Комментарии 510
Офис по кибербезопасности Белого дома США призвал разработчиков переходить на безопасные ЯП типа Rust https://habr.com/p/796901/
...подождите ещё хоть полгодика.
он пожаловался, что C и C++ опять объединяют в одну категорию, полностью игнорируя более 30 лет развития
Ой, почему же так происходит? Почему столько лет игнорируют всё это ваше «развитие»? Может, не стоило добавлять четыре разных приведения типов, каждое из которых требует двух угловых скобок, двух обычных и символа подчёркивания? Может, не стоило вместо List<>.Add() (как у нормальных людей) делать vector<>.push_back()? Может, не стоило алгоритмы оформлять как классы (!!!), вместо того, чтобы инкапсулировать как часть коллекций? Может, не стоило делать два разных типа стрингов, широкие и узкие, которые умеют делать примерно ничего?
Да не, фигня какая-то.
Это претензии к чему? То что разные вещи называются по разному (касты)?) Считание угловых скобочек это что-то уже совсем странное, претензии такие, что даже объяснять что тут не так как то смешно
К удобству. Писать (T) и * проще, чем std::reinterpreprepret_cast<T>( ) и std::shared_ptr<T>( ). Общий смысл такой:
В C++ есть старые инструменты, позволяющие писать небезопасный код
В C++ также есть новые инструменты, позволяющие писать безопасный код
Большинство новых инструментов сделаны вырвиглазными, многословными, многобуквенными и неудобными. Да, ими можно пользоваться. Но удобными они от этого не становятся
Многословная многобуквенность. Очень напоминает бюрократию из человеческого мира, где на каждый чих нужна справка. Вот тут тоже — захотел чихнуть, пиши громоздкую конструкцию с квадроточиями, подчёркиваниями и длинными словами. А всё что писалось буквально одним символом — это теперь ересь, так делать нельзя. Спасибо что хоть перед фигурными скобками std::{ не надо писать std::}
Это (добавление новых возможностей для безопасности) надо было сделать — да. Это C++, он профессиональный язык для серьёзных штук, а не какой‑нибудь там питон — снова да. Но, всё равно, это надо было сделать удобнее. Даже в int32_t не обошлось без земли! Ну зачем так делать?
Эргономика есть не только у кружек, дрелей, и приложений. У языка она тоже есть. Человек, создающий сложные серьёзные штуки, может страдать от сложности задачи, но он не должен страдать от инструмента, с помощью которого он эти задачи решает.
Вот перейти надо трассу. Можно просто перелезть через отбойник и быстро перебежать. А вон справа вон, безопасный мост. Вы идёте до него 100 метров, пристёгиваетесь к перилам, поднимаетесь по 8 лестничным пролётам. Затем отстёгиваетесь, наверху, у вас проверяют паспорт, проверяют знание стихотворений Лермонтова наизусть, потом вы идете первую половину моста, вас останавливают, досматривают, спрашивают цель перехода и собираетесь ли вы потом идти обратно, вам дают ключ, потом проходите вторую половину моста, проходите тест на трезвость (а вдруг вы упадёте) открываете калитку, пристёгиваетесь к перилам, спускаетесь по лестинце 8 пролётов, отстёгиваетесь от перил, проходите 100 метров обратно. Безопасно? Безопасно. И чего все возмущаются, глупости какие‑то...
Что вам мешает сделать свой алиас, который будет по вашему "многословные" вещи делать такими, как вам удобно?
И опять же противоречие, в одном месте - нужно чтобы небезопасный код было писать сложнее, в другом месте reinterpret_cast (самое небезопасное что можно придумать) - а давайте покороче!
Про указатели вы совсем не попали, просто поинтер (*) и shared_ptr это максимально разные вещи, одно на другое заменить нельзя никогда
Эргономика есть не только у кружек, дрелей, и приложений. У языка она тоже есть.
Вот тут то вы и правы, только у языка не эргономика, а семантика. Чтобы код можно было читать и писать язык должен быть логичным и понятным, т.е. его семантика должна быть интуитивна
И в этом качестве я конкурента С++ ни одного не знаю, shared_ptr отлично выражает то что происходит в коде, также как и reinterpret_cast, читаешь код и всё однозначно и понятно.
Теперь сравните с семантикой "безопасного" языка(Rust)
shared_ptr => Arc
reinterpret_cast<T>(x); => let new_value = unsafe { mem::transmute(bytes) };
Ну как, понятно? Если подумаете, что понятно, то скажите к какому типу "трасмутируются" байты во втором сценарии. (ответ: неизвестно, это выведется из дальнейшего использования 'new_value', очень безопасно)
Конечно, можно обточить напильником любую дичь и сделать из неё конфетку. Но проблема как раз в том, что без напильника эта дичь — дичь.
И опять же противоречие, в одном месте - нужно чтобы небезопасный код было писать сложнее, в другом месте reinterpret_cast (самое небезопасное что можно придумать) - а давайте покороче!
Моя претензия как раз и состоит в том, что в этом языке покороче является противоположностью безопаснее. Так быть не должно. Должно быть (покороче и безопаснее) или (подлиннее и небезопаснее).
Про Rust я ничего не писал, Вы сами его упомянули. Я на нём не пишу и отношусь к нему нейтрально никак. Появится мой личный опыт работы с ним — будут сравнивать.
И в этом качестве я конкурента С++ ни одного не знаю, shared_ptr отлично выражает то что происходит в коде, также как и reinterpret_cast, читаешь код и всё однозначно и понятно.
Ч — std::reinterpert_cast<std::word>(std::shared_ptr<std::sarcasm>(std::читаемость_t))
Я не специалист по С++, но лет много назад читал, что названия типа reinterpret_cast специально выбирали такими неудобными, чтобы программистам было неохота использовать подобные приемы в коде. Ведь если тебе надо использовать байты одного типа как байты другого типа, то явно что-то не так в логике - это либо хитрая оптимизация, и тогда не жалко написать специальное слово, либо так делать не надо.
А то что то же самое можно записать парой символов в стиле С - ну это для совместимости оставили, а не для удобства.
Речь то не про конкретно приведение типов, а про то, что почти всё новое в C++ сделано неудобно. С каждым разом от тебя хотят всё больше и больше __всяких:::::::слов, <std::букв> и constexpr [[std::вырвиглазных]]:::<<<<конструкций___t>>> constexpr, апеллируя к Безопасности с большой красивой буквы std::Б.
Ниже unC0Rr привёл отличный пример:
30 лет развития C++ - это когда вместо
std::string doit(std::string param);нужно писать[[nodiscard]] constexpr auto doit(std::string_view param) noexcept -> std::string;
Это что вообще за дичь? Зачем так делать? Зачем они пытаются догнать брейнфак? Им там скучно?
C++ хороший, не закапывайте C++, пожалуйста.
когда вместо ... нужно писать
Не нужно. Каждое слово что-то значит, должно быть написано зачем-то. Не хотите писать - не пишите
Вот и не хотят. Вот и не пишут. Вот и получается небезопасно. Об этом и речь. Надо чтобы вероятность захотеть написать безопасно была выше, чем вероятность захотеть написать небезопасно.
Более‑менее неплохой пример — то, как это сделано в C#. Я могу писать только безопасно. Если я хочу писать опасно, я сначала должен зайти, поставить галочку
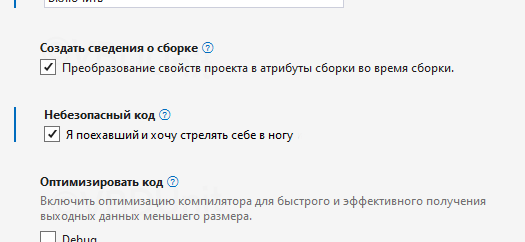
потом написать
unsafe
{
}И только внутри мне позволят творить опасные опасности. А для __makeref и __refvalue вообще не показываются автокомплиты. Небезопасному коду мешает и семантика языка, и компилятор языка, и среда разработки. А безопасный код пишется проще.
А в C++ наоборот: если я хочу писать опасно, я просто пишу * и &. Если же я хочу писать безопасно, мне надо std::shared_ptr constexpr const const std::lock_guard.
Я не говорю что такой подход идеальный, просто в нём вектор удобства повернут в нужную сторону — удобнее писать безопасно, чем небезопасно.
Вы просто не пишите на C++ в принципе, поэтому ретранслируете всевозможные дурацкие примеры вроде "нужно писать [[nodiscard]] constexpr auto doit(std::string_view param) noexcept -> std::string; " или "Если же я хочу писать безопасно, мне надо std::shared_ptr constexpr const const std::lock_guard". Можно подумать за пределами c++ разделяемое владение никому не нужно (или наоборот, всем нужно только и исключительно оно, поэтому shared_ptr там опущено и принимается по умолчанию), как и блокировки.
Мне часто приходится писать на C++, хотя да — это далеко не основной язык, которым я пользуюсь. В основном я хожу туда за числодробилками и/или 3D‑графикой.
Можно подумать за пределами c++ разделяемое владение никому не нужно (или наоборот, всем нужно только и исключительно оно, поэтому shared_ptr там опущено и принимается по умолчанию), как и блокировки.
Это частности, на примере которых я объясняю непродуманность и неудобность нововведений языка.
Я не говорю «частное владение нужно» или «частное владение не нужно», я не говорю «блокировки нужны» или «блокировки не нужны».
Я говорю, что в язык C++ блокировки были вставлены бездумно и неудобно, я говорю, что разделяемое владение было сделано бездумно и неудобно. И почти всё новое, что они туда засунули, они засунули бездумно и неудобно.
Ещё раз, само то, что засунули — хорошо, то каким именно способом засунули — плохо.
И почти всё новое, что они туда засунули, они засунули бездумно и неудобно.
А удобно это как? Вот есть int, есть int *, как должен выглядеть, по-вашему, удобный std::shared_ptr<int>?
int* написать проще, чем std::shared_ptr<int>. Поэтому опасность удобнее и лаконичнее безопасности. Это проблема
Я рассуждаю следующим образом. Что мы могли бы сделать с языком, если наша задача предоставить сообществу разработчиков удобный, эффективный и безопасный инструмент?
Сломать обратную совместимость и сделать так, что int* — это и есть std::shared_ptr<int>, а для небезопасного указателя сделать std::unsafe_ptr<int>. Тогда получится, что безопасно писать удобнее, а небезопасно — неудобнее. Профит. Минус: мы тотально уничтожили обратную совместимость, да ещё и запутали разработчиков.
Сохранить обратную совместимость, но сделать так, что новый безопасный указатель проигрывает конкуренцию по эргономике небезопасному указателю - это то, что сделано сейчас. Вот это вот std::shared_ptr<int> - это неудобная дичь.
Сохранить обратную совместимость, но сделать так что новый указатель выигрывает конкуренцию по эргономике небезопасному указателю. Это будет стимулировать разработчиков использовать его. Это идеальный вариант. Проблема в том, что сложно придумать что-то лаконичнее, чем звёздочка *. Я понятия не имею, что это может быть.
Сохранить обратную совместимость, но сделать так что новый указатель не проигрывает конкуренцию по эргономике небезопасному указателю. Это не будет стимулировать разработчиков использовать его, но и не будет отталкивать. Как? Это уже дискусионный вопрос. Самое главное, что должно быть обязательно — эта форма не должна быть менее удобной, чем *. В рамках мозгового штурма можно накидать предлагаемые варианты:
int`
int@
int^ (занят C++ CLI)
int+
int$
int_ptr (добавление постфикса _ptr к любому типу делает его безопасным указателем)
Ничего не добавлять, но обязать встраивать в компилятор ИИ‑анализатор, который будет палить потенциальные неочевидные места, где int* выстрелит тебе в ногу и выкидывать варнинги — то, что сейчас кажется безумием, в будущем будет нормой.
Ещё что-нибудь, что не будет требовать писать жирные::__монструозные<констр>(укции) const.
Да, лезть в синтаксис с неочевидной фигнёй, наверное, не круто. А звёздочка — она разве очевидная? Она привычная, но не очевидная. Звёздочка есть часть синтаксиса, и она состоит из одного символа. Конкурировать по эргономике с ней может только то, что не сложнее. Поэтому, как бы неприятно это не было, это может быть только ещё один какой‑то символ. Да, это не так очевидно для тех, кто видит это в первый раз. Но C++ — это не про низкий порог вхождения, наверное. Хотя может я ошибаюсь.
Я не думаю, что моё предложение прям хорошее, и сам в нём не особо уверен, это просто размышления. Это субъективщина.
Обращаю внимание: утверждение о том, что текущая реализация плоха, и утверждение о том, как это, по моему субъективному мнению, можно было бы сделать лучше — это два разных утверждения. И даже если моё предложение неудачно — из ложности второго утверждения не следует ложность первого. Логика.
Не поверите, писать небезопасно (не проверять условия и тд и тп), всегда проще. В любом языке.
"int* написать проще, чем std::shared_ptr<int>. Поэтому опасность удобнее и лаконичнее безопасности. Это проблема "
Проблема - это вот такие бездумные комментарии. shard_ptr - это всего лишь шаблон. Один из многих. Ваши фантазии на тему, что этот шаблон самый правильный и нуждается в особом синтаксисе, конечно прикольные, но жизнь несколько разнообразнее. Ну и конкретно в вашем примере, не поверите, писать shared_ptr не надо. Можно юзать auto. При создании используется make_shared. Не говоря уже о том, что для int обычно юзают optional. А если вам нужны особые сокращения, то никто не мешает написать для себя using или typedef. Но прочитать такой код смогут немногие )
Уважаемый, расскажите нам всем как использовать стд::опшинал со ссылками и не надо тут ляля разводить, что мне это не надо или что вот используйте указатель или что я с++ не понимаю или ещё какую ересь. Где мои безопасные нулабл ссылки я вас спрашиваю!? А нету их и не будет пока страуса буквально не закопают.
reference_wrapper?
Бтв, ссылки по стандарту это вообще алиас на имя и по возможности резолвятся без оверхедов, а не немутабельный указатель, поэтому столько болей.
Для вашей задачи вполне подойдёт T*, хоть и архаично выглядит. Ну а безопасность на уровне опшонала через операторы)
Во-первых врапер НЕ нулабл, во вторых задеррекейчен, а в третьих в с++20 удален.
Для моей задачи (безопасная работа с нулабл ссылками) Т* НЕ подойдёт.
Безопасность на уровне опшинал через операторы - я тут не понимаю о чем вы. Вот операторы из опшионала для безопасности как раз таки надо удалить потому что это как раз и есть проблема писать не безопасно (*) легко, а безопасно (валью) сложно.
Во-первых врапер НЕ нулабл, во вторых задеррекейчен, а в третьих в с++20 удален.
Я уже чуть было не испугался.std::reference_wrapper не за'deprecate'чен.std::reference_wrapper не удалён в C++20.
А то когда-то давно была такая шутка, что комитет принял решение запретить указатели в C++.
Так вам получается и shared_ptr не подходит, он тоже не проверяет сам, лежит ли в нём nullptr. Вообще, все стандартные контейнеры ориентированы не только на безопасность, но и на возможность извлечь максимальную производительность, причём в случае конфликта обычно отдавая предпочтение последнему.
А если вам не нужна производительность, то зачем вы пишете на плюсах?
лишний if прописать слабо? или оно само все должно у вас там раскорячиваться?
оборачиваете во wrapper и передаете хоть null, хоть не инициализирующее значение. без страуструпа никак не наваять?
Вся эта страшная страшность про неудобность написания std::shared_ptr<T> вместо, скажем, T@ разбивается о наличие достаточно работоспособной системы вывода типов. Да, я напишу std::shared_ptr в объявлении или make_shared где-то локально, но на этом +/- и всё.
А лезть в синтаксис ради оптимизации двух с половиной символов в каких-то там миллионных долях кодовой базы действительно не круто
Ну, даже со звездой еще в Сишечке было не все в порядке. Контекстная зависимость сделала злобное дело, и теперь один и тот же символ, написанный перед именем, обозначает разное в зависимости от типа значения, причем тип значения к самому имени, естественно, визуально никак не прикреплен.
В том же Паскале хоть как то пытались с этим бороться:
^integer - тип указателя на значение
a^ - разыменованый указатель (само значение получаемое по указателю)
Здесь хотя бы положение уголка меняется, да и операция разыменовывания (тоже уродское слово из мира сишечки) написана после имени. Казалось бы, ерунда? Вот только эта ерунда приводит к тому, что программист на сишечке вынужден читать тип выражения по спирали а понимание деклараторов превращается в пытку. Очень удобно и интуитивно понятно.
Так что тут до std::shared_ptr<int> еще авгиевы конюшни даже с одной кривой сущностью разгребать и разгребать.
Вот только эта ерунда приводит к тому, что программист на сишечке вынужден читать тип выражения по спирали а понимание деклараторов превращается в пытку. Очень удобно и интуитивно понятно.
Всякие спирали выдумываются потому, что изначальной идеи авторы спиралей не знают. Вот поэтому и пытка.
А как удобно и думно? Реально интересует
Простейший пример - датаграмма (которые используются много где).
Состоит из заголовка фиксированной длины и структуры + байтового буфера переменной длины и структуры.
Содержимое байтового буфера интерпретируется обработчиком в соответствии с тем, что указано в заголовке (тип датаграммы).
Но на транспортном уровне - все это просто байтовый буфер. Ни содержимое ни структура там не важны. Только размер.
Далеко не каждый тип данных можно таким образом представить в буфере, а потому и далеко не любое сообщение можно получить из буфера с помощью чего-то reinterpret_cast-подобного.
Банальнейший пример - массивы переменной длины в середине сообщения.
Ну а если в общем случае чтение сообщения через reinterpret_cast бесполезно, опасно и вообще не работает - то те частные случаи, которые работают, как раз и являются теми самыми "хитрыми оптимизациями".
Далеко не каждый тип данных можно таким образом представить в буфере
Интересный тезис.
Напомню, что в датаграммых передаются данные, но не объекты (не надо их путать на низком уровне). А любые данные (неожиданно) как-то лежат в памяти и точно также могут быть уложены в буфер и переданы по каналу связи Откуда и куда - не важно - на другую машину через IP каналы, на контроллер по какому-нибудь RS485 или в другой процесс через pipe или локальный сокет.
Суть в том, что любые данные представляют собой просто набор байт. Все остальное - это уже интерпретация этого набора для работы с ним.
В системах, работающих в режимах реального времени или просто высоконагруженных системах обрабатывающих большие объемы данных, вам придется столкнуться с тем, что необходимо думать и о быстродействии и о минимизации потребления ресурсов (памяти, процессора, коммуникационных каналов). И вам придется всесильно снижать накладные расходы везде, где это только можно. И тут зачастую датаграмма в общем виде или ее более формализованный вариант protobuf - тот самый путь который выберет вас (на вы его, а он вас)
Так protobuf же как раз и не использует reinterpret_cast для преобразования массива байт в объект!
Это уже внутренняя конкретная реализация. Работа с protobuf может быть реализована на том языке, где никаких reinterpret_cast нет. И там даже объектов как таковых может не быть.
