В предыдущих статьях я рассказал об этапах выполнения запросов и о статистике.
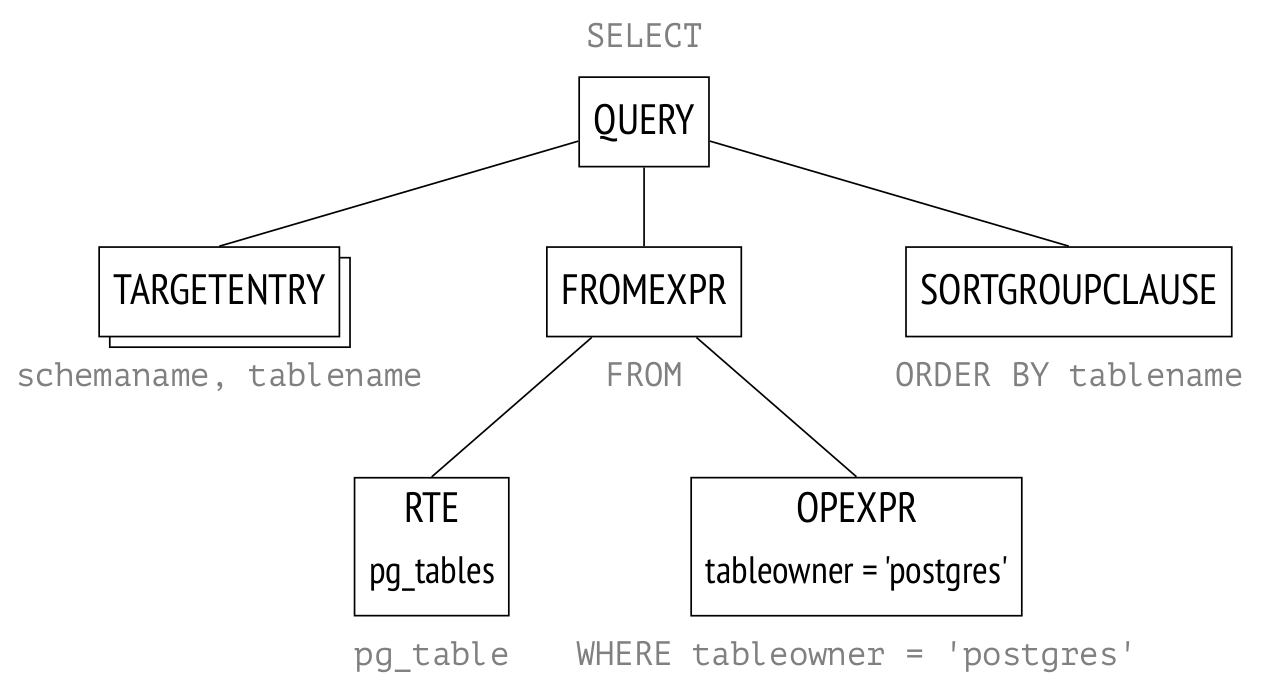
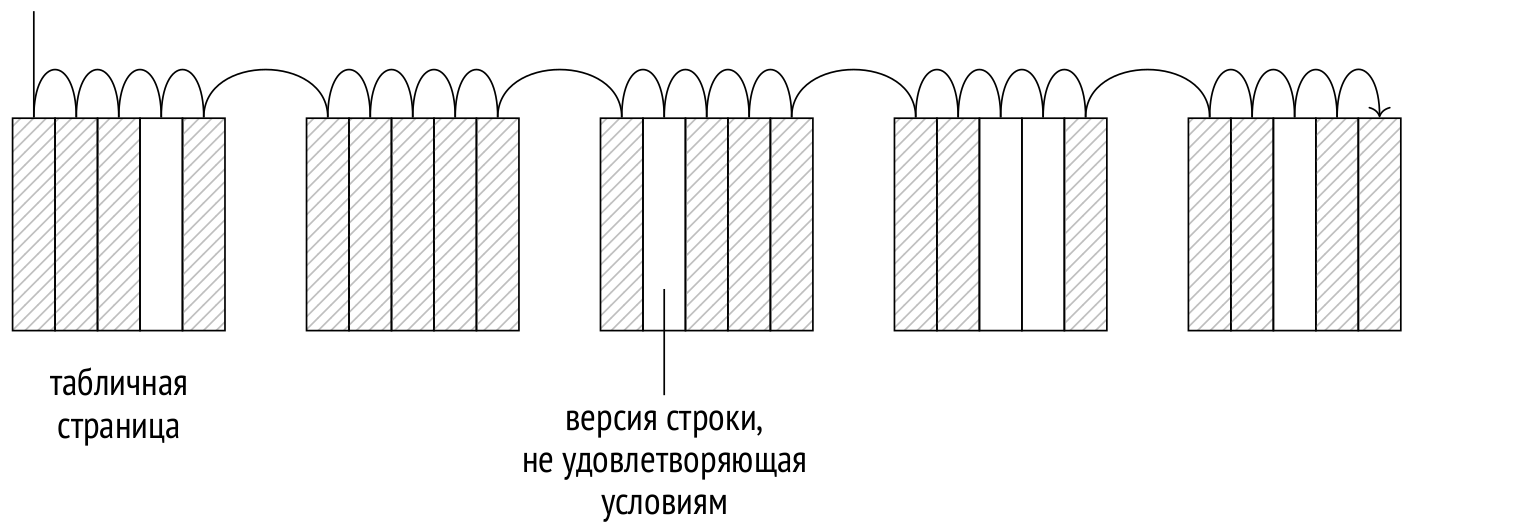
Теперь пришла пора рассмотреть самые важные узлы, из которых может состоять план. Я начну со способов доступа к данным, и в этой статье расскажу о последовательном сканировании.
