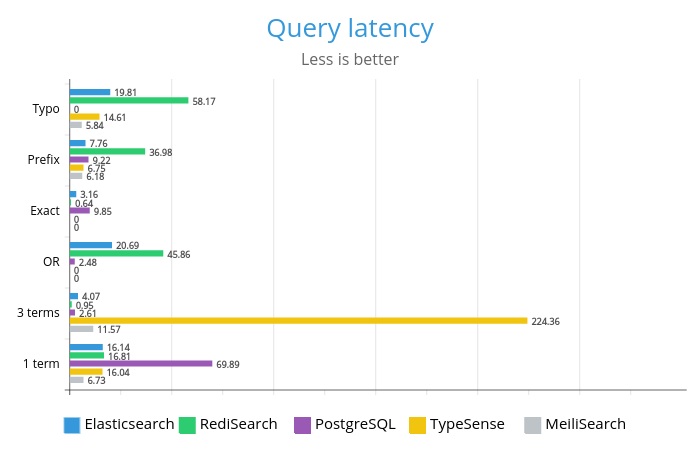
Привет! Меня зовут Аркадий. Последние пару лет я в основном занимаюсь развитием поиска по тексту в команде TQM (Tinkoff Quality Management) в банке Тинькофф. Наш продукт — это речевая аналитика по звонкам, чатам и другим активностям, контроль качества, анализ и прочее. Более подробно о продукте можно прочитать на странице бизнес-решений. Примерный объем нашего индекса в проде — 16 Тб, около 450 млрд сущностей.
Каждый раз, когда встает вопрос о полнотекстовом поиске, команда оказывается перед выбором: а надо ли? Уже есть полнотекстовый поиск в Postgres, а тут придется заказывать серверы, строить кластер. Но чем чаще пользователю требуется что-то найти, тем чаще приходится смотреть в сторону специализированных поисковых движков.
Как пишут сами разработчики Elasticsearch, он нужен именно «для поиска, вы же знаете» (you know, for search) и не сможет заменить полноценное хранилище данных. Зато достаточно быстрый, очень надежный и хорошо горизонтально масштабируется (при наших объемах).
Мы в TQM используем Elastic потому, что он гибкий, широко известный, имеет удобный и простой синтаксис, множество библиотек для работы как на Python, так и на C# (NEST). Хорошо скейлится под наши объемы (1—30 Тб). Kibana также очень удобна, мы используем ее для мониторинга, консоль Kibana применяем для запросов. А еще по сравнению с тем же Sphinx, Elastic удобно масштабировать (просто добавляем шарды, ноды, и он сам распределяет данные по ним). В случае с тем же Sphinx нам пришлось бы писать этот распределенный поиск самим, и не факт, что у нас получилось бы хорошо с первого раза.













 . Поговорим также о выводах, которые можно из этого сделать.
. Поговорим также о выводах, которые можно из этого сделать.