Речь о том, что вы получаете набор байт с которым потом вам что-то нужно делать. Смысл этого набора байт определяется из информации в фиксированном заголовке. И по этой информации вы уже интерпретируете массив байт как какую-то осмысленную структуру данных. Которая (при необходимости) может стать основной для создания вокруг нее объекта. Или не создания, если это будет нести излишние накладные расходы и вам достаточно просто взять эти данные и как-то их однократно обработать.
Довольно странно говорить о конкретном семействе библиотек в отрыве от конкретных реализаций.
Кроме того, повторюсь, вы не можете преобразовать массив переменной длины посреди сообщения в набор байт через аналог reinterpret_cast.
вы не можете преобразовать массив переменной длины посреди сообщения в набор байт через аналог reinterpret_cast.
почему?
Для начала, потому что в языке нету подходящего типа данных для представления такого сообщения. У структур можно хаком "расширять" массив в последнем поле, но только в последнем.
Кроме того, обычно если с сообщением работают не как с массивом байт - значит, его редактируют. Редактирование массива переменной длины включает в себя удаление или добавление в него элементов. Как это делать сохраняя основное свойство - возможность в любой момент сделать reinterpret_cast всего сообщения в массив байт?
если я правильно понял, то подобные проблемы стандартно решаются дополнительным объектом. т.е. исходные данные лежат не в буфере, а самописном байт-стриме. стрим основан на коллекции блоков разной длины. втыкаете новую дату в новом блоке в любое место стрима и итогом формируете свой буфер из стрима. если надо еще добавить, повторяете операцию обновление стрима-выгрузка из стрима. для 90% случаев, а тем более датаграмм до 64к будет работать шустро. в чем проблема?
По моему опыту, когда объемы данных становятся большими (не единичной датаграммы, но их количества), любая лишняя работа с динамической памятью становится заметна в performance explorer статистиках (и вызывает вопросы "а нельзя ли как-нибудь без вот этого всего" на нагрузочном тестировании). Даже на машинках со 120-ю ядрами power9.
Как вариант, однако написанное вами уже выходит за рамки простого reinterpret_cast.
Для начала, потому что в языке нету подходящего типа данных для представления такого сообщения.
Массив это пара (T*, size_t)
У структур можно хаком "расширять" массив в последнем поле, но только в последнем.
Это никак не относится к задачи
Кроме того, обычно если с сообщением работают не как с массивом байт - значит, его редактируют.
Нет. Я хочу работать рид-онли с разными структурами данных, а не только с байтами.
Банальнейший пример - массивы переменной длины в середине сообщения.
Я, конечно, не language lawyer, но после принятия p0593, если вы сами создаёте буфер, а потом отдаёте в читалку, то всё, что implicit lifetime, по идее, создать таки можно static_cast'ом, не вызывая UB.
Смех в том что приниятие какого pXXX зачастую нетребует изменений в реализации компилятора. Т.е. оно как работало так и работает, просто у стандартизаторов дошли руки это описать.
Время жизни - отдельный вопрос, который и правда можно решить. Проблема в том, что VLA в середине сообщения вы в принципе не сможете представить в качестве структуры.
Напильник для грамотной разработки кода не нужен - нужна культура программирования и структура кода. Как пример, ПЛК в пром автоматике, там языки для контроллера ну проще некуда, но без грамотного подхода будет именно дичь, да такая, что иногда проще переписать, чем разруливать наслоения логики и зависимости всего от всего.
Что вам мешает сделать свой алиас, который будет по вашему "многословные" вещи делать такими, как вам удобно?
Если мы используем 5 подсистем, написанных разными командами в разное время, то мне придётся выучить 5 разных наборов алиасов.
Если мне нужно заглянуть в код сторонней библиотеки, то нужно начинать с изучения их алиасов.
Могут возникнуть конфликты при использовании в коде нескольких библиотек с разными наборами алиасов.
только у языка не эргономика, а семантика.
И семантика, и эргономика. Язык (невольно) поощряет использование более лаконичных конструкций.
Например, в Питоне есть map и фильтр. Но какой вариант будет выбирать программист?
list2 = list(map(lambda x: x * 2, filter(lambda x: x > 5, list1)))
list2 = [x*2 for x in list2 if x > 5]Для примера сравните с Хаскель
list2 = map (*2) $ filter (>5) list1К удобству.
Вообще идея всех этих многобуквенных кастов и была в том чтобы было не удобно и чтобы человек не бездумно писал (T*) и позволял языку вольно кастовать, а подумал пока печатает какой ему каст реально нужен и реально ли надо std::reinterptet_cast или static_cast пойдет лучше. Источник - траст ми бро Дизайн и эволюция С++.
Прочитал первою строку: std::reinterpreprepret_cast<T>( ) демонстрирует полное незнание темы. Дальше время тратить на чтение мнения эксперта не стал.
Про многобуквенность и `std::reinterpreprepret_cast<T>( ) `
Расскажу одну свою историю, мне кажется, она поучительная. Мир С, плюсов и даже асма мне знаком, но вот много лет назад я выбирал, куда развиваться, было два новых интересных молодых перспективных языка программирования. ruby и python. А еще, в те давние времена не было гитхаба (по крайней мере как нынешнего стандарта), зато был freshmeat.net - каталог опен-сорсного софта.
И я должен быть принять важное "инвестиционное" решение. Какой новый модный перспективный язык я буду изучать? Пайтон или руби? Я сделал поиск по проектам на каждом из языков и пришел к интересному выводу: На каждом из языков много разных интересных проектов. Каждый хорош, на каждом можно много что сделать. Но было существенное отличие: на пайтоне было больше "дурацких" проектов, некоммерческих, бессмысленных (по крайней мере в плане монетизации) - таких, которые люди писали явно просто так, для себя, для развлечения, по приколу. Вот у человека свободный день, он может пить пиво или гулять по парку - а он выбирает программировать какую-то фигню на пайтоне - просто потому что это приятно и прикольно! На руби таких проектов было гораздо меньше (по крайней мере, мне так показалось).
Я выбрал пайтон. Не жалею. Да, это удовольствие! Код легко читается и легко пишется. Даже вот то, что "тяжелые" фигурные скобки нужны гораздо реже (а их ведь надо с shift нажимать) - даже это - тоже добавляет плюсик. Мне кажется, python придумали люди, которые не желали отомстить всему миру.
За деньги - люди готовы на многое. Начиная от преступлений и интимных услуг на трассе и до программирования на плюсах и Java. Многие готовы писать код вида `std::reinterpreprepret_cast<T>( )` если им за это будут платить. Но кайф - это то, что ты делаешь, когда тебе НЕ платят, когда ты сам этого хочешь. И на мой взгляд, очень интересный и мозгорасширяющий вопрос - А хочешь ли ты программировать на этом языке сам, просто ради самого процесса? Приятно ли это?
Я просто хотел сказать следующее. Когда я смотрю на все вышеперечисленные вещи, я иногда не сдерживаюсь, и спрашиваю: ребята, да что же вообще творит Комитет?! Ведь это же настоящий — девки-бабы, а ну заткнули уши! — ХАОС.
А мне фанаты модерн-плюсов отвечают: да что случилось? Ничего же плохого не случилось! Всё хорошо, все в восхищении, гости в восхищении, королева в восхищении, а ты (ну, то есть я) идёшь в ж. Я уже начал думать: может, действительно, это со мной что-то не так? Может, это и правда красиво и выразительно, и не вызывает желания повеситься?
А потом Страуструп вдруг проговаривается: оказывается, разработчики такие плохие, что игнорируют это развитие за много-много лет. И не просто игнорируют, а ПОЛНОСТЬЮ.
Так а что вам не нравится в C++17?
std::optional? Который крайне удобен в выражении идеи отсутствия значения?
Нововведения типа copy-elision, которые просто гарантируют, что временные объекты оптимизируются и полностью обратно совместим?
Стринг-вью это поинтер+сайз, никаких сложностей. Инлайн с 17 плюсов имеет смысл, что можно нарушать ODR.
C++14 с мутабельными лямбдами, которые позволяют переносить контекст между вызовами функции. Шаред поинтеры?
Очередное упрощение написания темплейтов через require в C++20? Рэнжи, которые можно просто игнорировать, если не пишете в функциональном стиле?
Корутины пока нигде в реальных местах не видел, можно игнорировать?
Что не так то? О каком хаосе идет речь? Мы же не будем называть C++11 новым стандартом же да?
Расскажите о своем опыте, как то в среднем на хаос в современных плюсах жалуются люди, которые не смогли освоить reference вместо указателя в коде и вообще пишут на си с классами.
Так а что вам не нравится в C++17?
Позвольте мне:
std::optional? Который крайне удобен в выражении идеи отсутствия значения?
Отличная задумка, но не хватает нескольких базовых вещей: оператора or, метода flatten для преобразования optional<optional<T>> в optional<T>>, да даже банальный transform появился только в C++23.
Нововведения типа copy-elision, которые просто гарантируют, что временные объекты оптимизируются и полностью обратно совместим?
Претензий никаких, но забавно, что "самый быстрый язык с zero-cost abstractions" оказалось несложно ускорить.
C++14 с мутабельными лямбдами, которые позволяют переносить контекст между вызовами функции.
Отличная вещь, но некоторые лямбды нельзя вызывать больше одного раза, что к сожалению невыразимо в типе.
хаос в современных плюсах
Код современный до выхода нового стандарта. Если начал проект 8 лет назад, нужно постоянно ковыряться в старом коде, чтобы приводить его в приличный вид и использовать новые концепции, которые позволяют делать старые вещи шестым по счёту способом.
Отличная задумка, но не хватает нескольких базовых вещей: оператора or, метода flatten для преобразования optional<optional> в optional>, да даже банальный transform появился только в C++23.
Я думаю они в с++ не нужны. Подход с++ это if и early return. Другой подход имеет смысл только вместе с другими боле базовыми фичами языка
Нет, скорее потому, что даже эти примитивные стринги гениальные личности не юзают по религиозным соображениям, предпочитая выпендриваться с сырыми указателями. Если вы не сумели применить плюсы для решения задач, то ваши задачки не нуждаются в этом языке, но не нужно кричать о бесполезности)
Какие алгоритмы оформлены как классы? Насколько я знаю весь stl работает через методы. std::sort это вообще-то метод. О каких классах идёт речь вообще?
Касты многословные? Забахайте дефайн или используйте c-style каст. Но вообще, если вам нужно обильно мазать касты в своем коде - вы делаете что-то не так.
Разные типы стрингов... ну... так они для разных целей. UTF-16/32 строки прикажете как хранить? Как однобайтовую строку и в местах применения душиться на тему размеров? Из строки тривиально достается итератор и едет все все алгоритмы стл, вообще не понятно, какое не "ничего" вам от строк надо?
За что следовало бы пинать кресты, так это за зоопарк систем сборок и рокетсайенс подключения библиотек к проекту, а то, что написали вы это какая то вкусовщина.
std::sort это вообще-то метод.
std::sort это вообще-то функция. Методами в C++ называются функции - члены классов. Все алгоритмы в стандартной библиотеки являются функциями.
Совет про "забахать дефайн" и c-style cast в контексте обсуждения уменьшения выстрелов в ногу в 2024г прям как бальзам на душу. А вот с тем, что если в коде много кастов, то скорее всего что-то не так с проектированием, пожалуй соглашусь.
С одной стороны, да, а с другой... Подключаем две библиотеки на C, в одной строка - signed char*, в другой unsigned char*, а код у нас на C++. Пример почти сочинил, потому что проект был на C, но с очень хорошей строковой библиотекой. И вот тут особо ничего не сделаешь. Хотя да, в проекте "что-то не то", просто видно, что именно "не то" - разнобой с типами символов/строк, только в конкретном случае ничего сделать нельзя.
Как сказал однажды Юрий Нестеренко: я в силах Кориолиса, конечно, не разбираюсь, но вот рядом стоит другой дом, и у него стены прямые.
Почему-то в C# есть один тип строк. Вы думаете, программисты на C# не работают с разными кодировками? Или им перфоманс не важен? Или только им нужен IndexOf(String, Int32, StringComparison)? (Поскольку вам «вообще не понятно, какое не "ничего" от строк надо», поясню: это поиск индекса вхождения подстроки с заданной позиции с явно заданным правилом применения культур-мультур). Нет. Это не так.
На практике это приводит к тому, что люди плюют и берут какой-нибудь QString, который делает что-то действительно полезное (хоть и меньше, чем BCL). Проблема в том, что QString не входит в стандарт языка. И когда потом они встречаются с разработчиками другого модуля, где используется какой-нибудь другой стринг, начинаются конверсии, а это приводит к тем самым ошибкам с памятью, про которые эта новость.
Вы можете называть это «вкусовщина», но это источник большой доли ошибок из упомянутых 70%.
QString берут кьютэшники потому что у них весь проект на них завязан.
Искать по подстроке с локалями это действительно сложный кейс и работа с локалями на стандартных плюсах действительно состоит из болей. Но визуально, внутри класса строки это не нужно, а нужно в виде внешней функции. Строка так то, контейнер.
В любом случае, ктют строки совместимы с стл алгоритмами и все умеют.
Но честно говоря я и с QT строками успел поесть, когда звал винапи который WCHAR* кушал.
Как всегда уперлись в то, что лучше делать хорошо, а не хорошо не делать.
П.С. расшифруйте BCL пожалуйста, я каменщик работаю 3 дня.
Почему-то в C# есть один тип строк.
Теперь голову ломают как вкорячить UTF-8.
программисты на C# не работают с разными кодировками?
Конвертациями в православный UTF-16 и сырым byte[], который валидной строкой быть не обязан.
В UTF-16 ничего православного нет. Это ошибка природы, историческое недоразумение.
А других не завезли, полноценная поддержка в языке только у него.
В каком таком языке? Для С/С++ в POSIX мире вполне естественным и стандартом де-факто является UTF-8, в библиотеках ничего переписывать не надо, просто работаем с однобайтовым char как обычно, в целом от ASCIIZ мало что отличается.
А для прям полноценной полноценности (сколько там букв-символов печатаемых в тексте подсчитать и т.п.) есть же всякие libunistring и т.д..
Теперь голову ломают как вкорячить UTF-8
Так методами же! Методами! В какой кодировке хотите строку обработать, тот метод и вызываете. Это же удобно, разве нет?
Не очень понимаю ваших страданий. Кто вам мешает использовать один любимый тип строк и конвертеры к нему, как в вашем любимом C#? На практике используют то, что будет удобнее конкретно для данного проекта. Не можете определиться? )
Кто вам мешает использовать один любимый тип строк и конвертеры к нему, как в вашем любимом C#?
Код, с которым приходится работать на крупных проектах, написан множеством разных команд в разное время. И они почему-то не использовали мой любимый тип строк. То же самое касается и сторонних библиотек, которые используются в проекте.
На практике используют то, что будет удобнее конкретно для данного проекта.
В этом то и проблема. Приходишь работать на новое место и начинаешь учить новые строки, списки, (умные) указатели, контейнеры внедрения зависимостей и так далее... вплоть до разбора xml и отправки почты.
p.s. Возможно, сейчас уже не всё так плохо - я не знаю.
UTF-16/32 строки прикажете как хранить?
Простите, а зачем их хранить в таком непотребном виде? Весь сознательный мир давным давно перешел на UTF-8, ничего лучшего уже никогда не будет. Все остальные древние кодировки сразу на входе (на входе внешних данных) должны быть к utf-8 через какой iconv() приведены, и приложение потом внутри ничем иным оперировать не должно, и выдавать тоже - только UTF-8. Ну ок, для каких Win32 API или RPC можно наверное API врапперов написать, но там просто конвертация на лету в байтовый массив на стеке, хранить это точно не надо.
Может, не стоило вместо List<>.Add() (как у нормальных людей) делать vector<>.push_back()? Может, не стоило алгоритмы оформлять как классы (!!!), вместо того, чтобы инкапсулировать как часть коллекций?
Какие забавные глупости. Что-то всерьёз комментировать тут - только портить.
А ведь 17 плюсов, я даже прикинул, что может быть накрутка от антиплюсового картеля, но быстро одумался.
Я как-то не понял, что это резво так все правительство США пришло С++ закапывать? Может грант какой под капотом можно распилить? Или разработчики раста стали очень уж рукопожатые?
Очень научно, Джерри.
может, не стоило вместо
List<>.Add()(как у нормальных людей) делатьvector<>.push_back()?
Ну, STL появилась в 94ом, а первая версия джавы с List<>.Add() - в 95ом, допустим.
от этого только больше вопросов как имея STL в качестве примера можно сделать такой ужас как List<>.Add()
А MFC появился в 1992-м. И там был и нормальный стринг, который умел всё, о чём только можно было мечтать в 92-м году, и .Add(). Правда, List там назывался CArray, но вот это комитет и мог бы пофиксить. Да и то, если выбирать между CT и T_t, я выбираю первое.
Что плохого, что язык не ограничен одним лишь решением? Напишите свой add
30 лет развития C++ - это когда вместо std::string doit(std::string param); нужно писать [[nodiscard]] constexpr auto doit(std::string_view param) noexcept -> std::string;
Неа, 30 лет назад все юзали using namespace std и получали нормальный человекочитаемый код
string doit(string param)
30 лет развития С++ это когда если вам не нужно, то вы можете продолжать писать std::string doit(std::string param); и оно будет работать не хуже чем 30 лет назад.
Да, конечно, зря я опустил вполне очевидное "если вы хотите писать на современном C++, отказавшись от устаревших практик", ведь это как раз то, о чём говорит Страуструп: пишите на современном С++, давайте компилятору больше информации для анализа кода.
Никакие современные практики не обязывают вас писать ничего из того, что вы там привели в пример.
Если вы хотите современный производительный код, писать-таки придётся.
Раскажите как nodiscard, constexpr и traling return влияют на производительность?
nodiscard позволит не оставить висячих вызовов функции, constexpr - перенести часть вычислений в компайлтайм (начиная с C++23 его имеет смысл ставить практически в каждой сигнатуре, синтаксический кошмар!). trailing return на производительность, конечно, не влияет в этом случае, но улучшает читабельность и вполне может понадобиться для консистентности стиля в проекте.
то есть никак
constexpr - перенести часть вычислений в компайлтайм
const propagation оптимизация работает и в си без всяких constexpr
Сообщите в комитет C++, что они что-то лишнее придумали.
Если вы не знаете что делает constexpr то следует ознакомится с документацией прежде чем писать чушь в комментариях. Заодно узнаете про consteval.
Я правильно понимаю, что вы утверждаете, что constexpr не является инструментом, потенциально позволяющим проводить часть вычислений в compile-time?
Ключевое слово "потенциально". Просто мазать constexpr везде смысла мало. Современный С++ даёт возможность специализировать поведение программы для разных данных через метапрограммирование и constexpr как его часть. Но для этого нужно писать соответсвующий код. Мы рассуждаем в контексте других языков, где таких возможностей попросту нет. Значит сравнивать надо с С++ кодом в котором так же эти возможности не задёствуются, и лишние кейворды вроде constexpr/noexcept не возникают.
Единственное, что там более-менее обозримо влияет на производительность это тип параметра, но дописать & или * можно было испокон веков. noexcept должен дать чуть меньший размер бинаря и, в теории, в исключительных случаях будет работать быстрее, но я не уверен, что эту прибавку можно будет измерить.