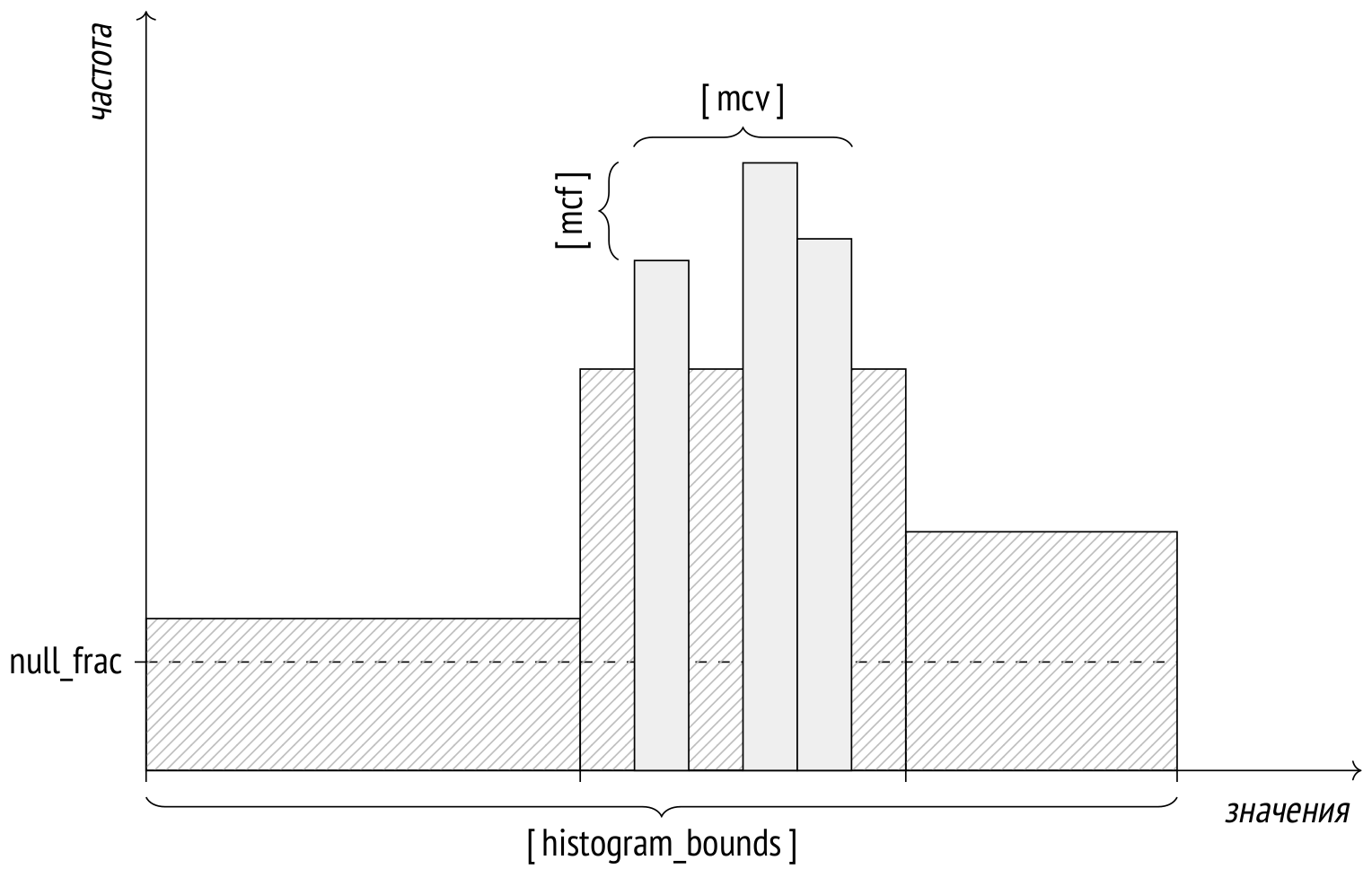
В прошлый раз я показывал, как на основе статистики вычисляется кардинальность, а в этой и следующих буду демонстрировать, как рассчитывается стоимость узлов плана. Не то, чтобы конкретные формулы оценки имели большое значение для понимания деталей работы планировщика, но мне хочется показать, что все цифры выводятся из статистики без привлечения черной магии.