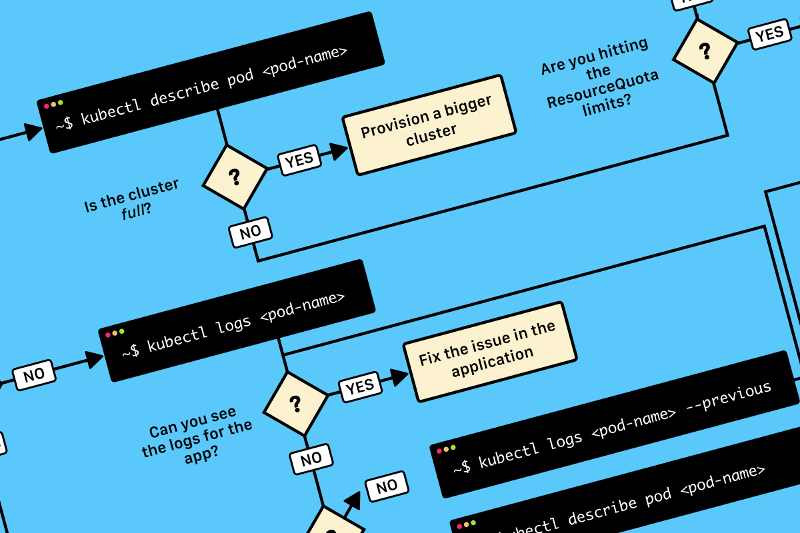
Под капотом hh.ru — большое количество Java-сервисов, запущенных в докер-контейнерах. За время их эксплуатации мы столкнулись с большим количеством нетривиальных проблем. Во многих случаях чтобы докопаться до решения приходилось долго гуглить, читать исходники OpenJDK и даже профилировать сервисы на продакшене. В этой статье я постараюсь передать квинтэссенцию полученного в процессе знания.
- CPU лимиты
- Docker и server class machine
- CPU лимиты (да, опять) и фрагментация памяти
- Обрабатываем Java-OOM
- Оптимизируем потребление памяти
- Ограничиваем потребление памяти: heap, non-heap, direct memory
- Ограничиваем потребление памяти: Native Memory Tracking
- Java и диски
- Как за всем уследить?