30 лет развития C++ - это когда вместо
std::string doit(std::string param);нужно писать[[nodiscard]] constexpr auto doit(std::string_view param) noexcept -> std::string;
Это надо зачитывать актёрам на репетиции «Ревизора» )))))))
Произнесенные слова поражают, как громом, всех. Звук изумления единодушно излетает из дамских уст; вся группа, вдруг переменивши положенье, остается в окаменении.
Немая сцена.
Когда я открываю проект на C#, я обычно вижу там обработку png, или генерацию веб-страниц, или ещё что-то полезно-прикладное. Но как ни открою проект на модерн-плюсах, так половина кода оказывается вот таким вот говном вещью в себе, нужной самой по себе и для себя. Потому что автор такой: смарите, посоны, как я могу!
Если играть в дурацкие игры, то можно и вдвоём: когда я открывают проект на C#, я обычно вижу там internal sealed partial class SuperClass : IInterfacable static public get set. Какая-то вещь в себе, нужная сама себе и для себя.
Вы правила игры неправильно понимаете. Я же не придумываю чушь поразвесистее (как вы), я просто показываю пальцем на реальный код, которым люди гордятся. Один пример выше. Другой пример: https://habr.com/ru/articles/798929/ https://web.archive.org/web/20240308160403/https://habr.com/ru/articles/798929/. (Это статья, как перебрать члены enum'а — раньше мы добавляли в конец enum'а Last, и всё, итерировались от 0 до Last, а теперь нам предлагается сорок бочек арестантов, и необходимость добавлять в enum не только Last, но и First). Это я из недавно прочитанного взял. Ещё? Я могу просто ткнуть по тегу C++, и набрать оттуда сколько угодно примеров с лютой упячкой. Половина статей как раз на эту тему: «смарите, посоны, как я могу!».
Вот и вы так же: возьмите не выдуманный код, а ткните пальцем в реальный. Для начала приведите, пожалуйста, хоть один реальный пример, а потом мы уже перейдём к их количеству.
Я же не придумываю чушь поразвесистее
Иронично, но я ничего не придумывал. Я буквально загуглил github c# projects, взял из выдачи "Trending C# repositories on GitHub today", тыкнул на самый первый DevToys-app, залез в src->app->dev->DevToys.Core и выбрал Settings как выглядящее нейтрально и понятно. Там есть несколько файлов исходников, откуда я это и вычитал. 20к+ звёзд, в трендах, реальный код, которым, уверен, создатели гордятся.
P.S. там ещё перед этой лапшой есть [Export(typeof(ISettingsProvider))], которое я сюда копировать не стал.
там ещё перед этой лапшой
Речь не о том, насколько понятен код незнакомому с языком. Речь о назначении кода. О том, какая его часть предназначена для решения стандартных задач (например, свой класс для строк), а какая для решения конкретной задачи, поставленной автору кода.
Например, я встречал успешных С++ программистов, которые принципиально не использую STL, потому что "там г. и можно написать лучше".
В этом и сила с++, что можно написать лучше. В с# жрешь то говно что дали.
Зато коллеги не охотятся за тобой с топором, а бывший работодатель не поминает коротким злобным словом.
Эм.. а что если там просто из коробки уже написано достаточно хорошо?
Но даже если и написано из коробки плохо, то все равно ничего не мешает написать свою реализацию, если так уж сильно нужно.
Если прям очень сильно нужно, то можно её написать с использованием unsafe кода.
Всё тоже самое применимо и к плюсам. Также как в шарпе все эти internal sealed partial class вместо class пишутся не просто по приколу, так и в плюсах все эти [[nodiscard]] constexpr noexcept пишутся не по тому, что кому-то стало скучно.
как vector<>.push_back() соотносится с проблемами утечек памяти? это просто более трудночитаемая и понимаемая конструкция шаблона. ваше фи - не по теме, хотя мнение имеет место быть.
по теме он сказал все правильно: используйте ссылку и тип автопоинтер вместо обычных поинтеров, применяйте raii (погуглите примеры кода, что это) где возможно - и будет вам безопасный код.
от себя добавлю еще пару вещей:
1) выделять и освобождать динамическую память для объектов нужно через паттерн проектирования фабрика или фабричный метод. они могут подсчитывать размер выделенной памяти и при своем закрытии сигнализировать об утечках, если что-то к этому моменту не успело освободиться. т.о. утечки памяти ловятся уже на этапе разработки. что предотвращает ошибки типа out of memory и исчерпание хендлов.
2)raii нужно использовать в том числе для механизмов блокировок в памяти. т.е. зашел в скоп программы - raii инициировала блокировку (если надо здесь). вышел из скопа - блокировка сама снялась.
3) пример ms показывает, как можно уйти от разных cast в с++. смотрите как работает метод iunknown.QueryInterface. он прекрасно работает на получение ссылок для разных интерфейсов (классов). нужные классы (в составе одного объекта) имеют динамическую типизацию и выгребаются по запросу с параметром типа.
ключевые слова - применение динамической типизации, которую так любят отключать компиляторы.
4) каждый метод должен проверять свои входяшие параметры. тогда не будет взрывов в тех методах, где exception не предусмотрены, в принципе. как пример - сейчас многие функции winapi генерируют исключения при неверных параметрах, вместо возвращения обычного hresult.
этих рекомендаций достаточно для того, чтобы иметь стабильный код. однако, зачем вникать в тонкости, когда можно перейти на rust... и оставить в коде все те же проблемы с дедлоками, о чем и сказал Страуструп. ну потому что rust проблемой блокировок не занимается😁
Погодите, но всем этим барахлом можно же не пользоваться!
Мне кажется, что Страуструп так и не осознал, что безопасность - это не когда легко можно сделать хорошо, а когда сложно сделать плохо. И не стоит с таким высокомерием судить об авторах предостережений, а лучше задуматься, что же всё же он сам делает не так.
C и C++ не зря ставят вместе - их объединяют из-за почти полной совместимости сверху вниз, каковая и предоставляет широкие возможности для стрельбы себе в ногу. Линтеры и статические анализаторы - это прекрасно, но даже если они настроены так, чтобы не пропускать небезопасные техники, нет никаких гарантий, что они применены - это опциональные инструменты, а значит - зачастую не будут использованы.
Современные синтаксические конструкции - это хорошо. Но надёжности не будет, пока устаревшие не станет невозможно или сложно использовать (например, если их придётся оборачивать блоком типа OBSOLETE_SYNTAXIS наподобие растовского unsafe). Я так вижу.
Мне кажется, что Страуструп так и не осознал, что безопасность - это не когда легко можно сделать хорошо, а когда сложно сделать плохо.
Золотые слова. Чтобы сделать безопасный C++, придётся сделать обратно несовместимый со всеми предыдущими реализациями язык. Но тогда зачем его называть C++, можно как-нибудь по-другому назвать, например C# или Rust
А можно назвать его как-нибудь типа safeC++. Которым он и будет являться.
Или добавить еще два плюсика и получится C#
Или взять следующую букву алфавита и получится D. Который типа и является "безопасным С++", правда, не таким безопасным как Rust.
Или cppfront
А по-моему, безопасность языка заключается не в невозможности натворить много бед, а в вероятности. Например, возьмём сишечку 20 летней давности и любой "песочный" язык, например, ту же Яву. Ява, конечно, сознательно ограничивает именно сложностью низкоуровневой работы с памятью, но всё же получить уязвимость типа переполнения стека куда ниже, чем на первом - там указатели и массивы, и границы никак не проверяются, это программист должен внимательно следить и не тай пох ошибиться на единичку, чтобы в случайном сегменте затереть что-то критически важное. А ещё возьмём менее очевидные плюшки некоторых языков, такие как nullable types и иммутабельность - сначала кажется, что от этого не очень много выгоды, а потом оказывается, что программа реже падает, потому что мы загнали null/void туда, где его никогда не хотим видеть; а иммутабельность, хоть и повышает использование памяти, но в обмен получаем более целостное состояние. Тут, главное, не перестараться, а то вот создатели Явы однажды эпично попали с проверяемыми исключениями - или обработай или пробрось. Но это оказалось настолько утомительным, что много гениев просто оборачивали исключение пустым обработчиком, т.е. эффект получился обратным. Или вот совсем неочевидная штука, как отсутствие неявных кастов даже в случае расширения типов: тоже сначала кажется, что это излишне, но потом оказывается, что это оберегает от широкого класса ошибок. Тут же вспомню и отсутствие UB - тоже полезная штука, когда код работает всегда так, как написан, а не шаг влево, шаг вправо - и как повезёт, сначала всё хорошо, а потом рванёт. Да, сюда ещё хороши и встроенные средства работы в многопоточной среде, ибо без них и софт становится дырявым, и дебаг очень сложным занятием.
Т.е. безопасность - это не невозможность натворить бед, а помощь не натворить их на ровном месте. Чтобы или компилятор орал, что здесь что-то не так, или по коду сразу видно, где ошибка - без требования супервнимательности и спец.знаний о том, что делать так, как кажется логичным - нельзя. (из нелогичного можно вспомнить equals из джавы или switch case где обязательно надо ставить break) специальные знания - это, из той же джавы - volatile для корректной работы полей в многопоточной среде, или что самые известные коллекции потоконебезопасные, и нужно знать про потокобезопасные.
Так что безопасный язык предлагает соответствие предположений с реальностью и интуитивно читаемый код (т.е. чтобы ошибку можно было найти, пробежав глазами код, а не после суток непрерывного дебага). А также безопасный язык больше проверок берёт на себя, не заставляя программиста держать в голове знания о потенциальных засадах. И, например, пусть при нарушении границ программа сразу падает, а не тихонько натворит и продолжит работать.
С этой точки зрения небезопасны даже такие языки, как php, который, например, позволит работать с несуществующим файлом, попутно засирая лог (не так давно это был браузер); небезопасен и даже он же или javascript, оба позволяют неявно кастить почти что угодно, и потому получается, что "2"+2 это 22, а 2+"2" это 4 - форменное свинство.
А если я думаю, что я крутая и хочу напрямую работать с памятью - пусть язык не запрещает мне это делать, но и не требует (опять привет указатели), тут уже сама лезу.
А потому я вряд ли для обычного проекта выберу С/С++ - слишком утомительна необходимость быть ооочень внимательной в мелочах - безопасносные языки берут это на себя, и это хорошо.
Точно
Вот из-за таких непродуманных решений и невозможности переделать язык не сломав совместимость и не хочется писать на срр
Самый прикол, что плюсы и не требуют ни от кого работать с памятью, там давно есть весь набор, чтобы не делать этого вообще. О какой совместимости вы пишете, если стартуете новый проект?
Вы напомнили анекдот, которому лет уж точно больше, чем нам с вами.
Приходит Рабинович устраиваться на работу в советское учреждение. Начальник мнётся, мычит, в общем — видно, что не хочет брать (борьба с космополитизмом в разгаре), но и отказать неудобно.
— Да вы не переживайте так, я же русский на самом деле!
— У-у, ну тогда ступайте себе. С такой фамилией я уж лучше еврея возьму.
Если уж начинать новый безопасный проект, то зачем брать C++?
Ваш подход к выбору языков программирования, а особенно суждение и "безопасности" напоминает одну известную поговорку... Там про стеклянный предмет. Я бы спросил, как вы умудряетесь в плюсах без указателей руки порезать, но зачем )
Я бы спросил, что вы знаете о моём подходе к выбору языков программирования и откуда...
Если указатели не нужны, то зачем нужен C++?
"Если уж начинать новый безопасный проект, то зачем брать C++? "
Вот тут ваше суждение. Напоминаю, если забыли.
Ну и прекратите позориться уже своими познаниями. Представляете, в современных плюсах с динамической памятью работают БЕЗ указателей. Исключением пока что является Qt, где есть своеобразная сборка мусора.
Да, у плюсов куча минусов, но у кого их нет? )
Вы как-то очень странно читаете текст. Я разве где-то писал, что на C++ невозможно писать, не используя указатели? Наверное, можно, верю вам на слово. Но зачем? Без указателей можно и на других языках писать.
Да нормально читаю. Расшифровывайте свои мысли, если смысл отличается от очевидного. Вот ваш же текст
"Если указатели не нужны, то зачем нужен C++? "
Я предположил, что вы имеете ввиду вообще не работать с динамическим выделением памяти. Если нет, то похоже на какое-то извращение: хочу работать именно с указателями, а потом говорить, какой он небезопасный.
На ваше зачем есть контраргумент: а зачем на других, если можно на плюсах? )))
Язык выбирают исходя из специфики проекта, а не так, чтоб в резюме строчка покруче была )
Э-э... то есть по-вашему «указатели» равносильны «динамическому выделению памяти»? Это мягко говоря не так. Под словом «указатели» я понимаю именно указатели, а если вам в этом слове очевидно что-то другое, то тут я бессилен.
На ваше зачем есть контраргумент: а зачем на других, если можно на плюсах? )))
Ну в принципе да, аргумент принимается. Но знаете... я когда-то давно писал на плюсах, а вот на Java не написал ни строчки. Но когда я вижу какие-то примеры на современной версии C++ и на Java, то Java намного понятнее. Поэтому выбор C++ и кажется мне странным. Хотя Java тоже, мягко говоря, не идеальна.
Вы юзаете указатели без динамической памяти? Да вы интересная личность. )
Я несколько раз переписывал с явы на го, плюсах или шарпе. И во всех случаях понятность зависит прежде всего от того, кто писал проект, а не от языка. Если я на плюсах напишу завёрнутые шаблоны, да ещё и с SFINAE, да, никто код не разберёт. И это решают, медленно, но решают. Есть концепты, а вьюшки - так и вовсе фантастика. Проблема тут в том, что стандарт языка принимает комитет, а не какой-то один мейнтейнер.
По простоте и концепциям мне, например, очень нравится го. Но вот мне однажды понадобились ordered мапы... И там таких болей много. Но для своих целей отличный язык.
там давно есть весь набор
Да ну? Что прям и нормальный сборщик мусора "из коробки" имеется? Потокобезопасный и с графом, а не на подсчёте ссылок?
Дайте два!
Вроде в qt есть gc, но что там у него с безопасностью на потоках не вкурсе
Я не очень понял, зачем вам сборщик мусора при использовании стандартной библиотеки (буста, qt и тд). Где именно у вас мусор остаётся?
Вы про графы что-нибудь слышали?
Неужели специфика построения графов такова, что ведет к неконтролируемой генерации мусора?
Нет, это такова специфика тяп-ляп разработки. Никогда не знаешь где твой коллега оставил лишнюю ссылку и не замкнула ли эта неучтённая ссылка цикл из объектов.
Не всегда, далеко не всегда можно во время написания кода построить остовное дерево графа для будущих данных. Модель MVC как пример. Да и weak_ptr это костыль на обе ноги так-то.
В MVC как раз всё просто, и даже слабые ссылки не нужны: у V есть свой жизненный цикл, и в нём есть момент когда компонент уходит с экрана. В этот момент нужно отписаться от соответствующих M, что разорвёт ссылки от M к V.
Гораздо больше проблем возникает не в самой MVC, а внутри каждой из этих трёх букв. Особенно связи M -> M опасны.
А зачем вы делите MVC на слои? В памяти то у вас всё в одном клубке. Двусвязные отношения многие-ко-многим как между M, V и C, так и внутри них. Изменилась какая-то моделька, она должна оповестить все вьюхи, в которых отображается. А ещё в реальном софте обработчики у вас будут в отдельных потоках, и запускаться не только из вьюх.
Удачки тут построить и потом поддерживать spanning tree на этапе программирования.
В смысле - зачем? Зачем я делю MVC на M, V и C? Ну так в том же и суть паттерна, разве нет? Или вы вообще про что спрашиваете?
Изменилась какая-то моделька, она должна оповестить все вьюхи, в которых отображается.
Ну да. И это правильно, поскольку что отображаемые на экране вьюхи, что отображаемая в них модель совершенно точно живые и должны быть в памяти. А когда вьюха уйдёт с экрана - она должна отписаться от модели, что разорвёт любые циклы в которые эта вьюха входит.
она должна отписаться от модели
И если это была последняя вьюха, то вы приходите к печально знаменитому
delete this;
Я просто участвовал в большом проекте, где на подобных соплях всё было построено. Там не только M, V и C, там ещё бывают исключения с логгерами и т.д. и т.п.
Врагу не пожелаю отлаживать многопоток.
Э-э-э, зачем сразу delete this;-то? С чего бы вообще время жизни модели зависело не от количества ссылок на неё, а от количества подписок? Мы ж shared_ptr обсуждаем...
И в чём тут проблема с многопоточностью - тоже непонятно.
Потоки здесь при том, что shared_ptr не atomic, а даже если брать атомик версию, то он атомик только сам по себе, и более сложные изменения в модели без дополнительных приседаний он не чинит.
Циклы могут проходить не только через вьюху, но и через что угодно, контроллеры, БД, просто модели сами по себе могут иметь циклы. И инструментом для дерева, которым является shared_ptr, это не разруливается.
(На расте, если что, это специально сделано явно и очень больно. Раст - лучшая реклама gc, какую только можно придумать!)
Ну так я сразу же и написал, что связи M -> M - это да, это может быть больно. А вот любой цикл, проходящий через V, разорвётся когда этот V закроется (по крайней мере, должен разорваться при правильной реализации).
Да понятно что не сама БД, а коннектор к ней. Если он асинхронный или неблокирующий, то в нём могут быть указатели на ваши модели в процессе исполнения запросов.
Да-да, в каком-нибудь OLTP, OLAP или там в модном IoT соединение с БД закрыто или висит в пуле:)
А, я кажется понял. Не всем программам от БД нужен только CRUD. Бывают ещё всякие транзакции, хранимые процедуры и прочее. И пока транзакция не закоммичена, все участвующие в ней обьекты-модели "подвисают".
Ну мир не ограничивается только UI и отчетами. У нас вот >80% сводится к тому, что формируется поток данных (как правило, это выборка из БД в которой может быть десятки миллионов (и более) записей, каждая из которых обрабатывается в соответствии с бизнес-логикой задачи и уходит обратно в БД (так или иначе).
Что прям и нормальный сборщик мусора "из коробки" имеется?
А вот интересная тема про мусор и его сборку. И вот (когда в основном работаю с языками, работающими в виртуальных машинах - естественно, со сборкой):
Чем хороша и чем плоха идея уничтожать объект сразу, как только выполнение выйдет за пределы его объявления (выше, не ниже)? Обязательно ли, чтобы в довесок к основной программе прилагалась целая виртуальная машина, которая бы не сразу уничтожала объекты, а тогда, когда ей захочется?
п.с. идея создавать и вручную удалять объекты тоже так себе.
п.п.с.: о ручном управлении памятью, как вспомню, так вздрогну: хочешь создать новую сущность? сначала посчитай, сколько тебе потребуется памяти, выдели её, потом передай отдельно и начальный адрес (естественно, виртуальный) и отдельно (!) размер; при переполнении буфера случится либо затирание чего-то либо обрезание без намека на это - даже если есть намек на возврат значения сколько памяти надо было бы, это ещё самостоятельно проверять... это я уж не говорю, что надо уничтожить выделенный буфер - тогда, когда захочется, иначе , всё будет "хорошо", просто памяти становится всё меньше и всё работает медленнее. Да ну, нет! Просто, создали объект, внутри его обработали, дальше он уничтожается, если не был скопирован куда-то.
