
От переводчика: когда я начал разбираться с MVC-фреймворками для фронт-энда, каким-то чудом попалась на глаза эта статья Henrik Joreteg. Сейчас дошли руки перевести ее для Хабра, тем более, что об AmpersandJS на Хабре вообще не слышно. Попробую организовать цикл статей по этому инструменту ребят из &yet, мне кажется, он достоин внимания.

В рамках наших образовательных семинаров я даю краткий обзор JS фреймворков. Я не очень-то хотел публиковать большую часть моих мнений об этих инструментах в Сети, потому что такие вещи, как правило, вызывают бурление масс, обижают людей, и в отличие от разговора с глазу на глаз, в интернет-дискуссиях нет действительно хорошей двунаправленной связи с аудиторией.
Но мне не раз говорили, что мой обзор крайне полезен и помогает получить сжатое и, в то же время, хорошее понимание в вопросе «кто есть кто в JS фреймворках для создания одностраничных приложений». По этому поводу я решил материализовать его и опубликовать как Нечто, но, пожалуйста, помните, что я просто высказываю свое мнение, я не говорю вам, что делать, и вы должны использовать те инструменты, которые лучше подходят вам и вашей команде. Вы можете запросто не согласиться со мной, написать об этом в Твиттере, или, еще лучше, опубликовать отдельный пост, объясняющий вашу позицию.
В рамках наших образовательных семинаров я даю краткий обзор JS фреймворков. Я не очень-то хотел публиковать большую часть моих мнений об этих инструментах в Сети, потому что такие вещи, как правило, вызывают бурление масс, обижают людей, и в отличие от разговора с глазу на глаз, в интернет-дискуссиях нет действительно хорошей двунаправленной связи с аудиторией.
Но мне не раз говорили, что мой обзор крайне полезен и помогает получить сжатое и, в то же время, хорошее понимание в вопросе «кто есть кто в JS фреймворках для создания одностраничных приложений». По этому поводу я решил материализовать его и опубликовать как Нечто, но, пожалуйста, помните, что я просто высказываю свое мнение, я не говорю вам, что делать, и вы должны использовать те инструменты, которые лучше подходят вам и вашей команде. Вы можете запросто не согласиться со мной, написать об этом в Твиттере, или, еще лучше, опубликовать отдельный пост, объясняющий вашу позицию.
Angular.js
за
- очень легко начать использовать. можно просто вставить тег script, добавить немного ng- атрибутов в ваше приложение, и вы волшебным образом получаете нужное вам поведение
- Angular хорошо поддерживается его основной командой разработчиков, многие из которых работают в Гугле на постоянной основе
- большая аудитория/сообщество
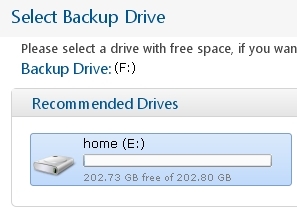 IT-специалистам несложно настроить резервное копирование дома, например, с помощью rsync, созданием rar-архивов планировщиком задач, инкрементальным копированием в интернет (не говоря уже о настройке tar+cron или bacula на работе). Однако неспециалисты (для дома) будут использовать программы резервного копирования, которые много проще. Рассмотрим программу, скрывающей за привычной простотой для домашнего пользователя, гибкий и хорошо продуманный инструмент резервного копирования.
IT-специалистам несложно настроить резервное копирование дома, например, с помощью rsync, созданием rar-архивов планировщиком задач, инкрементальным копированием в интернет (не говоря уже о настройке tar+cron или bacula на работе). Однако неспециалисты (для дома) будут использовать программы резервного копирования, которые много проще. Рассмотрим программу, скрывающей за привычной простотой для домашнего пользователя, гибкий и хорошо продуманный инструмент резервного копирования.
 На различных конференциях мы неоднократно рассказывали про наше облако для CLI-скриптов (
На различных конференциях мы неоднократно рассказывали про наше облако для CLI-скриптов (
 (Окончание перевода статьи Эдди Османи о сравнении и выборе библиотеки для проекта со значительной ролью JS на клиенте.)
(Окончание перевода статьи Эдди Османи о сравнении и выборе библиотеки для проекта со значительной ролью JS на клиенте.)







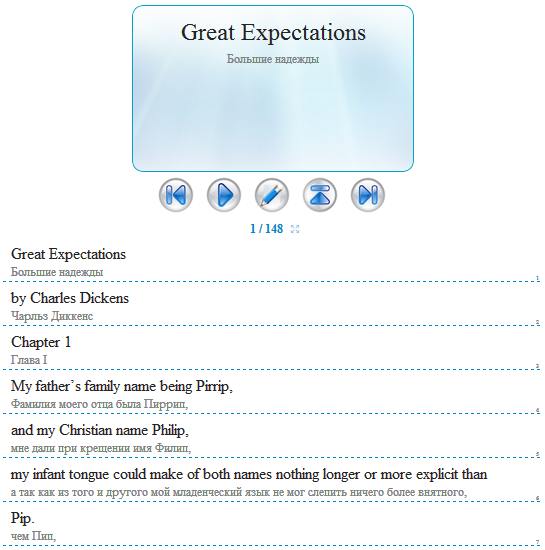 Многие используют фильмы с субтитрами, чтобы слушать речь и одновременно читать. Хочу предложить альтернативу — слушать аудио книги и читать их текст с подстрочным переводом и доступом к каждой отдельной фразе. Они доступны онлайн на сайте
Многие используют фильмы с субтитрами, чтобы слушать речь и одновременно читать. Хочу предложить альтернативу — слушать аудио книги и читать их текст с подстрочным переводом и доступом к каждой отдельной фразе. Они доступны онлайн на сайте