Публикую на Хабр оригинал статьи, перевод которой размещен в блоге Codingsight.
Более пяти лет работаю в компании, что занимается разработкой линейки IDE для работы с базами данных. Начиная работу над этой статьей я и не представлял как много интересных историй получится вспомнить, потому когда закончил получил более 30 страниц текста. Немного подумав, я сгруппировал истории по тематике, а статью разбил на несколько.
По мере публикации буду добавлять ссылки на следующие части:
Часть 1. Сложности парсинга. Истории о доработке ANTLR напильником
Часть 2. Оптимизация работы со строками и открытия файлов
Часть 3. Жизнь расширений для Visual Studio. Работа с IO. Необычное использование SQL
Часть 4. Работа с исключениями, влияние данных на процесс разработки. Использование ML.NET
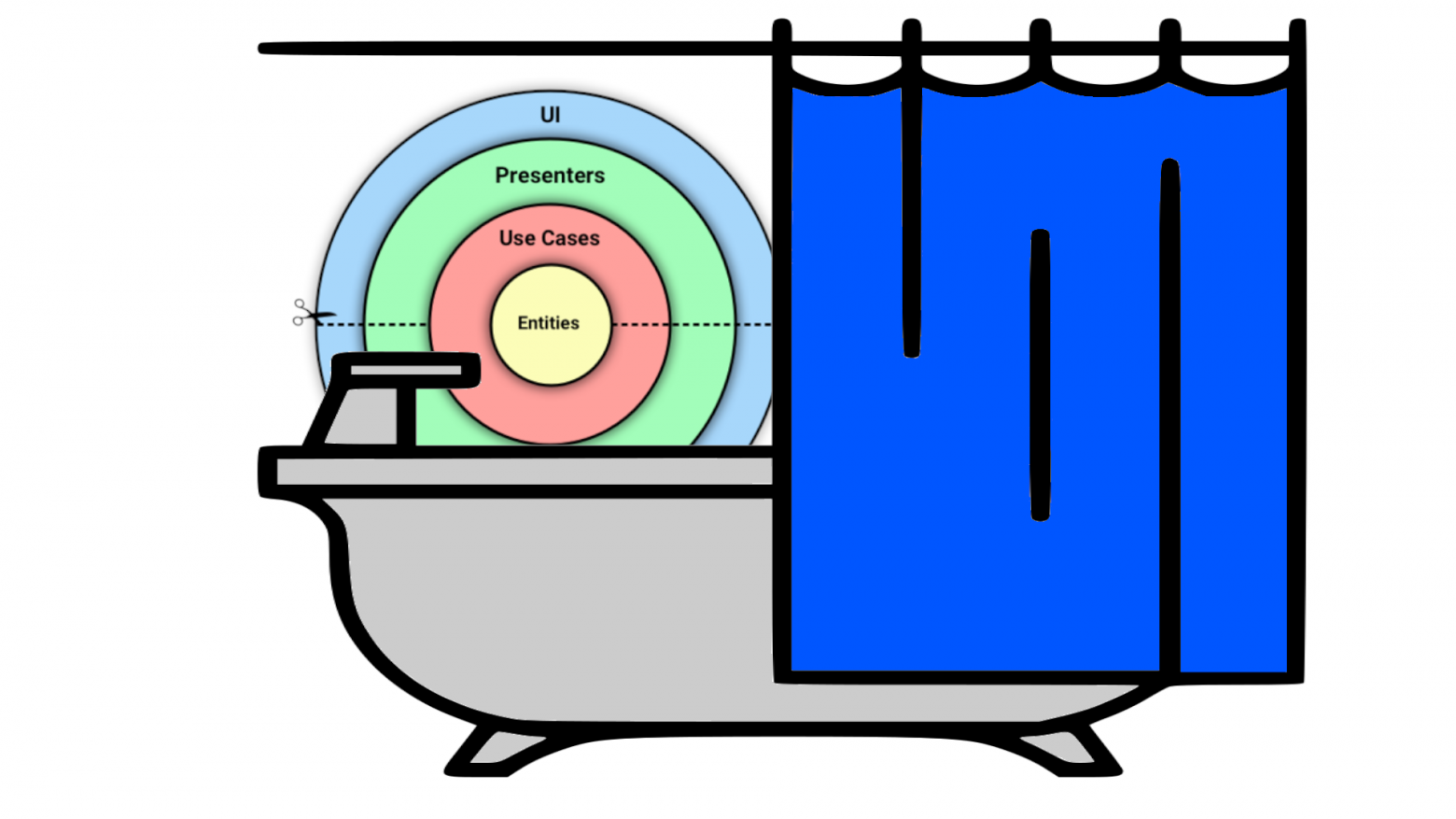
За время работы произошло много интересного: мы нашли несколько багов в .NET, оптимизировали некоторые функции во много раз, а некоторые лишь на проценты, что-то делали очень круто и с первого раза, а что-то у нас не получалось даже после нескольких попыток. Моя команда занимается разработкой и поддержкой языковых функций IDE, главная из которых автодополнение кода. Отсюда и название цикла статей. В каждой их частей я буду рассказывать несколько историй: некоторые об успехах, некоторые о неудачах.
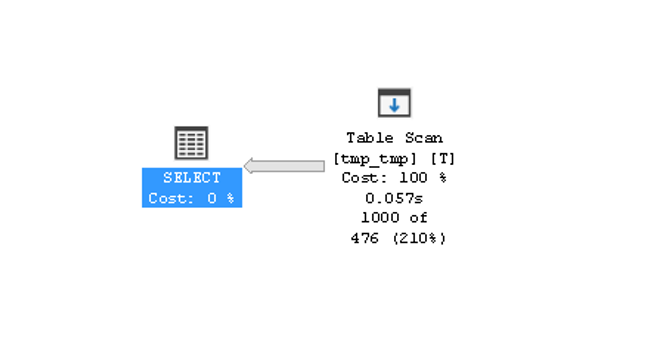
В этой части я сосредоточусь на проблемах парсинга SQL, борьбе с этими проблемами и ошибками допущенными в этой борьбе.

Что будет в этой статье?
Более пяти лет работаю в компании, что занимается разработкой линейки IDE для работы с базами данных. Начиная работу над этой статьей я и не представлял как много интересных историй получится вспомнить, потому когда закончил получил более 30 страниц текста. Немного подумав, я сгруппировал истории по тематике, а статью разбил на несколько.
По мере публикации буду добавлять ссылки на следующие части:
Часть 1. Сложности парсинга. Истории о доработке ANTLR напильником
Часть 2. Оптимизация работы со строками и открытия файлов
Часть 3. Жизнь расширений для Visual Studio. Работа с IO. Необычное использование SQL
Часть 4. Работа с исключениями, влияние данных на процесс разработки. Использование ML.NET
За время работы произошло много интересного: мы нашли несколько багов в .NET, оптимизировали некоторые функции во много раз, а некоторые лишь на проценты, что-то делали очень круто и с первого раза, а что-то у нас не получалось даже после нескольких попыток. Моя команда занимается разработкой и поддержкой языковых функций IDE, главная из которых автодополнение кода. Отсюда и название цикла статей. В каждой их частей я буду рассказывать несколько историй: некоторые об успехах, некоторые о неудачах.
В этой части я сосредоточусь на проблемах парсинга SQL, борьбе с этими проблемами и ошибками допущенными в этой борьбе.