Вот чем плохо? Ато так и получаются программы, которым, а принципе, достаточно и условно 1Мб для работы, но постепенно для них и 64Гб становится мало... Ну и плюс, конечно, отдельная обслуживающая ВМ тоже хочет кушать.
Язык для проекта выбирается исходя из потребностей, включая наличие сторонних библиотек и возможностей интеграции с другими языками. Внимательность в мелочах требуется при использовании любого языка, если пишете что-то сложнее hw, ибо ни один язык не будет думать за вас. Исходя из ваших рассуждений, хотелось бы спросить, а когда вы юзали плюсы последний раз, что вам приходится работать с памятью напрямую? я почему-то не делаю этого уже очень давно
С этой точки зрения небезопасны даже такие языки, как php
А что значит "даже такие"? PHP, JS и С - это самые известные языки со слабой типизацией. Они все по определению небезопасны.
из нелогичного можно вспомнить equals из джавы или switch case где обязательно надо ставить break
Ну, тут вы загнули, конечно. Метод equals() нужен потому, что объекты нужно как-то сравнивать, а механизма перегрузки операторов в джаве не было отродясь. Если бы вы сказали про отсутствие этой перегрузки, я бы с вами согласился, а так – хороший инструмент в рамках правил самого языка(напоминаю, что оператор сравнения сравнивает объекты на эквивалентность, то бишь сравнивает хеши, а метод equals() сравнивает объекты так, как нужно вам).
Но вот насчет switch case и break я с вами соглашусь... но дело в том, что во многих сиподобных языках дело обстоит точно так же. Во всяком случае, в плюсах и си все идентично. Но даже так, в джаве есть альтернатива – вы можете вызвать лямбду в кейсе, и все будет работать. Если вы не поняли, о чем я, вот пример:
switch (param) { //стандартный вариант писать кейсы
case value:
//some code;
break;
}
switch (param) { //вариант через лямбды
case value -> {
//some code;
}
}Вот о чем я говорю. Хотя, я могу согласиться, что это неочевидно и требует знаний некоторых тонкостей языка, но я считаю, что это, внезапно, проблема не языка.
Это проблема учителей этого языка и программистов. Если они сразу начнут учить писать код по-новому, безопасно, а не пихая в голову нормы устаревшего си, то сюрприз, багов будет меньше, а код станет безопаснее.
Чтобы сделать безопасный C++, придётся сделать обратно несовместимый со всеми предыдущими реализациями язык. Но тогда зачем его называть C++
"Плюсстопиццот", как говорится.
Есть С. Кому-то он нужен. Где-то. Зачем-то. Оставьте его, не трогайте (ну по крайней мере то, что лежит в основе его идеологии)
Первые реализации С++ были как добавление объектности к С. "С с классами". Отлично. Кому-то это нравилось. В т.ч. и обратная совместимость с "чистым С" Оставьте, не трогайте.
А все эти "...цтать лет развития" выделите в отдельный язык. Забудьте про С и обратную с ним совместимость. Выкиньте все старое наследие и не мучайте себя и всех остальных.
Если вы строите сверхзвуковой реактивный самолет, не надо пытаться сохранить в нем поршневой двигатель и планер от биплана.
Выкиньте все старое наследие и не мучайте себя и всех остальных.
Это и произойдёт через какое-то время. Но прежде чем это произойдёт, новые подходы должны быть обкатаны, осознаны и пойти в массы. Старые подходы будут вызывать предупреждения, потом ошибки без специального режима компиляции или каких-то обвязок и так далее.
Но тогда зачем его называть C++, можно как-нибудь по-другому назвать, например C# или Rust
Так уже были попытки. D, Vala, Cyclone, C-- какой. Это все не взлетит даже по той простой причине, что просто некому допиливать VS Code и GDB/LLDB.
На самом же деле там нужно лишь немного доработать сам С++ (разрешить перегружать оператор точка и еще пару вещей), ну и заново реализовать всю библиотечную часть, и наступит счастье, никакой Rust и Swift будет не нужен.
C# не проходит кастинг по причине бельзальтернативности GC коллектора, да и там и так уже давно over 9000 базовых класов в Runtimе (40513 in 3.5SP1), их теперь остается только выбросить, жизни не хватит даже перечитать это API великолепие .
Пока вам кажется, я более чем уверен, что Страуструп осознал намного больше, чем неизвестный комментатор на Хабре. Весь этот опыт современных языков, якобы надёжных и безопасных, говорит о том, что они не работают. Есть программа, написанная в 2006 году, она стоит 3000$, она работает, она не падает, она работает в критически важной отрасли, соответствует стандартам безопасности, и ее ещё никто не взломал в 2024 году, поэтому она до сих пор стоит 3000$ и не валяется на Рутрекере. Написана она на древнющем c++ безо всяких ваших умных указателей и прочих финтов. Зато весь современный софт, написанный на расте или каком-нибудь голанге обновляется каждую неделю (ой мы тут подправили, тут убавили, мы обнаружили уязвимость, вот тут ускорили). Это я не сравниваю преимущества синтаксиса или системы сборки якобы более эффективного модернового япа. Сколько я не смотрел, на расте в 2024 году не решили проблему зависимостей при сборке(раз язык новый, современный, они учли весь негативный опыт прошлого)- я в языке 2024 года вообще не хочу зависимости, я хочу из коробки понятный синтаксис(потому что простота и ясность - это основа грамотных программ, не содержащих ошибки), и я не хочу думать как мне собрать программу и где шарить библиотеки(пусть всё уже будет в std, мне без разницы, сколько весит папка с компилятором 100мб или 10гб, я думаю это можно пережить в 2024 году) я хочу сделать rc program и радоваться жизни. Но всего этого, увы - нет.
Штаты тупо собрали статистику взломов, получили статистику по языкам исходных кодов модулей с уязвимостью, и поняли, что чинить дороже чем заново писать. Коммерческий выпуск ПО всегда имеет соблазн пренебречь безопасностью.
Но всего этого, увы - нет.
Как же я рад, что всего, что вы указали нет в Rust да и в других языках тоже.
Вот прям стало интересно, что это за программа за 3К и которую с 2006 еще не сломали? Какой-то уж очень специфичный софт?
Какой-нибудь модуль в CAD который нельзя скачать, не подписав NDA, поэтому и не сломали. Я часто слышу такое передёргивание. А вот чтобы развитие программы считали признаком отстойности - это впервые.
Это какое-то когнитивное искажение - мол, если не выходят обновления для программы, то в ней нет багов, а если обновления выходят часто - то программа полна багов.
Если программа работает так, как заявлено и без разных "побочных эффектов", то можно считать что в ней нет выявленных багов. В такой ситуации что-то в ней менять зачем? Добавить новые фичи? Да, если это надо. Если нет - то зачем трогать то, что работает?
Вот работаю в банке. Развитие ЦБС (центральных банковских систем - все, что работает на центральных серверах - АБС и т.п.). Есть куча программных модулей, которые работают по 5-10 лет уже. Они просто работают и исправно выполняют свои функции. И никто не станет их трогать просто так. Только или есть требуется изменение логики, или обнаружено нештатное поведение (дефект промсреды).
Что-то менять просто так очень дорого на mission critical уровне любое изменение кода требует полного цикла регресс-тестирования. А это время и ресурсы.
Есть куча программных модулей, которые работают по 5-10 лет уже. Они просто работают и исправно выполняют свои функции
Знаю. Работал с такими. И с таким программпм5, обычно, прилагается толстый документ ошибок и WA как их обходить.
И эти ошибки годами не правятся. Потому как на их наличие уже кто-то где-то завязался случайно и теперь это фича-баг.
И эти ошибки годами не правятся.
У нас нет. Любой дефект промсреды имеет приоритет над любой проектной задачей. Потому что его наличие очень дорого может обойтись банку во всех смыслах (прямые убытки, репутационные убытки, привлечение лишнего внимания регулятора с потенциальными штрафами и т.п.).
Так что никаких
толстый документ ошибок и WA как их обходить
тут нет. Или оно работает, или заводится дефект и вносятся исправления.
Так у вас и обновления выходят. А обсуждались-то священные неизменяемые артефакты из прошлого...
Человек пишет два утверждения:
1) Если проявляются дефекты, то они исправляются.
2) У них есть программные модули, которые работают 5-10 лет исправно.
Как эти два утверждения друг другу противоречат?
В системе работает несколько десятков тысяч программных объектов. Какие-то работают годами без изменений ("священные неизменяемые артефакты из прошлого"). Какие-то изменяются по необходимости (обнаружен дефект или потребовалось изменение бизнес-логики). Какие-то добавляются (появилась новая бизнес-логика, новые бизнес-процессы).
Там такая примерно логика: если не выходят обновления - значит программа идеально решает свою задачу, достигла пика идеальности и не требует улучшений. И не имеет критичных багов. Потому что обновления ведь не только из-за багов выходят, но из-за фич) Но мне кажется, что это очень странный способ оценивать качество приложения.
А не путаете "развитие" как появление новых фич с латанием дыр в том что уже есть?
Есть проекты с дорогой доставкой. Сколько времени занимает накатить патч на вашу банковскую программу, если делать всё по регламенту, включая тестирование?
Есть проекты с дешёвой доставкой. Условно какай-нибудь веб-сайт. Поменял, за 1 час проверил, за 5 минут накатил патч. Если плохо проверил, то не беда - сейчас быстренько всё исправим. В таких проектах новые фичи (большие и маленькие) могут быть каждую неделю и даже чаще.
Если в банке ошибка ПО - это ЧП, то в проектах другого типа может быть дешевле накатить и исправить, чем очень тщательно проверять.
Банк ещё ладно. А вот какие-нибудь умные лампочки с дырой в прошивке - тут часто дешевле купить новые лампочки, чем перепрошить старые.
Вы правы на 100%. Все упирается в цену ошибки. Или клиент не может на маркетплейсе зарядник для телефона купить, или у крупных корпоративных клиентов миллионы непойми куда уходят...
В нашем цикле (обобщенный случай)
Согласование бизнес-требований
Разработка архитектурного решения
Разработка ТЗ
Разработка кода
Компонентное тестирование
Бизнес-тестирование
Нагрузочное тестирование
Интеграционное тестирование
Внедрение
п.4 занимает (обычно) меньше всего времени (бывают исключения но не часто), а пп. 5-7 самые длительные и часто связаны с доработками и правками кода.
При этом ситуаций
Если плохо проверил, то не беда - сейчас быстренько всё исправим.
у нас не припомню. Да, бывают дефекты промсреды, но они вылезут нескоро и обычно связаны с какими-то сильно нестандартными и редко встречающимися ситуациями. А чаще всего это дефекты производительности промсреды - пока было 20млн клиентов все было хорошо, а когда их стало 50млн уже производительности стало нехватать и потребовалась оптимизация. Но тут годы могут пройти прежде чем вопрос встанет ребром.
Вам никто не мешает использовать rustc напрямую, скачав нужные зависимости вручную или по сишной привычке написав велосипеды, и использовать их без каких либо обновлений. Только зачем?
Вашу программу до сих пор не взломали только потому что она массово никому не нужна. А компаниям из критически важной отрасли очевидно проще её купить, чтобы по документам провести и поддержку какую-то получить на всякий случай.
Но от прямоты рук программистов тоже многое зависит. Поэтому сейчас, когда профессия программиста стала массовой, а кол-во хороших программистов особо не увеличилось, тем более неразумно использовать C++
Кто вам такое сказал, что она массово никому не нужна? Сами придумали?) Покупают ее не ради "по документам провести", а потому что от неё зависит бизнес, и она приносит деньги. За 10 лет работы разработчиком, я вижу сотни тысяч разрабов, которые почему-то со уверены, что бизнес не сможет без их CRM, систем управления персоналом, без веб-сайтов, без ещё какой-то кучи бесполезного софта. Если этот софт перестанет работать или исчезнет - бизнес это не заметит, где-то придется изменить привычный ход вещей, кому-то переучиться, но бизнес продолжит работать. А вот если сломаются те программы, о которых я говорил: всё, всё встанет. Это такие вещи как скады, системы автоматизации и диспетчеризации, скуд, видеонаблюдение, СУБД, контрольно-кассовое оборудование, системы строгой отчётности, кады и т.д. И этих прикладных областях никто не будет менять с++ на всякие модерновые язычки, потому что незачем. А весь тот софт, который я не перечислил, который пишется сегодня на самых новых япах, на последнем с++ - он постоянно обновляется, постоянно какая-то гонка, баги, фичи, фичи, баги, доработки. И оно нихрена не приносит деньги.
Кто вам такое сказал, что она массово никому не нужна?
Просто мы знакомы с анекдотом про неуловимого Джо
Да, бизнес постоянно платит кучу денег за фичи и багфикс в софте, который не нужен и не приносит денег, вот такие все дураки, а вы один очень умный.
Это невероятно, "сотни тысяч" это же в 4 порядках от населения земли.
Сколько из них одновременно являются программистами, писали хотя бы раз свою CRM и при этом считали что именно их CRM не заменима...
Как минимум
У вас на входе фильтр на повторяющиеся элементы не отрабатывает
И ... похоже вы встретились с каждым существующим программистом на земле
Но надёжности не будет, пока устаревшие не станет невозможно или сложно использовать (например, если их придётся оборачивать блоком типа OBSOLETE_SYNTAXIS наподобие растовского unsafe).
Но это будет не С++ уже. Плюсы и си до сих пор активно используются там, где важна скорость, а часто безопасность получается жертвованием скорости. В итоге получится ситуация когда половина использует Python2 preSafeC++ другая половина Python3 safeC++, никто не может определиться какая версия более правильная, две версии развиваются параллельно и вообще всё становится только хуже.
Мне кажется, с каждым годом ниша языков для "сделать быстрый код в ущерб корректности программы и скорости разработки" постепенно уменьшается. В 70-ых, когда делали Си, это было необходимым условием, потому что иначе программы просто не работали за разумное время.
Сейчас в моде "тяп-ляп и в продакшен", да и компиляторы других языков неплохо подтянулись. С другой стороны, программисты сейчас намного больше времени читают, отлаживают и поддерживают код, чем собственно пишут. Зачем в 2024 бороться с ошибками доступа к памяти, если можно взять другой язык и не бороться? Опять же процессоры давно суперскалярные, проверка индекса массива или там указателя на nullptr в большинстве случаев стоит примерно ничего.
Си ещё долго будет первым выбором для многих ниш по историческим причинам: драйверы там, всякие контроллеры и т.д. А вот ниша плюсов мне лично всё менее понятна.
с каждым годом ниша языков для "сделать быстрый код в ущерб корректности программы и скорости разработки" постепенно уменьшается
Но она все так же есть (я дочитал ваш коммент и вы не спорите :) ). Я за то чтобы для правильной работы использовать правильный инструмент - если для задачи не прям так критично важен перформанс и прямой доступ к памяти, то наверное городить туда С/С++ и не надо, но если нужен контроль над битами/байтами/регистрами и т.д. то safeC/C++ там и не взлетит, в итоге и будет мертворожденный язык (имхо конечно же), всякие ОС/геймдев/драйверописатели будут плеваться и использовать старый добрый unsafe C++, а там где этот сэйф С будет уместен, есть уже свои языки которые уже обкатаны. Ниша С++ это там где нужен С, но хотелось бы все таки классы для лучшей упорядоченности и вагон фишек из std (половина из которых будет выключена или забанена хех) - геймдев и рендеринг в частности например, всякие симуляции (строго говоря геймдев и есть симуляция), наверное чет еще есть..
Тут ещё такой момент есть. Старый софт не исчезает. Если была написана числодробилка на плюсах, то никто не будет писать её следующую версию на языке который даст просадку в перформансе на 10% даже если это будет новый крутой язык. Геймдев тут отличный пример: если новый язык не даст на том же железе как минимум тот же перформанс то никто не будет его использовать так как откат в производительности увидят клиенты и уйдут к тем кто продолжил грызть кактус. Вот и получается что там, где перформанс будет виден клиенту, нет выбора просто.
программируйте на васике. там песочница не позволяет выпасть в осадок.
с и с++ задумывались как системные языки программирования. ну то есть, никто не пишет драйвера и осе на асме, это очень трудоемко.
естественно, что там полно низкоуровневых и небезопасных фич. и нифига они не obsolete. на поинтерах, например, весь язык держится. вы помните как происходит возврат значения из процедуры в с++? либо по ссылке, либо через поинтер. ссылку в ооп далеко не везде удобно применять, а вот поинтеры - самый рабочий механизм. а вы его в obsolete. ну потому что - небезопасные.
любой серьезный проект предполагает некую дисциплину - как надо делать и как не надо. совершенно очевидно, что бардак начинается там, где не настроена такая дисциплина. называется она best practice. и, например, в том же мелкософте она не настроена. потому как winapi часто взрывается exception при передаче неверных параметров. банально функции winapi не проверяют правильность входящих параметров.
вот пример. не далее как вчера обнаружил неправильную работу одной функции работы с сертификатом. в первый вызов она считает необходимое к-во байт для выходного буфера, выделяю сколько надо, а второй раз -опять сообщает, что размера буфера не достаточно. курил долго. оказалось, что в нее был передан контейнер, в котором не было ключа. а почему бы не выдать ей ошибку - в контейнере нет ключа? нет, мы сразу ломимся в бой на непроверенных данных. оттого и размер плавал, что какая-то подфункция смотрела на мусор.
и за 20 лет ситуация не поменялась. чем поможет здесь переход на rust, если входные параметры и там ровно также не будут проверять?
чем поможет здесь переход на rust, если входные параметры и там ровно также не будут проверять?
Все еще интереснее. Когда Раст станет достаточно популярным среди "простых программистов", unsafe будут пихать по поводу и без повода, просто потому, что "компилятор без этого ругается". Так что массовый переход на Раст не изменит ничего.
с и с++ задумывались как системные языки программирования. ну то есть, никто не пишет драйвера и осе на асме, это очень трудоемко.
Это ключевой момент.
В принципе, любой ЯВУ в той или иной степени является специализированным. В том смысле, что изначально он задумывался для решения какого-то класса задач наилучшим образом. Ну так и стоит придерживаться начального замысла, а не пытаться "развивать" микроскоп в сторону придания ему свойств молотка чтобы удобнее было гвозди забивать.
Не смотря на все перечисленные Страуструпом отмазки "Около 70 % уязвимостей, которые Microsoft добавляет в каталог CVE, связаны с памятью. Microsoft Security Response Center"
А теперь взглянем с другой стороны, сколько было шуток что в 10/11 версии винды было много элементов из ХР и семёрки? А это ведь только видимый простому пользователю элемент интерфейса в настройках. Под капотом там до сих пор скорее всего куча Легаси кода на Си и плюсах 98го стандарта.
Продавать старое по цене нового - классика бизнеса, так то.
Ещё во времена win98 ходили шутки типа (восстановлено по памяти):
в процессе анализа исходных кодов windows 98, которые утекли из микрософт, были обнаружены следующие строки кода:
#include "msdos.h"
#include "win311.h"
#include "win95.h"
Под капотом там до сих пор скорее всего куча Легаси кода на Си и плюсах 98го стандарта.
