высокие, то Вам не кажется.
И что с этим делать?
Правильно — разобраться что, где, как (и надо ли) хранить условиях санкций.