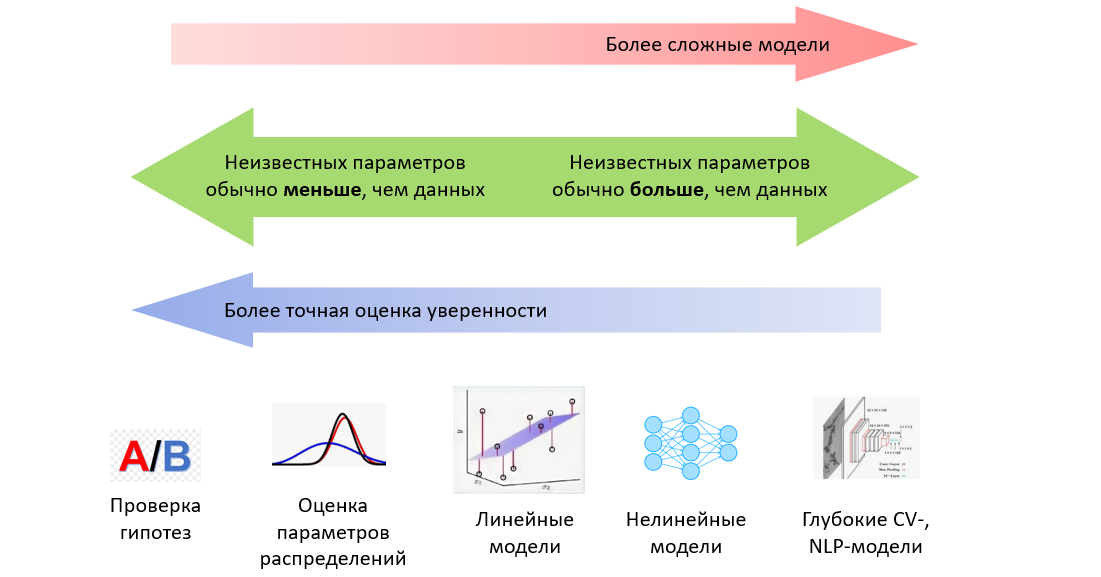
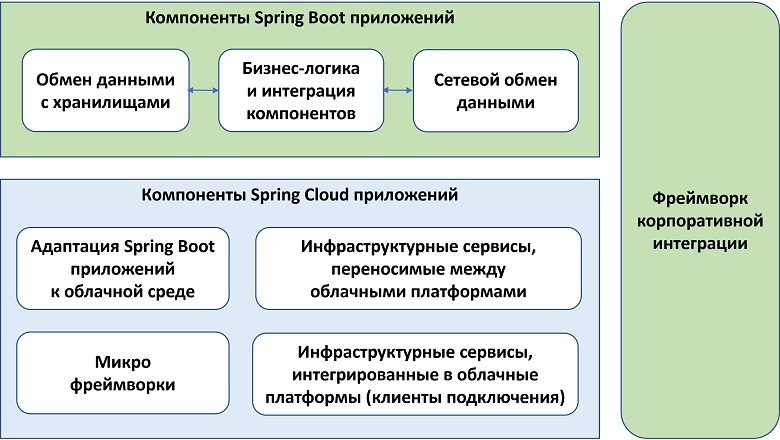
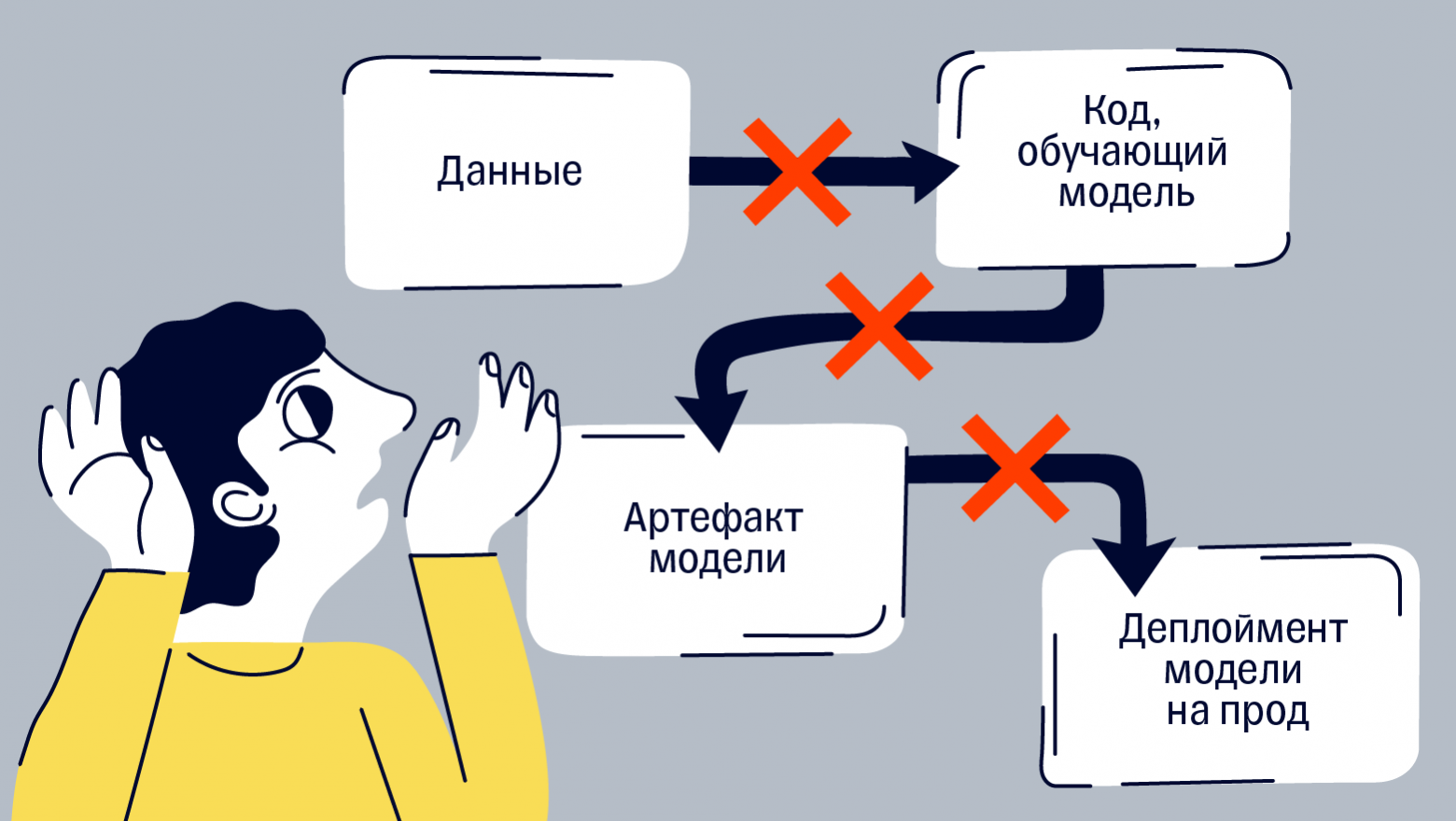
Представьте себе огромный ковш с жидким чугуном. В нём есть две примеси, которые мешают ему стать качественной сталью: фосфор и сера. Фосфор удаляют в конвертере на первом этапе выплавки стали, а вот серу нужно как-то убрать заранее. Для этого в расплав вдуваются реагенты вроде оксида магния, которые в ковше реагируют с серой, и продукты реакции всплывают наверх в виде шлаков типа пенки на молоке.
Ковш при этом накрыт крышкой-платформой, температуры там не самые приятные для электроники. У нас есть максимум 10 минут на то, чтобы снять этот шлак с помощью скиммера (такого огромного железного скребка), затем выдвижная стрела сильно перегревается. Задача — убрать почти всю серу из расплава.
Раньше задача решалась на глаз: специалисты цеха делали несколько движений скиммером по ковшу, ориентировались на количество оставшегося шлака в поле зрения и решали, что всё, вроде его осталось мало. Но «вроде» никого не устраивало.
А лишние движения скиммером — это лишние несколько тонн потерянного чугуна. Если же сделать движений меньше, чем надо для 95 % удаления, то дальше мы не попадём в физико-химические свойства сортамента стали. К тому же время, уходившее на снятие шлака, разнилось от плавки к плавке: где-то оператор справлялся за четыре минуты, а где-то — за все восемь с половиной. А каждая выигранная минута повышает производительность конвертера.
В итоге мы придумали, что можно поставить камеру около заливочного носка ковша (который обычный человек называет носиком), чтобы видеть количество оставшегося шлака на зеркале и точно определить процент его удаления, который даже через десятилетия опыта на глаз определяется сложно.
Уже полгода система в опытной эксплуатации, и, похоже, можно праздновать победу.