И слава богу. Это отличный код, написанный умными людьми, вроде Dave Cutler, Lou Pezzoli, Mark Zbiowski, Landy Wang. Людьми, у которых в голове не понос, а мозги. Если бы не этот код, Microsoft бы вообще не было как компании.
Код то возможно и хороший, даже по нынешним меркам он может справляться с задачами. Только вот подобные CVE это либо следствие скопившегося тех. долга, либо небольшая оплошность какого-нибудь младшего сотрудника ещё в те времена, а сейчас на этом фоне делают все вид что это язык виноват( то же самое что винить молоток в том что он криво гвозди забивает в руках неумелых людей)
Всё здорово, только вот эти CVE никакого отношения именно к плюсам не имеют, а страуструп не имеет никакого отношения к си
Как по мне лучше так, чем постоянный геморрой с вылетами, ошибками, синими экранами и прочей гадостью
Я просто оставлю это здесь.
„Новая научная истина торжествует не потому, что ее противники признают свою неправоту, просто ее оппоненты со временем вымирают, а подрастающее поколение знакомо с нею с самого начала.“
— Макс Планк [про ЯВУ для ЭВМ Rust, 1920]
Нытьё старика по временам молодости. Страуструп герой своей эпохи и он веха, но вместе с тем стоит признать, что пора двигаться дальше и призыв абсолютно по делу. Текущее время требует актуальных решений, а не ковыряния в том, что было актуально когда-то там.
А Страуструпу 73 и пора внуков нянчить
Давно пора. Я ещё, когда 18 лет назад читал спецификацию C# 2.0, мечтал, что C++ наконец-то уйдёт в историю xD
Кто-то ещё помнит про Microsoft Singularity?)
И ещё столько же "помечтаете", бггг. Как минимум.
Ну, подвижки уже есть, и в Linux и в правительстве США (я вообще думал, что они там на Ada и Cobol до сих пор пишут xD). Так что норм, наблюдаем дальше)
Насчет Linux - Линус сказал (с плохо скрываемым ужасом в голосе), что на Расте сам не пишет и не планирует. Что фигово. (Но хорошо хоть, что ревьюит коммиты на Расте, и что Интернетом пользуется, а не как некоторые, которым «доклады в папках приносят».)
Линус сказал (с плохо скрываемым ужасом в голосе), что на Расте сам не пишет и не планирует. Что фигово.
Почему фигово? Вполне себе реакция здорового человека. Что такое новое может дать Rust в ядре с технической точки зрения, кроме социокультурных моментов вроде упомянутого "привлечения новых молодых программистов для написания драйверов"?
Про безопасность можно не говорить, в данном случае не интересно (до тех пор, пока все ядро на Rust не перепишут).
Кстати, а когда на Rust хоть какое-то ядро уже напишут (или уже написали)?
Там на ЛОРе недавно мелькала новость, какие-то энтузиасты на Ada уже POSIX совместимое ядро верифицированное таки смогли написать, не прошло и 50 лет. Ада, кстати, это был вполне такой себе Rust в 80-х и немного 90-х, жаль померла правда (по тем же нетехническим причинам, что похоже и раст ожидают).
Весь софт для F-22 на Ada был написан, что показательно. Правда весь коллектив потом на пенсию внезапно вышел, а новых не смогли найти, в результате даже пришлось F-35 полностью отдельно с нуля строить, т.к. набранные с рынка C++ разработчики просто не захотели с Ada кодом разбираться.
Ты COBOL не трогай. У нас на нем нью-йоркская фондовая биржа с 70-х без сбоев работает.
Разумнее, имея такой опыт, "проинвертировать" мечту.
Появится шанс, что сбудется.
правильно.... да и весь C++ на самом деле дичь какая то стала.., перегружен весь , ....
Просто там минимум три языка в одном - макросы, шаблоны, и C с классами. А для реального использования придётся ещё как-то знать Make или аналог, а некоторым ещё и в скриптах линкера разбираться и тп.
с одной стороны плохо, с другой стороны каждый юзает именно то, что надо ему
знать Make или аналог
Простите, но зачем в 21-м веке знать про make?
CMake давно де-факто стандарт. Ну или automake для принципиальных дедушек - он вроде тоже умения в непосредственно make не предполагает (там могу ошибаться, сам не пользуюсь).
Подскажите хорошую инструкцию на CMake, а то у меня как-то сложно вышло библиотеки подключать из под винды... да и пользоваться, все пасет каким-то костылизмом и натягиванием сов с прописыванием setx CPP=g++
Подскажите хорошую инструкцию на CMake, а то у меня как-то сложно вышло библиотеки подключать из под винды...
Простите, а зачем вы под винду до сих пор что-то пишете? Этож Legacy еще хуже какого OSF/1. Современный Linux вполне юзабелен для абсолютно всех задач, ну кроме CAD/CAM/CAE.
А если по существу - да, Windows и Clang/CMake были "подружены" даже в VS сильно неестественным браком, и реально пользоваться этим было просто невозможно лет пять назад. Весь движ в C библиотеках (да и в С++ тоже, хотя это отдельная спецолимпиада) - он уже много лет почти исключительно в POSIX средах, до Windows там долетают только жалкие остатки.
И вырывать себе волосы, пытаясь на коленках сочинять mmap() и fork()/clone() и прочие POSIX API враперы, а потом портировать еще что-то под винду - такое даже врагу не пожелаешь.
А вот под Linux там все предельно просто - просто берешь и пишешь
target_link_libraries(${target} LINK_PUBLIC ssl)
target_link_libraries(${target} LINK_PUBLIC faxpp)
target_link_libraries(${target} LINK_PUBLIC uuid)
target_link_libraries(${target} LINK_PUBLIC xxhash)
target_link_libraries(${target} LINK_PUBLIC crypto)
даже FindLibrary() уже и не почти нужны совсем.
Моё мнение: язык должен палкой бить по пальцам, когда пытаешься писать небезопасный код. Тот же Rust прекрасно с этим справляется. Однако это тоже спорное утверждение, потому что не весь код в мире работает на ядерных реакторах, в медицине, самолётах, подводных лодках и т.д. Для какого-то там гейминга C++ со всеми его недостатками вполне пригоден. И, как мне кажется, языки последнее время в новых проектах стали более выраженно занимать свои ниши.
К большому сожалению, C++ в критических областях с нами ещё очень надолго, потому что legacy никто не отменял (COBOL не даст соврать). И попытки сделать его хоть немного безопаснее мной очень приветствуются.
Но "безопасный код" это очень абстрактное понятие. Чаще все же ошибки в логике кода влияют на фактические кражи, фроды, угоны аккаунтов, а не очередной бафероверфлоу.
В жава скрипте вроде как невозможно накосячить с памятью, однако же, лично у меня ВКонтакте на вкладке видео, после смены вкладки умудряется улететь с out of memory, на полностью безопасном языке. А сколько сайтов в интернете с апиключами плейнтекстом живет мммм...
И я годы пишу, но так и не понял, как безобидный крашик может стать прям уж дырой? И как безопасность передачи объектов как-то там нароляет мне отсутствие sql-injection и хитро выполненных гонок.
Все это дудение про "безопасные языки" - это просто-напросто очередная манипуляция. Взять тот же веб с его бесконечными XSS'ами, CSRF'ами и так далее. Что мы там видим? Java, Javascript (NodeJS) и PHP. Сплошь так называемые "безопасные" языки, никакой там страшной сишечки. "Безопасных" языков не существует, этот термин используется исключительно для оболванивания населения.
А представьте, если бы через javascript еще и память можно было портить. У всего браузера сразу. Вот крутота то была б!
Помните как все спешно чинили heartbleed, кстати? А ведь это всего лишь одна маленькая ошибка при работе с памятью. А шороху навела больше чем все XSS вместе взятые.
Вот крутота то была б!
Да и сейчас все там отлично, учетки, платёжные данные и API ключи тырятся регулярно и вполне успешно.
Помните как все спешно чинили heartbleed, кстати?
А помните, как все спешно чинили log4shell, кстати? А ведь там не было никаких ошибок при работе с памятью вообще. Но как-то это не помогло. "Безопасный" йазыг в очередной раз оказался каким-то не совсем безопасным, бггг.
Ну я надеюсь вы не будете отрицать, что ошибки при работе с памятью не исключают логических ошибок? Вы же не утверждаете, если бы все писали все исключительно на C, то учетки никто не тырил бы и платежные данные не утекали б, правда?
Небезопасные языки добавляют еще один очень веселый класс ошибок, но никак не уменьшают количество других типов ошибок. Вот если бы все писали на Coq, например... Тогда да.
Ну я надеюсь вы не будете отрицать, что ошибки при работе с памятью не исключают логических ошибок? Вы же не утверждаете, если бы все писали все исключительно на C, то учетки никто не тырил бы и платежные данные не утекали б, правда?
К чему все эти очередные манипуляции? Ещё раз - термин "безопасные языки" лукавый, "безопасных" языков не существует (как, впрочем, и "небезопасных"). Вот что я хотел сказать и сказал. Не надо придумывать всякую фигню.
Окей, считайте что "безопасные" это такое сокращение от "безопасные при работе с памятью". Так лучше? Собственно, это и имелось в виду, когда этот термин придумывали. Просто англоговорящие обожают все сокращать.
А Rust еще и дает нефиговые гарантии для многопоточности...
Окей, считайте что "безопасные" это такое сокращение от "безопасные при работе с памятью". Так лучше?
Более точное определение - это хорошо, прогресс, только вот... опять не получается. Тот же раст не является языком, "безопасным при работе с памятью", из-за возможности написания unsafe кода. А ведь unsafe - это неотъемлемая его часть по той простой причине, что если бы этой части не было, то написать хоть что-нибудь на расте было бы вовсе невозможно. Так что определение опять лукавое, может, ещё что придумаете? Например, "иногда безопасный при работе с памятью" или там "не всегда безопасный", как вам, бггг?
Ну блин, из пайтона я тоже могу открыть /dev/mem , дернуть mmap и пойти гулять по памяти как захочу. По вообще всей память компьютера, заметьте. И что он теперь, небезопасный?
С# позволяет кастить сырые данные к управляемым объектам и обратно. Что, он тоже небезопасный?
Про яву не знаю, но думаю что тоже можно, если захочется.
Это вы тут отстаиваете какое-то деление на "безопасные" и "небезопасные" языки, а не я, вам и голову ломать :) Я, напротив, нахожу подобное деление, мягко скажем, спорным. Дьявол всегда в деталях, а огульное навешивание эмоционально окрашенных ярлыков - это не технический подход, а просто манипуляция.
Многолетняя практика доказала что человек не способен писать на плюсах без ошибок работы с памятью. Где-то это допустимо. Игровые движки всякие, например. Там одно падение по неизвестной и неуловимой причине на тысячу часов допустимо. А вот там где нужна надежность и безопасность использовать плюсы нет ни одной причины. Такого софта подавляющее количество.
В вебе нужна надёжность и безопасность? Конечно! И основными языками в вебе являются вовсе не плюсы. Только вот неписание на плюсах там отчего-то практически не помогает. Ошибки, допускаемые погромистами, просто плавно перетекают в другие области, а результат тот же самый - вас поимели, просто не через переполнение буфера, а через инъекцию кода в другой форме или просто через ошибку в логике. Все эти рассуждения про "безопасность языков" просто болтовня, ибо рулят не языки, а практики. Впрочем, все это обсуждение здесь - ничуть не меньшая болтовня :) Почесал я языком, и хорош.
Язык помогает исключить целый класс сложных и опасных ошибок. Вроде все говорит что надо брать такой язык. Но люди продолжают использовать старый язык без такой такой защиты просто потому что.
В Джаве на которой я пишу большую часть кода сделали рекорды. Они иммутабельны насколько это возможно в Джаве и тоже защищают от целого класса ошибок. Насколько это хорошо и приятно... Вы не представляете. Я точно знаю что вот этот объект не мутирует никогда. А воон тот может быть мутирует, но в понятных пределах и все места где он мутирует просто найти если что. И если он на самом деле мутирует без очень веской причины я приду к автору кода и спрошу ты что такое, блин, делаешь?
Люди продолжают использовать старый язык вряд-ли "просто потому что", а так как привыкли и потратили много сил и времени на изучение языка и экосистемы. А чтобы стать хорошим плюсовиком, полагаю требуется реально много сил и времени. Это помимо очевидной причины, что старый код поддерживать-то надо, и сам он себя не перепишет.
Кстати в данном случае микросервисный подход имеет плюсы - перейти на новый стек на новых сервисах при сохранении API намного проще, чем линковать common lisp с Java.
обычно есть менеджер пакетов через который вы добавляете код в свой проект, и автор кода который мутирует может находится гдето в районе тимбукту. Поедете? или вы заказываете экспертизу всех пакетов которые используете?
Вот никогда не понимал этот аргумент. Автор библиотеки может жить в Х, автор кода в стандартной библиотеке может жить в Х, автор компилятора\интерпретатора может жить в Х, автор виртуальной машины\контейнера, в котором код запускается может жить в Х, автор кода TCP/IP используемой ОС может жить в Х, автор драйверов сетевой карты может жить в Х, дизайнер железа этой сетевой карты может жить в Х, дизайнер чипов, используемых в этой сетевой карте может жить в Х, автор чего угодно может жить в Х.
Для очень серьезных вещей используется собственный package registry, только вместо обычного кеширующего прокси он только хранит проверенные пакеты проверенных версий.
Если вам кто-то угрожает и заставляет использовать внешние зависимости вы моргните 2 раза и мы все поймем.
Это просто у вас нет статистики, что было бы, если бы там с таким же подходом писали не на JavaScript. Практика-практикой, но доброе слово и пистолет практики и помощь от компилятора делают больше, чем просто доброе слово практики.
Только вот неписание на плюсах там отчего-то практически не помогает.
Не помогает от чего? Например, от получения доступа к серверу путем выполнения какого-то HTTP запроса помогает.
Но от ошибок в логике не помогает, да.
Вы везде мешаете одно с другим, по принципу "сгорел сарай -- гори и хата": если уж ни один язык не застрахован от логических ошибок, то нету смысла в защите от ошибок в работе с памятью.
Про яву не знаю, но думаю что тоже можно, если захочется.
Я знаю. В Джаве есть замечательный оффхип. Который позволяет делать с памятью что угодно.
Все хорошие языки инструменты позволяющие портить память выносят отдельно. И заставляют явно прописывать что вот тут я беру всю ответственность на себя. Кода где это надо очень мало на самом деле. И такие инструменты помогают явно такие места показать и вынести куда-то в отдельные сущности. И заодно тестами обложить в три слоя.
Джаваскрипт работает в отдельной вкладке, а та в отдельном процессе, т.е. невозможно ничего там подпортить никак
Все это дудение про "безопасные языки" - это просто-напросто очередная манипуляция. Взять тот же веб с его бесконечными XSS'ами, CSRF'ами и так далее.
Какое отношение особенности работы браузера имеют к серверным языкам?
удобное мнение. у раста же не было тонны кода, который он должен был не сломать при создании и развитии. а сказать, чтобы переписали всё, что до этого написано - много ума не надо. можно и в плюсах так сделать: запретить работу с сырыми указателями и сказать, мол, переписывайте, ребята )
В Расте как раз этот момент учтён: каждые три года выпускается новая редакция (edition) языка, несовместимая со старой (в последнее время - несовместимость только в некоторых мелких деталях, но всё же).
Но при этом компилятор умеет компилировать все версии языка, просто надо в конфигурационном файле указать, на какой версии языка написана программа или её часть. Подробнее можно посмотреть по ссылке https://doc.rust-lang.org/edition-guide/editions/
Таким образом, новый код обычно пишется на современной редакции языка. Старый может оставаться на старой версии, но часто в ходе рефакторинга корректируется на современную версию, благо сделать это обычно несложно - есть встроенная в Cargo команда "cargo fix --edition", которая автоматически апдейтит программу.
К большому сожалению, C++ в критических областях с нами ещё очень надолго
Ну тот же QNX рулит самолетами, автомобилями и реакторами. Написан на богомерзких небезопасных языках. Может дело не в бобине?
Страуструп, конечно, молодец, и цели хорошие ставил. Он ведь не отказывается, что ставил их? Он просто не упоминает, что цели не достигнуты.
То что С++ -- не С это он пусть зеркалу объясняет. Берем любую С программу, компилируем С++ компилятором и оно работает в 99% случаев. В 1% не соберется из-за необноходимости переименовать зарезервированные слова, которых в С++ побольше, чем С.
Бьярн прав, конечно, что безопастность работы с памятью - это не единственная проблема языка, но не прав, пытаясь увести в сторону, потому что это самая зияющая проблема языка Да, С++ предоставляет механизмы, всё ок с ними (кроме сложности). Но механизмы работают только если и когда ими пользуются и пользуются правильно. А раз старые С-шные конструкции работают и механизмы не совсем законченные, то любой случайно залетевший дятел рушит цивилизацию. Мы эту шутку все знаем. И указатели там живут, и ссылки могут ссылаться на несуществующие объекты и смарт укзаатели пришлось переписывать, чтобы со второго подхода они стали чуть умнее, и контейнеры, которые за 13 лет научислись перемещать объекты и поддержка файловой системы через 19 лет и корутины через 22. Темпы развития поражают воображение. Так через 50 лет можно ожидать unsafe блоки, как в Rust были добавлены лет 9 назад.
С++ надо объявить трупом и перестать улучшать труп. Дедушка С++ был хорошим, мы все будем поминать его добрым словом.
Так через 50 лет можно ожидать unsafe блоки, как в Rust были добавлены лет 9 назад.
Вы лучше скажите, когда уже в расте можно ожидать хотя бы in-place конструирование объектов в контейнерах, которое в "дедушке C++" появилось минимум 13 лет назад. Или нормальную возможность сообщить об ошибке из перегруженного оператора, особенно в обобщенном коде. А то мне тут объясняют, что перегрузка операторов в расте - моветон. Жопа есть, а слова нет.
Конструирование объектов в контейнере, если я правильно понимаю о чем вы - это было всегда, с С98 -- определяете вектор, например строк, и говорите что нужно иметь длину 50, например, элементов и resize() сам создаст все строки дефолтовым конструктором вызывая T::T(). Делов то. Это прям магия, большое технологическое преимнущество дедушки С++? Или речь об inplace new операторах?
C++ не зашел в ядра операционок. На нем не строят API ни к чему кроме С++, строят на С. С++ не используется в firmware, на нем не пишут драйвера, на нем не пишут обработчки пакетов (DPDK). А на Rust всё это уже пишут.
Ну как бы там ни было, речь не идет о том, чтобы все стройными рядами шли в сторону Rust. Я упомянул лишь для сравнения и причина понятна - в Rust гораздо меньше багажа, низкая база и отсюда большая скорость развития. Но я отнюдь и я не апологет парадигмы one-fits-all. Есть и другие языки, безопасные при работе с памятью. Это всё и нужно развивать.
если я правильно понимаю о чем вы
Я вообще-то о функциях типа emplace().
Это прям магия, большое технологическое преимнущество дедушки С++?
Да, возможность создания объекта сразу в нужном месте, без лишних копирований - это технологическое преимущество.
С++ не используется в firmware, на нем не пишут драйвера
Пишут на нем и firmware, и драйвера. Если вы об этом не знаете, то это не значит, что этого нет.
отсюда большая скорость развития
Ну так пусть развивается уже, а то функционал, который в плюсах уже был ещё в лохматые года, до сих пор отсутствует. А отсутствует он не просто так, а по причинам, но опять объяснять очередному пионеру с барабаном, горном и флагом эти причины я устал.
Да, возможность создания объекта сразу в нужном месте, без лишних копирований - это технологическое преимущество.
Согласен. Это хорошее дело, но его как раз не было в С++ с самого начала. Всю дорогу были копирования - вы добавляете (push) объект в контейнер и он делает для вас копию. Вы делаете resize вектора и он начинает делать то же самое для всех объектов.
И лишь через 13 лет появляется move сематника, при которой копируют сырые данные объекта на новое место и обнуляют их в источнике. Оптимизатор может позволить и это убрать, чтобы сразу создавалось где надо. Но язык, еще раз, изначально этог не делал и для backward compatibility поддерживается весь зоопарк - что было до, и что стало после С++11. Вы видимо не застали те счастливые годы, когда не было = delete и приходилось объявлять private оператор присваривания и конструктор копирования в больших объектах, чтобы копилятор явно ругался там, где подразумевается неявное компирование. Это С++.
В Rust есть явная передача владением. Эта концепция похожа на move.
Пишут на нем и firmware, и драйвера. Если вы об этом не знаете, то это не значит, что этого нет.
Сколько драйверов Linux или *BSD написано на С++? Сколько boot firmware в материнских платах написано на C++? Да, есть исключения. Вы отрубаете exceptions в опциях компилятора, врубаете статическую линковку и делаете прочие приседания типа оборачивания всего внешнего в extern "C", скрываете все символы по-умолчания, чтобы С++ стал максимально подобен С и по поведению и по API и тогда можно писать firmware и драйвера. Но это надругательство над средой с большим overhead. Поэтому это не стало mainstream. Люди просто используют C в таких случаях.
Ну так пусть развивается уже, а то функционал, который в плюсах уже был ещё в лохматые года, до сих пор отсутствует
У нас с вами разные лохматые года. У меня - это конец 80х, когда я начинал кодировать и никакого С++ в помине не было. А 2011й год с C++11 это было буквально вчера. К тому же он вошел в обиход и стал стабильным примерно в 2013м. И с 1998-99 по 2013 приходилось лавировать в С++ чтобы избежать копирования или чтобы оптимизировать цепочки вызовов. При том ведь не было даже unique_ptr или shared_ptr, никаких стандартных потоков или объектов синхронизации. Все тащилось через библиотеки из ОС. А Бьёрн утерждал с пеной у рта что так и должно быть. Что язык должен быть чист от таких особенностей некоторых (всех) ОС. Язык сделал огромный рывок в 2011 создав комитет, который принял все эти инновации. Всё идет значительно лучше с тех пор. Но право речь не об этом, а о том, что всё старое осталось и любой залетевший дятел может всё порушить. Вы работаете в коллективе из 8+ человек, где есть и синьоры и джуниоры. Не приходилось разбирать последствия "инноваций" новичков? Ведь так легко и незателиво рушиться не должно. Правильное дело когда синтаксис построен так, что компилятор имеет возможность обнаруживать косяки во время компиляции, задолго до рантайма. Это же клево! Чем больше таких языков, тем лучше. Может сделают подобное Rust, но проще типа GoLang - буду только рад.
Что касается Rust - я не вполне понимаю что у вас не получилось в нем?
Что касается Rust - я не вполне понимаю что у вас не получилось в нем?
Ну вот я выше привёл ссылку на метод плюсового вектора (аналогичный функционал есть у всех контейнеров из плюсовых std), попробуйте найти подобное в контейнерах из растовского std. Когда не найдёте, подумайте, почему вы его так и не нашли, и почему за все время существования раста этот функционал так и не смогли из плюсов передрать.
Ваши жалобы на то, что 30 лет назад в плюсах не было того и сего, и что Страуструп не придумал сразу все и не запихал это все в плюсы, даже разбирать не буду, ибо это все равно, что всерьёз разбирать жалобы на то, что 30 лет назад не было, условно, айфонов, ибо всякие козлы их ещё не придумали.
в сущности emplace - это костыль для insert, который не способен создать на месте. Ему надо создать, переместить, убить. Вот чтобы исключить создать-убить - и сделан emplace(). Кроме обрамляющего создать-убить у insert, у них больше нет никакой разницы, они оба используют один и тот же метод в векторе _M_realloc_insert() - считайте "private emplace()"
Например этим создать-убить плох vector<string> v; v.insert(v.cbegin(), move(string(5, '-'))) и этого создать-убить нет в vector<string> v; v.emplace(v.cbegin(), 5, '-'). Я могу углубиться в детали с использованием g++, с оптимизацией и разбором ассемблера что из этого получилось и почему. Т.е. это я пока в поддержку вашей правильной идеи о хорошести emplace().
Теперь о Rust. В Rust изначально нет этого косяка, там нет такой семантики такого копирования, поэтому нет и фикса с семантикой move. Там move изначально. Может, просто не стоит пытаться пофиксить то, что не нуждается в фиксе? ;)
Сразу скажу, что я с вами согласен, но придется заступиться и за оппонента.
Проблема раста в том, что вы не сможете написать емплэйс в контейнере сразу по многим причинам. Начнем с менее серьезной - нет вариадиков. Ну тут рецепт фикса такой же как и в плюсах 98. Худо бедно, но решается, а вот то, что вызов конструктора на типе требует от автора типа реализации трэйта, в котором этот конструктор объявлен уже фатальный недостаток.
Т.е. во первых этого трэйта нету, во вторых это должен быть не один, а пара десятков трэйтов (по количеству параметров конструктора), в третьих если у вас тип имеет 2 и более конструктора с одинаковым числом параметров то придется приседать и использовать +1 параметр для реализации оверлоада внутри трэйтового метода, в четвёртых мы ещё ошибки даже и не обсуждали, а это ещё несколько десятков трэйтов.
Но это все фигня, пипец заключается в том, что у вас будет по несколько десятков векторов, и каждого контейнера со своим именем для ограничения типа одним из трэйтов, ну а если у вас тип поддерживает конструкторы с разным количеством параметров - просто застрелитесь.
Короче без серьезных макросов к этой задаче не стоит даже и подходить. С макросами можно и без трэйтов обойтись, но тогда надо как то атрибутами конструкторы помечать или по сигнатуре их определять, правда в этом случае можно сделать лучше чем в плюсах вместо одного вариадного emplace будет метод с точно таким же именем как у вашего типа конструктор ну плюс суфикс/префикс типа emplace_from, emplace_new, emplace_create хотя для последнего я бы оставил только эмплэйс.
Что это даёт? Ну можно сэкономить пару занулений при муве в тех случаях когда компилятор не сможет сам все соптимизировать ну и конечно ощущение своей собственной оффигенности от использования нетривиальных макросов в расте и чувство удовлетворения фантомной боли полученной ранее в многочисленных боях с с++ шаблонами.
Поэтому в стандартных контейнерах мы действительно этого скорее всего никогда не увидим.
Я бы сказал, что пипец этим не исчерпывается.
Во-первых, такой "конструктор" должен будет работать с неинициализированной памятью. Во-вторых, появляется проблема fallible creation, ибо если такой "конструктор" получает данные для создания объекта откуда-то через вызов чего-то (например, при десериализации), то это что-то может зафейлиться. Да, можно заставить конструктор каким-от образом возвращать при этом ошибку и где-то ее обрабатывать, но проблема в том, что для того, чтобы можно было реализовывать и использовать аналоги плюсового emplace() в safe подмножестве раста, нужно предоставить твердую семантическую гарантию, что даже в случае возникновения ошибки при конструировании объект либо будет полностью инициализирован, либо полностью уничтожен, и после вызова условного foo(&uninit T)в случае возникновения проблемы к этому T обратиться будет нельзя. В общем, чем дальше в эту кроличью нору, тем больше неудобных вопросов.
Для этого всего вроде как MaybeUninit был сделан https://doc.rust-lang.org/core/mem/union.MaybeUninit.html
Как нет семантики? Принципиально не возникает ситуации, когда нужно in-place создать копию объекта, всегда только и исключительно мувы?
"в сущности emplace - это костыль для insert, который не способен создать на месте..."
откуда код insert знает - подставлен ему временный обьект или нет. если временный, то обьект оптимальней переместить. в противном случае надо копировать.
если в русте нет "семантики копирования", то как невременный обьект положить в список(верней его точную копию), строку например.
Так есть же rvalue ссылки, он и перемещает если можно.
emplace про то, что конструктор вызывается на байты непосредственно в векторе, а не создаётся временный (между круглыми скобками вызова emplace), который мы муваем.
Ну а copy-elision с 17 стандарта дает приятные гарантии на похожую логику при обычной работе функциями.
Теперь о Rust. В Rust изначально нет этого косяка, там нет такой семантики такого копирования, поэтому нет и фикса с семантикой move. Там move изначально. Может, просто не стоит пытаться пофиксить то, что не нуждается в фиксе? ;)
В отличие от вас, мужики-то знают, что move семантика раста - это просто завуалированный вызов memcpy(), и на самом деле уже довольно давно пытаются как-то уменьшить количество копирований, просто не могут по ряду причин.
Вы так пишете, как будто в плюсах конструкторы перемещения не сводятся к этому же memcpy (в лучше случае!)
Конструкторы перемещения при in-place конструировании в плюсах вообще не нужны и не применяются (если речь не идёт о перемещении уже готового объекта с одного места на другое). Я хз, почему оппонент считает, что в расте семантика перемещения может как-то заменить in-place конструирование, поэтому на всякий случай упомянул, что это на самом деле такое, а то такое впечатление, что оппонент себе это не очень отчётливо представляет. Вон@Kelbonчуть ниже на эту тему все правильно по сути написал, но местные троглодиты зачем-то минусуют.
А что Вы имеете в виду, когда говорите "что move семантика раста - это просто завуалированный вызов memcpy()" - не расскажете подробнее?
Вы тоже не знаете? Что, например, здесь, по-вашему, происходит?
Так расскажите, пожалуйста, поподробнее, не заставляйте догадываться! :) Что именно лишнее копируется и почему именно не срабатывает move-семантика. Может быть, ссылочку дадите, где почитать подробнее?
Так расскажите, пожалуйста, поподробнее, не заставляйте догадываться! :)
А что из моего примера непонятно? При "перемещении" происходит создание нового объекта по новому адресу, туда копируется содержимое старого объекта (тот самый memcpy()), затем старый объект отбрасывается.
почему именно не срабатывает move-семантика.
Что значит "не срабатывает"? Это и есть "move-семантика" в представлении раста. А вы думали, как все работает?
А что, в C++ по-другому разве? Move constructor точно так же копирует все данные из одного объекта в другой.
Ещё раз - я пытаюсь показать, что move семантика раста не представляет из себя ничего волшебного, способного заменить собой in-place конструирование. В C++ перемещение и in-place конструирование - это вещи вообще не связанные между собой. Отвечаю на ваш вопрос для порядка - да, в C++ генерируемые компилятором по умолчанию конструкторы перемещения - это тоже memcpy().
ну вот нет, по умолчанию конструктор перемещения это вызов конструктора перемещения всех полей и базовых типов по очереди, а разница тут колоссальная. В расте self reference типы непредставимы из-за этого, что конечно громадный просчёт языка
Ну да, правильно, я некорректно выразился. Я имел в виду, применительно к моему примеру, если у объекта поле примитивного типа а-ля size_t, то оно будет просто скопировано без изысков.
Ну в расте селф реф типы во первых представимы, а во вторых значат немного не то о чем вы здесь пишете, ну и в третьих проблема с копированием возникает если граф объектов действительно зациклен, но тогда и в плюсах вы обязаны запретить и копи и мув конструктор по умолчанию или переопределить их (но зачем?). В любом случае я не припомню необходимости в реальном коде на плюсах ни мувать ни копировать объекты с циклическим графом, они по сути всегда синглтоны раз создал и пользуйся, так что нет это НЕ громадный просчет.
какой циклический граф? Что? std::string - self reference тип, вам никогда не хотелось скопировать строку?
Я же и написал, что в расте это другое понятие (более широкое чем в с++) если интересно как один из инструментов смотрите self_cell, а в с++ строки НЕ селф реф тип это уже вы совсем запутались. В плюсах это будет например линкед лист или дерево, когда один из мемберов это указатель на структуру которая и содержит этот мембер. Конечно такие структуры полезно и мувать и копировать, но линкед листы и в расте вполне в стандартной библиотеке хорошо себя чувствуют. Ну да тот юзкейс что у меня в голове с графом обьектов тоже не селф реф технически.
а в с++ строки НЕ селф реф тип это уже вы совсем запутались.
Вы говорите не о том. Потому что я уверен, что типичная реализация строки это self reference тип, а вы говорите про какие то графы, которые несколькими нодами создают циклическую зависимость, а не внутри себя. И да, в расте такие графы (и даже двусвязный список) тоже невыразимы без диких костылей, в то время как в С++ они делаются элементарно
но линкед листы и в расте вполне в стандартной библиотеке
так хорошо получился, что сами создатели пишут "не используйте это никогда, вектор всегда лучше" (потому что все операции над этим типом оказались в расте невыразимы)
Погодите, с чего бы вообще хоть какой-то реализации строки быть self reference типом?
Ну да ну да, а в плюсах значит не точно также пишут про стд лист, что не надо его использовать, а вместо него юзай вектор. Даже очередь по умолчанию дэк использует вместо листа
потому что очереди не нужна операция вставить в середину или отсортировать без инвалидации ссылок
Вы листы то сами используете или только учите остальных о том какие они замечательные в стандартной библиотеке плюсов и как в расте буквально все без них страдают? Везде где я бы не увидел стд лист это был код джуна, не я конечно видел листы по делу, но они всегда были самописными и почти всегда на сях и опять же всегда про ноу лок + свой аллокатор в придачу. Я даже видел листы на массиве + фрилист нодов в одном флаконе, но не надо тут рассказывать про стд листы это мертвый груз плюсов как и стэк, а вместе с ними мертворожднные форвард листы. Очередь хоть как то юзабельна. Лучше бы комитет в свое время флат мапы принял вместо форвард листов и спан по раньше, но нет приходите в с++23 ну хоть на этом спасибо, хотя надеюсь что мне уже не придется этим пользоваться когда оно наконец то появиться у меня на работе.
Раст не идеален, дженерики откровенно слабы хоть работа над ними и ведётся, запрет реализации трэйтов на чужом типе вообще какая то шиза (сами оборачивайте миллион ероров и жрите молча дефолтные реализации трэйтов), конст противозачаточный, макросы наркоманские, дебаг ущербный, асинк вообще местами без костылей не компилируется, функционал шина вырвиглазная трехжтажная хрень с постоянными приседаниями на ровном месте, но все же я расту готов простить вообще все проблемы только хотя бы за то как он с зависимостями справляется.
Я был буквально в шоке, что добавить ЧУЖУЮ либу это 2 минуты работы, а не лять неделя как я вот прям щас мучаюсь в плюсах с либой из другой команды. Конаны шмонаны, смэйки и прочие вообще курят в сторонке и помолкивают. Вы когда на расте последний раз писали сериализацию? я ни разу, а на плюсах чуть ли не ежемесячно.
Хотите строку в энум и назад нате вам 10 способов один хуже другого. У нас в коде вообще нет сырых владеющих указателей, утечки? Полно, рэйсы? Куда ж без них родимых то, хотя все буквально обмазано мьютексами я вообще удивляюсь как оно ещё не тормозит. Шаред поинтеры вызывают деструкторы хер пойми в каких потоках ИНОГДА? - нет инструмент прекрасный, но гореть этим людям в аду за шаред поинтеры в стандарте, место им в бусте. Проезды по памяти? - это на десерт и хрен вы их найдёте без санитайзеров, а сборка с санитайзером на железке просто как пошаговая стратегия вместо риалтайма работает. Попробуйте собирите культю под санитайзером, не мы ее собрали конечно в итоге и щас даже автотесты под санитайзером завелись, но это все невероятно непросто. Получить стэк трэйс при логировании - удачи вам. Логирование? Сто пицот библиотек и все равно в каждом проекте своя и убогая. Пул потоков? ага есть в стандарте, только забанен вообще везде вместе с футурами, вот и пишет каждый свои джобы, а там пипец сколько багов, но это можно починить, а вот объяснить как пользоваться джобами можно только тому кто их написал раз хотя бы сам, но им то как раз и не надо ничего объяснять они нормально ими пользуются в отличие от остальных. Написать что то свое на шаблонах? гарантия проблем, либо не могут понять колеги, либо внезапно вылезают проблемы с ними в зависимостях(привет гтест и файнал) либо вообще студия поднимает лапки и говорит ну не шмагла я сегодня это скомпилить, пойди туда сама не скажу куда и попробуй упростить не скажу что. Это вот у нас прям щас проблема после обновления на 17.9.2
В расте я собрался и запустился, все косяки в МОЕМ ффай СРАЗУ запаниковали. Один раз все пофиксил работает как часы, если я какую то дичь творю оно либо не собирается либо сразу падает других вариантов я пока не видел. А у меня там много всякого, и алактор системный перегружен и ффая в скулайт дофига и больше и асинхронщина со своим экзекьютэром и сборка дллки плагина для скулайта и тесты всего этого не стандартным раненом и грпц даже затесался, а и ещё свой недо сиквел прямо в коде через макросы, я это называю обратным орм это когда не сиквел из основного языка генерится, а наоборот раст код из сиквела и причем сиквел этот НЕ строки, а обычные токены растовские, такое плюсы не умеют и научиться чуть раньше чем герб свой цпп2 запилит - примерно никогда.
Вы листы то сами используете или только учите остальных о том какие они замечательные в стандартной библиотеке плюсов и как в расте буквально все без них страдают?
во-первых, речь была вообще про селф референс типы
не я конечно видел листы по делу, но они всегда были самописными
и вот же незадача, раст именно писать самому лист и не даёт. А это крайне частая структура данных много где, просто вы там не работаете.
Пример: компилятор языка Rust. Внезапно. Они не смогли построить AST и разместили его в одном большом векторе, думаю это признак явного провала
Я был буквально в шоке, что добавить ЧУЖУЮ либу это 2 минуты работы
только если написать хорошую библиотеку для раста это невозможно всилу перечисленных вами же выше причин, то нет библиотек - нечего и добавлять
вообще студия поднимает лапки и говорит ну не шмагла я сегодня это скомпилить
не используйте VS studio и в особенности msvc, вот и всё. Есть инструменты которые лучше по всему
НЕ строки, а обычные токены растовские
ну вот когда у вас макрос (каждый кстати запускается в отдельном процессе) сходит в файловую систему, сворует ваш код и потом передаст по сети, вот тогда реально почувствуете "мощь" растовых макросов. Безопасность
Так нет никакого аллоцирования памяти и никакого копирования данных в куче. Ни плохо завуалированного, ни хорошо завуалированного.
Фразой "move семантика раста - это просто завуалированный вызов memcpy() " Вы имели в виду, что на стеке происходит копирование? Лучше было бы об этом сказать об этом сразу - ибо 1) Вы наверняка компетентнее меня и 2) Вы знали, что имели в виду - соответственно, мне не пришлось бы догадываться.
У вас понимание вопроса нулевое, inplace конструирование было в языке сразу, называется placement new, также оптимизации RVO/NRVO тоже были сразу, но в стандарте появились позже. Мув семантика это вообще другое
под Windows на С++ писались драйвера еще в далеком 2000 году. NuMega Driver Studio. Также в те далекие годы был патч на ядро linux от финских студентов который позволял писать на С++ и там...но понятное дело он так и остался чисто академическим проектом.
1% не соберется из-за необноходимости переименовать зарезервированные слова
Ха-ха, удачи собрать плюсовым компилятором C-код с designated initializers, VLA, массивом нулевого размера в структуре или compound literals
При полной поддержке вашего комментария должен всё же сказать, что VLA из C решили таки выпилить, и они уже deprecated.
VLA из C решили таки выпилить, и они уже deprecated
В проекте ISO/IEC 9899:2024 (en) N3220 от 22.02.2024г. говорится, что VLA реализацией таки может поддерживаться (см. абзац 4 в § 6.7.6.2 Array declarators).
потому что это самая зияющая проблема языка
Не буду спорить, но ИМХО самая самая - это инклюды/хидер-файоы. Или её уже решили (давно не писал на С++)?
<del>
Смысл государству указывать как людям программировать? В Белом Доме сидят самые крутые прогеры на районе?
Доклад вообще-то представил офис директора по национальной кибербезопасности https://www.whitehouse.gov/oncd/
Это просто подразделение Белого Дома, считайте как один из комитетов исполнительной власти. Вам стоит почитать детали если хотите покритиковать
https://www.whitehouse.gov/wp-content/uploads/2024/02/Final-ONCD-Technical-Report.pdf
И нет, они не указывают как людям программировать. Но на основании доклада, думаю будут выпушены регуляции и в федеральных институтах перестанут начинать новые проекты на небезопасных языках и будут работать над заменой в ранее начатых.
В коммерческом секторе, в облаках, уже давно С++ не в фаворе, но С еще практикуют. Посмотрим что получится в итоге.
Смотрю я на соседнюю тему про российские НИИ и диву даюсь. "Офис директора по национальной кибербезопасности", это же целый комитет(!!!), который делает правое дело. Они, конечно же, "не указывают как людям программировать", однако "будут выпущены регуляции", которые ни в коем случае не подхватит ни одна коммерческая организация. Ну и как вишенка на торте, "в коммерческом секторе" все всё уже делают так, как захотел Белый Дом.
А теперь замените американские структуры на российские и ужаснитесь своим словам.
Интересный эксперимент, мне тут интересны 2 вещи:
кто заинтересован и пропихнул эту идею на столь высокий уровень
насколько повысятся требования по железу и времени для производства нового кода
Моя ставка, что кто то попилит денег на финансировании условного коммитета раста, а вся отрасль проиграет конкурентам из других стран, где таких глупостей не делают
В бесчисленных департаментах американской (да и вообще любой) госвласти запускаются бесчисленные проекты, в которых на бесчисленных заседаниях подготовительных комиссий пропоненты разных языков спорят о том, на каком языке писать новый проект.
Такие документы нужны для того, чтобы люди меньше времени тратили на болтовню.
Ну, Страуструпу осталось только доказать что C++ быстрее и безопаснее Rust.
Ой, а у нас язык не учитывает никаких особенностей платформы исполнения. (CS - он же еще про архитектуры)
Ой, сборка мусора. (Ой, опять беда)
относительно быстро устранит большинство ошибок диапазона
К моменту, когда к работе над этим подойдут - ой, а мы уже программируем при помощи GPT/DreamCoder, и в общем-то ваши чудо-поделки уже не нужны ).
P.S. Ой а в Анб-то дураки сидят, у нас в России и Европе C++, и в Китае Коммунистический Linux - все дураки что-ли?
Бред какой то. Опять призывают отказаться от стальных ножей в пользу пластиковых…
На С++ можно писать так, что будет надёжно, без возможности ошибок памяти или типизации.
Правда, при этом он будет многословнее Java, страннее Perl, и медленнее JS.
Поэтому - зачем?
Сомнительное утверждение (кроме многословности). Можно примеры кода?
Ну вот интересное чтение с примерами.
Можно писать, а можно и не писать. Речь об этом. Причём безопасность сделана как будто специально менее удобной, чем опасность (хм).
Даже вот эти вот std::super_protected_reinterpret___usable_cast_blablabla<T> и std::shared_super_puper_usable_ptr<T>. Возможно кто то считает, что так писать удобнее, чем (T) и *, но я вот не считаю, что это удобнее. Это жесть и кошмар. Зачем так делать непонятно, могли бы позаботиться ещё и об удобстве и простоте.
А вот фишка с постфиксами (что можно писать 500ms или 10s) — это весьма хорошая ложка мёда. Вот как надо делать — удобно и лаконично.
reinterpret выбрано сознательно, потому что это своего рода хак для связывания объектной модели плюсов с несовместимыми с ней сущностями из реального мира, который не должен повсеместно встречаться в нормальном коде. Если вам через строчку нужно делать reinterpret_cast, то а) вы пишете что-то жутко хитрое и жутко низкоуровневое, и ошиблись с выбором языка, б) вы пишете говнокод. В первом случае перейдите на подходящий задаче язык (или смиритесь, если переход невозможен), во втором, собственно, перестанье писать говнокод.
Про shared_ptr даже не смешно, эту чушь комментировать только портить.
На C++ (как и на C) можно написать библиотеку и использовать её в десятках других ЯП. Rust так умеет?)
Rust так умеет?)
Да
И давно у С++ появилось стабильное ABI? Где бы об этом почитать?
Мне вот сильно интересно как поймать в Java исключение выброшенное из С++ либы.
Это скорее не к ABI языка, но к системе в целом. Я вот последние 6+ лет работаю на платформе, где есть механизм системных исключений. Который позволяет строить аналоги try/throw/catch и в одной программе ловить исключения, выброшенные из другой (вызванной из первой). И без разницы на чем оно там написано. Основано все это на наличии у каждой программы "очереди сообщений" и типах сообщений (инфрмационное, блокирующее, прерывающее и т.п.) А так же "структурированной ошибки" - серьезность ошибки + код ошибки + данные. И специальных message file где по коду ошибки (и данным) можно получить полное текстовое сообщение с подставленными данными.
И все это еще и в логе фиксируется автоматом примерно так:
CPF1653 Escape 40 20.03.24 11:14:41.740968 QWVCCDLA QSYS 010E G07HMC KAPBASELIB *STMT
To module . . . . . . . . . : G07HMC
To procedure . . . . . . . : G07HMC
Statement . . . . . . . . . : 23800
Message . . . . : Activation group TIDB not found.
Cause . . . . . : Activation group TIDB does not exist.
Recovery . . . : Correct the name and try the command again.
Technical description . . . . . . . . : An activation group is created when a procedure using the
activation group is first called.Код ошибки CPF1653, тип Escape (прерывающая), уровень серьезности 40, текст "Activation group TIDB not found" (где TIDB - имя, передаваемое в данных ошибки)
Ну а дальше - это уже дополнительная информация по ошибке.
При выбросе ошибки указывается только ее код (CPF1653), тип (Escape) и данные (TIDB). Все остальное подтягивается из message файла по коду ошибки.
Можно создавать свои описаний и коды ошибок и выбрасывать их в виде исключений в одном месте, а ловить в другом (хоть в этой же программе, хоть в той, откуда ее вызвали).
Т.е. имеем универсальный механизм работы с исключениями на уровне системы а не отдельного языка.
Ну это да. Помнится, в виндах тоже было что-то такое, хоть и менее навороченное. Но оно никак не мапится в собственно язык. Обычным try/catch такое не поймаешь, насколько я знаю. Разве что runtime library будет ловить вот такое системное исключение, заворачивать в соответствующий класс и бросать уже как исключение языка.
Собственно в язык - нет. В здешней реализации С/С++ есть
#pragma exception_handler(ExeptHandler, 0, _C1_ALL, _C2_ALL, _CTLA_HANDLE_NO_MSG)
...
#pragma disable_handlerЭто некий аналог try/catch. Throw делается через системный API.
В ExeptHandler прилетает такая вот байда:
/* Interrupt handler parameter block */
typedef _Packed struct {
unsigned int Block_Size; /* Size of the parameter block */
_INVFLAGS_T Tgt_Flags; /* Target invocation flags */
char reserved[8]; /* reserved */
_INVPTR Target; /* Current target invocation */
_INVPTR Source; /* Source invocation */
_SPCPTR Com_Area; /* Communications area */
char Compare_Data[32]; /* Compare Data */
char Msg_Id[7]; /* Message ID */
char reserved1; /* 1 byte pad */
_INTRPT_Mask_T Mask; /* Interrupt class mask */
unsigned int Msg_Ref_Key; /* Message reference key */
unsigned short Exception_Id; /* Exception ID */
unsigned short Compare_Data_Len; /* Length of Compare Data */
char Signal_Class; /* Internal signal class */
char Priority; /* Handler priority */
short Severity; /* Message severity */
char reserved3[4]; /* reserved */
int Msg_Data_Len; /* Len of available message data */
char Mch_Dep_Data[10]; /* Machine dependent date */
char Tgt_Inv_Type; /*Invocation type (in MIMCHOBS.H)*/
_SUSPENDPTR Tgt_Suspend; /* Suspend pointer of target */
char Ex_Data[48]; /* First 48 bytes of excp. data */
} _INTRPT_Hndlr_Parms_T;Ну дальше в нем уже делай что хочешь. Можно в языковое исключение преобразовать при желании.
В другом языке на это платформе более близкое к try/catch:
MONITOR;
OPEN badfile;
ON-EXCP 'CPF4101';
status = %status();
DSPLY ('Message CPF4101, status ' + %char(status)); // 1
ON-EXCP 'RNX1217';
DSPLY 'Message RNX1217';
ON-ERROR 1217;
DSPLY 'Status 1217';
ENDMON;Тут без расшифровки текста ошибки (это отдельное API системное).
Аналогом throw будет
SND-MSG *ESCAPE %MSG('ABC1234' : 'MYMSGF') %TARGET(*SELF);Прерывающее сообщение с кодом ABC1234 и данными MYMSGF отправляемое "самому себе" (но можно и куда-то еще)
%TARGET(*SELF | *CALLER | program-or-procedure {: offset-in-program-stack })Т.е. внутри процедуры (или программы) в нужных местах делаем snd-msg, саму процедуру (или программу, которая тут фактически от процедуры не отличается в плане вызова) вызываем внутри блока monitor и прописываем нужные блоки on-excp. Полный аналог try/throw/catch в языке, где механизм исключений не поддерживается.
Еще в другом языке будет примерно так:
CALL PGM(SOMEPGM) PARM(&whatever)
MONMSG MSGID(MYM2101) EXEC(DO)
/* do something */
ENDDO
MONMSG MSGID(MYM2105) EXEC(DO)
/* do something else */
ENDDOНо суть в том, что все это на уровне системы работает. Т.е. даже в тех языках, где нет механизма языковых исключений, всегда можно использовать системные (и это будет более универсально). Ну и плюс в том, что исключение может возникнуть где-то внутри какого-то системного API, но вы его можете точно также перехватить.
Например, тут есть такая вещь "машинные инструкции" (это вместо ассемблера, который недоступен для разработчика). Ну и есть С-шные обертки для некоторых инстукций. В частности, есть MI _DEQWAIT - чтение из очереди (системный такой объект) с таймаутом. И вот эта MI, если очередь пустая и не дождались чего бы оттуда прочитать, просто бросает системное исключение. Которое перехватывается хендлером, а дальше, если код ошибки MCH5801 (вылет по таймауту), просто сбрасывается - ничего страшного не произошло, просто нечего читать.
Помнится, в виндах тоже было что-то такое, хоть и менее навороченное. Но оно никак не мапится в собственно язык.
В смысле, никак не маппится?
Вы про SEH в Винде? Как это не мапится. В MS-овском компиляторе поддержка этого механизма исключения внесена (как расширение языка) как для C++, так и для C в виде конструкций __try/__except. В Visual Basic вплоть до 6-го и в VBA этот механизм используется для выброса и отлова ошибок, с единственной оговоркой, что методы классов вместо выбрасывания исключения наверх прибегают к возврату HRESULT-а наверх.
А не подскажете как поймать в Java исключение выброшенное в Rust?
Легко! Ибо в Rust нет исключений.
Зато там есть паники.
Паника, это такой assert(false) на стероидах. Соответственно и дергать ее надо когда вы, как программист, обнаружили нарушенный инвариант.
Ну да, а catch_unwind придумали идиоты просто так :)
Не просто так. Они еще и написали когда это стоит использовать, а когда - не стоит. Но кто ж читает документацию, правда?
It is currently undefined behavior to unwind from Rust code into foreign code, so this function is particularly useful when Rust is called from another language (normally C). This can run arbitrary Rust code, capturing a panic and allowing a graceful handling of the error.
It is not recommended to use this function for a general try/catch mechanism. The
Resulttype is more appropriate to use for functions that can fail on a regular basis. Additionally, this function is not guaranteed to catch all panics, see the “Notes” section below.
Но кто ж читает документацию, правда?
Конечно, кто же читает документацию, в которой чётко написано, что graceful handling паник вполне возможен, а при переходе через ABI boundary обязателен. Теперь расскажите, пожалуйста чем это принципиально отличается от выброса плюсового исключения в случае вызова из java кода.
Потому что нет Rust ABI. Нет его. Есть стандартный системный ABI который описывает как вызывать функции и как возвращать значения.
Что вы вообще так уцепились за эти исключения? Я говорил о том что С++ ABI не существует и в качестве одного примера сказал что нельзя бросаться исключениями.
Напоминаю, что все началось с вот этого комментария:
На C++ (как и на C) можно написать библиотеку и использовать её в десятках других ЯП. Rust так умеет?)
На что я совершенно резонно заметил что никакого С++ ABI нет. Все равно на стыках надо реализовывать всем понятный C-style ABI и соответственно никаких преимуществ у C++ перед C, Rust или там Fortran нет.
Вы, наверное, имеете в виду "нет стабильного ABI". Утверждение, что ABI ну совсем нет, выглядит забавно. Просто оно compiler-specific. Но в целом все так, хочешь использовать плюсовый или растовский код в других языках - придётся обернуть его в C ABI. Просто ответ на вопрос "умеет ли язык X интегрироваться с другими языками?" будет "можно ли обернуть его в C ABI"? Так что я бы сказал, что и раст и плюсы это в некотором роде оба могут.
Я-то об этом знаю. Но вот поймать панику из Rust в java будет настолько же нереально. Потому как у Rust тоже нет стабильного abi. Нет даже стабильной раскладки структур, если не использовать repr(c), который о ужас, достался от ужасного C( ну т.е. ничем не отличается от c++ )
Если код в Rust кидает панику, значит он обнаружил где-то нарушение инварианта и состояние программы больше не консистентно. Ловить панику чтобы потом продолжить работу - не имеет смысла.
Тем не менее catch_unwind существует. И вся стандартная библиотека написана с учётом такой возможности
catch_unwind не только существует, но к нему еще и существуют правила его использования. И основная его цель - это недопустить пролет растовской паники за пределы FFI. Это не замена try/catch. Документация явно об этом говорит.
относительно быстро устранит большинство ошибок диапазона
Ну и что же не устранили до сих пор? Или каков там порядок вашего "относительно"?
Страуструп словно специально не замечает, что проблема не в отсутствии механизмов, а в неадекватных параметрах по умолчанию. Прошли те времена, когда все можно было держать в голове.
Все эти споры полная ерунда. Все языки создаются для эффективного решения задач. И на текущий момент только С и С++ позволяют решать любую задачу достаточно эффективно. Есть и другие языки которые стремятся к этому... но практически всегда им приходится поступаться своими преимуществами безопасности либо применяя unsafe конструкции, либо пряча это за обращением к внешним библиотекам написанным на С/С++ сохраняя видимость чистого safe кода. Это страусиная позиция какя-то. Я давно начинал изучение языков с чистого Паскаля на СМ-4. Вот там все надежно и безопасно, но хрен чего эффективно сделаешь, а доступа к железу так вообще не было предусмотрено...И при этом все гораздо веселей писалось на turbo pascal на pc-xt... а когда начал работать с железом так альтернатив С не было...можно было конечно использовать turbo pascal, но там все было несколько сложней. А так вообще индустрия движется куда-то не туда создавая кучу ненужного мусора в средствах разработки чтобы увеличить хаос и придать значимость роли программистов.
Использование сторонних библиотек - это не "страусиная позиция", а декомпозиция задачи.
Задача-то не в написании safe кода, а в написании безопасного и безошибочного кода.
На практике я писал приложуху на С# либо с unsafe, либо писал либу на плюсах который типа небезопасный и сколько я там косяков спрятал никто не знает. Причем часто в либу прячется то, что средствами безопасного языка выражается очень сложно и запутанно, но типа безопасно... а тут спрятал грязную работу с указателями и ништяк. Есть такая среда разработки LabView. Там можно нарисовать очень сложные вещи проводками и кубиками, но это будут ужасные простыни картинок, а можно было спрятать кучу всего под капот в DLL и CIN и получить красивые блок-схемы программы... Так и со всеми этими safe языками..
Если вы сделали неправильно - это не значит что все остальные делают неправильно.
главное я знаю что я не одинок это раз. потом поскольку все идет эволюционным путем, то в проекте переписывается часть (например фронт) в современном модном стиле, но под капотом сидят старые странные unsafe модули..или наоборот. это два. это просто жизнь, реальность. и собственно непонятно что лучше - разводить зоопарк модных языков в проекте или использовать старый добрый С++ придерживаясь определенных ограничений и стиля.
Т. н. языки с "безопасной" памятью на самом деле тоже обладают ворохом проблем, приводящих к низкой надёжности ПО.
В какой-нибудь Java все композитные типы ссылочные и ссылки могут быть нулевыми, что порождает широчайшие просторы по прострелу ноги через NullPointerException.
В каком-нибудь Python типизация динамическая, что вызывает иногда ошибку типов в процессе выполнения, если тип не тот, что ожидался.
В (прости господи) Javascript ещё хуже - при ошибках типизации программа не падает, а просто выдаёт мусор, пытаясь (например) складывать массивы с объектами.
Исходя из вышеперечисленного, я бы на месте властей США ещё бы какой-нибудь декрет издал, запрещающий языки без строгой статической типизации и без незануляемых типов по умолчанию.
Речь скорее идет про Rust, а не про Python или Java. В rust нет нулевых указателей и динамической типизации тоже. Так что описанных вами проблем нет. Это не означает полное отсутствие проблем или ошибок, просто некоторые классы проблем просто отпадают и проверяются самим компилятором.
Понятно, что в Rust то проблем всех этих нету. Я только за.
Мне только не нравится, что наезжают на C++, не упоминая существенных недостатков других языков, переход на которые может быть стимулирован такими наездами.
Правильнее тут было бы издать распоряжение вообще о приоритете Rust, а не о том, что дескать только C++ имеет существенные недостатки.
По сравнению с rust, java и python, C/C++ имеет принципиальный недостаток в работе с памятью. К сожалению, принцип "нормально делай - нормально будет" работает плохо, особенно на масштабе. А чтобы безопасную работу с памятью в плюсах сделать обязательной, нужно ломать обратную совместимость, но на это вряд ли пойдут, так как вместе с недостатком, это и достоинство плюсов.
по прострелу ноги через NullPointerException
У джавы есть недостатки, но это точно не один из них) Мне сложно представить что нужно сделать чтобы побить данные или получить дыру в безопасности из-за NPE, сам же эксепшен сразу виден в логах и фиксится за считанные минуты. Ну то есть можно конечно писать пустые кэч-блоки и скипать целые части воркфлоу из-за этого, но таким господам никакой язык не поможет)
Вот конкретно NPE не фиксится, если специально этим не озаботиться.
На С++ есть необходимость выработать свой стиль написания, и думать самому о безопасности кода. Это - та самая свобода, которую на словах все хотят, а на деле её, свободу, избегают :-)
можно было бы и не читать что ответит создатель С++.
на самом деле уже не важно какой язык программирования. в ближайшем будущем ИИ будет писать реализацию за нас. нужно ли вообще теперь изучать языки программирования или сосредоточиться на логике, алгоритмах, аналитике, паттернах и т.п.? думаю сейчас кто-то где-то разрабатывает языки (безопасные?) метапрограммирования для всяких там копилотов и прочих ИИ. эволюция делает очередной виток.
Вот просто очень интересно, неужели вы действительно думаете что ваше славное "светлое" ИИ-будущее, будет доступно всем смертным так же как доступно программирование (со всеми смежными областями)?
Ведь мы же не говорим про завалить глупыми вопросами, на свои темы, chat gpt. А про написание целой архитектуры, лишенной не только различных багов по недосмотру, но и лишенной проблем с производительность, масштабированием, переносимостью, да даже дизайном. И все это, конечно же, будет доступно потому что мы этого хотим. Вы правда в это верите ?
ну какрй нафиг ИИ... он как только выйдет в свободное плавание отравит себя точно также как сейчас отравлен Интернет-поиск. Причем травить будет сам же себя. Или по жизни будет сидеть под надзором людей в лаборатории и будет обучен на их субъективном восприятии правильного.
похоже вы ничего из написанного не поняли.
программирование и сегодня не всем доступно. иногда даже тем, кто называет себя программистом. а в ближайшем будущем именно благодаря копилотам и т.п. программирование станет проще и доступнее. я уверен в этом. так же как и в светлом будущем. за исключением, разве что, фашистской РФ.
сегодня почти никто не программирует на перфокартах и ассемблере. хотя 20 лет назад это был обычный навык для большинства, включая меня самого. сегодня практически никто уже не пилит самодельные велосипеды, а пользуются готовыми фреймворками, сторонними библиотеками, решарперами, копилотами и т.п. я на 100% уверен, что завтра вместе с копилотами мы все будет метапрограммировать. и освоить язык метапрограммирования копилота тому же биологу будет проще, чем освоить C++ STL математику.
в данный момент у меня копилота заменяют джуны и мидллы,тупо пищущие код. а я программирую решения.
Полностью согласен с Бьярном, первое, о чём подумал - что на этих новых языках можно точно так же наворотить.
Это вопрос именно технологии и соблюдения процедур, а не волшебных безопасных языков. Переписывая на которые придётся таки эти процедуры соблюсти.
C++ конечно позволяет писать небезопасно, но ведь и условный "безопасный" C# тоже даёт такую возможность. Просто сборка помечается как небезопасная, поступайте с ней на ваше усмотрение.
Так давайте двигаться в эту сторону, если на "плюсах" соблюдены все правила безопасности, компилятор и/или анализатор подписывают сборку как безопасную, а остальные пусть конечно работают, но все будут знать, как они сделаны.
Предупреждён - значит вооружён.
Полностью согласен с Бьярном, первое, о чём подумал - что на этих новых языках можно точно так же наворотить.
Там весь цимес в том, что на новых языках чтоб наворотить - нужно приложить усилия. Т.е. проявить прямо злонамеренное целеустремленное упорство.
А чтоб на С++ нужно наоборот - почти всегда прилагать усилия, чтоб НЕ наворотить. Т.е. нужно проявить упорство, опыт, знание и прочее чутье, чтоб реализовать что-то доброе вечное, из лучших побуждений. А вот нечаянно наворотить, отстрелить себе что-то (особенно в чужом коде) - это, увы, поведение практически по дефолту.
В этом плане американских законодателей можно только поддержать. Сначала нужно привести С++ к нормальному поведению по-умолчанию (и кстати вообще убрать неопределенные поведения), а потом уже рекомендовать везде и всегда использовать.
Есть платформы с сатурацией и без сатурации. Это когда MAX_INT + 1 дает - MAX_INT, или дает 0 на других.
Это зависит от процессора, его архитектуры и прочих деталек реализации. Убрать UB по конкретно этому случаю = прикрутить обязательные проверки на каждый плюс минус с соответствующим оверхедом, чтобы что?
Ребус: `-5 % 2` дает что? (-1/+1/какое-то повторяемое беззнаковое число).
Неопределенное поведение это очень важный механизм языка и решать такие вопросы наскоком имея далеко-идущие проблемы с перформансом на других платформах это очень странно и жава вей.
А главное... зачем? Ну не будет в языке UB, теперь вы определенно будете звать std::terminate при обращении по указателю инта ко флоту, кто выиграл то?
Вы смешали в кучу unspecified и undefined behaviour.
Есть платформы с сатурацией и без сатурации. Это когда MAX_INT + 1 дает - MAX_INT, или дает 0 на других.
Ну есть и есть, делов-то. Я помню лишь один-два алгоритма, которые прям явно используют целочисленное переполнение. Расчет sha-1, md5 и возможно что-то еще. Покрывается это тестами и прочими #ifdef.
А вот дальше есть два варианта - или код прям гарантированно валиден и никогда не приведет к переполнению, или при переполнении можно попасть на неопределенное (как минимум непротестированное) поведение. И вот тут я бы лично хотел иметь опцию - или вот прям отдельный от int/long специальный тип, который явно разрешает переполнение (типа программист знает что делает), и int/long, которые абсолютно всегда проверяются на переполнение (благо там копейки - OF/CF флаг проверять и делать jmp на секцию с abort()).
Причем переполняемому типу еще и штатную арифметику запретить, пусть через интринзики мучаются, если им сильно надо (а не наоборот, как сейчас с этими вашими __builtin_add_overflow ).
Да, для какого strncpy() внутри проверка на overflow избыточна - вот и ладушки, пусть они это явно там себе это отдельным типом, производным от size_t обозначат и потом еще и обоптимизируются по самое небалуйся на ассемблерах. Но почему остальные должны от потенциальных дыр страдать, раз они там в glibc все такие прям красивые и умные?
А вот про алиасинг и кастинг float к int не так интересно.
OF/CF флаг проверять и делать jump() на секцию с abort()
Когда инженеры АМД пилили х86_64, они провели довольно тщательный анализ легаси инструкций, которые можно было бы выкинуть и не тащить в прекрасное 64-битное будущее.
Ну, возможно, вы слышали про инструкции LAHF/SAHF, которые достались x86 от i8085 по недосмотру. Их выпилили, а потом пришлось впиливать назад из-за вмвари.
А вот за инструкцию INTO никто не вступился, потому что она никому не нужна.
Если вы запамятовали, эта однобитная инструкция проверяет флаг OF и, если он установлен, вызывает INT 3.
"И так сойдёт"
Я, может, крамольную и не особо лицеприятную мысль скажу, но, как по мне, так если ты не в состоянии правильно работать с памятью, то не фиг тебе лезть в сколь-либо серьезное программирование.
Ничего волшебного в этом нет, и раньше это был своеобразный порог, который нужно было напрячься и пройти. А что сейчас? Проще-проще-проще... Безопаснее-безопаснее-безопаснее... Порог ниже-ниже-ниже... В итоге пришло такое количество людей в профессию, глядя в код которого хочется плеваться. И такое положение вещей только усугубляется. До кухарок в ИТ хотим добраться?
Кухарок стало настолько много, что они еще и минусуют сообща за нападки на их кухарские идеалы.
если ты не в состоянии правильно работать с памятью, то не фиг тебе лезть в сколь-либо серьезное программирование
Ничего волшебного в этом нет,
Ничего волшебного в этом действительно нет, просто нужно написать свой потокобезопасный gc для графов:)
Потому что если объекты в вашей программе образуют граф нефиксированного размера и не являющийся деревом, то подсчёт ссылок и пулы объектов уже не работают, и в общем проект перестаёт быть томным.
вы не думали, что гц просто не нужен?
Потоки кстати тоже не нужны. Почти всегда заменяются асинхронным I/O, где нужно в конкурентный доступ извне, и многопроцессностью (не многотредностью), где нужно терабайты данных в каком ML пережевывать.
На текущем уровне развития IT наличие потоков в прикладном коде - это явный сигнал о кривой архитектуре и весьма слабом понимании современного оборудования (L3/NUMA и прочих когерентностей кешей).
Сомневающимся прописать срочное изучение паттерна LMAX Disruptor, потом много думать.
Да, давайте вместо выполнения work item на пуле потоков дергать fork каждый раз, это же будет намного быстрее и гораздо эффективней по памяти.
Да, давайте вместо выполнения work item на пуле потоков дергать fork каждый раз, это же будет намного быстрее и гораздо эффективней по памяти.
Как там выше говорили, комментировать, только портить?
Почему можно иметь пул потоков, но нельзя иметь пул процессов, предварительно зафорканых и общающихся между собой через mmap() области (shm)?
Почему отдельных процессов - так изоляция памяти же, защита от dangling pointer, все такое. И в виде маленького довеска - отсутствие необходимости синхронизации, только message passing в стиле Erlang.
Типа дорого форкать? А если через clone()? CoW и все такое. Можно и продолжить, но боюсь сейчас опять понабегут минусющие с остывшим латте со смузи, гневно шатать трубу несправедливости :) Как это так, они ведь так верили в эти ваши threads, книжки изучали всякие умные, мутексы, семафоры, локфри, атомики, это что, все зря было, да?
Да при чем тут смузи. Процессы дорогая штука сама по себе. Они могут быть оправданны, например, если вам надо запускать их под разными юзерами (скажем принт-сервер, у каждого юзера свои права). Но в простых случаях это ненужный оверхед на ровном месте.
Процессы дорогая штука сама по себе
В Windows - да. Но в Linux процесс отличается от треда только флажками доступа к памяти. clone() далается моментально, R/O сегменты кода шарятся, куча и даже стек - тоже физически по страницам памяти шарится, до первой попытки записи (после этого по CoW создается для порожденного процесса копия 4к байтной страницы).
В чем там "более дорожесть" - вообще загадка.
Зато разделение доступа к памяти между процессами - незаменимая штука (при том, что процессы могут иметь и разделяемую память через mmap() даже по одним и тем же базовым адресам замапленную, и обмениваться pointers даже без необходимости пересчета offsets.
Подобный подход (разделить процессами стеки и кучу на приватные области, и сделать сугубо отдельную shared кучу) просто в букварях не преподают, сначала страшно конечно, пока не попробуешь.
Но в простых случаях это ненужный оверхед на ровном месте.
В чем именно оверхед? только сначала почитай(-те) man clone :)
man fork читать не надо, это по факту просто обертка над clone(), чисто как дань предыдущим поколениям, куда насовали старых натужных благоглупостей для совсем ненужной совместимости.
Спасибо, я примерно представляю, как clone реализован:)
Отдельное адресное пространство не бесплатно.
Переключение адресных пространств не бесплатно.
CoW не бесплатен.
Нужны веские аргументы, чтобы всё это оплачивать. Например, если у меня числодробилка, которую я хочу запустить на всех имеющихся ядрах. Или наоборот, если у меня тот самый принт-сервер и я хочу максимальную изоляцию, то мне не нужны эти ваши CoW, общие файловые дескрипторы, общие куски шелла, ENV и т.д., я вообще не хочу ничего общего, дайте мне честный CreateProcess, который заново отобразит мой исполняемый файл на новые виртуальные адреса со второй виртуальной страницы.
Не везде. Есть платформы, которые изначально проектировались как многопользовательские. И там все что работает, работает в своем задании (job). Изолированном от всех остальных и позволяющем устанавливать свой набор настроек (jobd). Имеющим свой лог (joblog) который автоматически ведется системой и свою очередь сообщений.
Для задания, например, можно разрешить или запретить потоки внутри него.
Зашли терминалом - каждое терминальное окно - отдельное интерактивное задание. Запустили программу через spawn - она будет работать в новом, отдельном фоновом задании.
А еще система может быть устроена так, что накладные расходы на переключения контекста задания могут быт сведены практически к нулю.
И тут есть ряд преимуществ.
В отличии от потока, падение одного задания не приведет к падению всех остальных (при параллельной обработке)
В отличии от потоков задания полностью изолированы друг от друга - одно задание никак не сможет случайно залезть в память другого. Обмен данными только через специально организованные каналы (например, pipe) или специально же объявленные области разделяемой памяти.
Состояние заданий легко мониторится сопровождением (в т.ч. доступен в реальном времени мониторинг джоблогов) и при необходимости принудительно остановлено извне без ущерба для всех остальных.
Т.е. задание можно рассматривать как некий изолированный контейнер.
Согласитесь, что это куда более безопасно чем потоки (мы же тут за безопасность, нет?)
общающихся между собой через mmap() области (shm)
отсутствие необходимости синхронизации
Так будет гонка на доступе к общей области памяти и всеравно нужно будет делать механизм синхронизации, мемори барьеры и прочее.
message passing в стиле Erlang.
Посмотрите как он имплементирован. Заодно подумайте или почитайте почему в эрланге сделали акторную модель. Почитайте какой overhead вносит message passing между акторами и почему.
Типа дорого форкать? А если через clone()?
А как по вашему pthread_create реализована? Вы думаете не через clone?
Можно и продолжить
А можно не продолжать, потому что когда вы реализуете полноценный пулл процессов с шаренной памятью, синхронизацией и всеми оптимизациями, то получите либо ту же самую систему потоков, только самодельную и ограниченную, либо заново изобрете акторную модель, давно пора, всего то 50 лет в прошлом году исполнилось с момента ее создания Карлом Хьюиттом. И ради чего - просто чтобы быть "не таким как все"? Это особенно иронично звучит на фоне той ерунды про "минусющих с остывшим латте со смузи", которую вы повторяете из комментария в комментарий как заезженная пластинка.
Так будет гонка на доступе к общей области памяти и всеравно нужно будет делать механизм синхронизации, мемори барьеры и прочее.
Я так понимаю выше про LMAX Discruptor почитать не удалось? Это печально конечно. Ну можно еще про кольцевой буфер почитать, про lock free алгоритмы всякие.
А как по вашему pthread_create реализована? Вы думаете не через clone?
Вопрос не как, вопрос зачем. fork() и pthreads (равно как и System V IPCs) - это просто тормозные слои обратной совместимости. Которые и изначально были когда-то сделаны криво, и в Linux реализованы тоже криво, там в самих API и поведенческих контрактах проблема.
Это все "великолепное" наследие заменяется прямыми обращениями к clone() и mmap(). Ну и __atomic интринзиками (из которых нужен лишь CAS).
В 2024-м году говорить о необходимости совместимости с FreeBSD, Solaris и AIX ведь уже не надо, или все еще надо? Серъезно?
Ну можно еще почитать про lock free алгоритмы всякие.
они ведь так верили в эти ваши threads, книжки изучали всякие умный...локфри, это что, все зря было, да
Вы в своем хамаватом самодовольстве сами не замечаете как себя противоречите. И то, что вы сначала пишите что синхронизация при mmap не нужна, а потом начинаете рассказывать какие именно подходы для синхронизации надо будет использовать просто говорит о проблемах в логике ваших рассуждений.
И то, что вы сначала пишите что синхронизация при mmap не нужна,
Нет, синхронизация не нужна в классическом понимании - мутексы, семафоры, спинлоки, критические секции, барьеры, pthreads API эти ваши и прочее. Походы в ядро за всем этим. Там сверху была пугалка дескать как в Erlang передавать сообщения это ой как страшно и тяжело. Нет, не тяжело. Запросто 10M в секунду пинг понгов на домашнем ноутбуке.
Там для передачи сообщений между процессами и нужен по сути только CAS. Можно и вовсе без него, просто на memory barrier (для разных CPU есть и другие вариации). Поход в ядро и специальный API точно не нужен, только немного интринзиков или ассемблера.
И при чем тут моя хамоватость? Я уже третий раз вежливо прошу сходить посмотреть на Disruptor, и что, кто-то сходил посмотрел? Проще меня обвинять в чем-то там, чем самому почитать-подумать? Ну если читать-думать самому не хочется, то почему я виноват?
олько самодельную и ограниченную, либо заново изобрете акторную модель, давно пора, всего то 50 лет в прошлом году исполнилось с момента ее создания Карлом Хьюиттом. И ради чего - просто чтобы быть "не таким как все"?
Про ограниченность поулыбало, но то ладно.
И ... да, не такой как все. Защитное программирование, все такое. Не нужно совсем?
Как все делать - это когда любой залетевший дятел в сессии веб сервиса может пойти и почитать и пописать в соседние чужие сессии чего ему там вздумается. А в правильной процессной модели (с общей памятью, но обвешанной mprotect()) - он может погулять только в своем локальном контексте арене, при попытке почитать-пописать в соседнюю сессию он получит SIGSEGV.
Не, такое совсем не нужно? Лучше иметь полностью доступную и беззащитную кучу одну на всех?
О да, ойляля, натюрлих, фантастиш :)
Но не надо минусов, господи. Да, в букварях учат иметь строго общедоступную незащищенную кучу, я понимаю, увидеть, что можно иначе - это пока еще не пришли дяди архитекторы из США с книжками-слайдами и не показали на примере гугла какого историю успеха. Может и не придут.
это когда любой залетевший дятел в сессии веб сервиса может пойти и почитать и пописать в соседние чужие сессии чего ему там вздумается А в правильной процессной модели (с общей памятью, но обвешанной mprotect()
Ну есть pkey_mprotect для того же самого в мнопоточной среде, если оно нужно. Даже прямо в документации пишут:
PKRU is inherently thread-local, potentially giving each thread a different set of protections from every other thread.
Да, в букварях учат иметь строго общедоступную незащищенную кучу, я понимаю, увидеть, что можно иначе - это пока еще не пришли дяди архитекторы из США с книжками-слайдами и не показали на примере гугла какого историю успеха.
Это у вас уже какая-то сверхидея собственной исключительности.
Ну есть pkey_mprotect для того же самого в мнопоточной среде, если оно нужно. Даже прямо в документации пишут:
И что что есть? Как это может помочь с fail fast / SIGSEGV ?
Ну вот прилетел хакер-дятел в вебсессию, почитал что ему не положено. И весь процесс кирдык и навернулся в корку, вместе с другими сессиями и веселыми тредами, кому легче стало?
А если у меня живут отдельные процессы воркеры для пережевывания реквестов - то отмирание отдельного процесса-обработчика пользовательского запроса лишь побеспокоит тоже отдельный процесс сервис монитор, чтоб он зареспавнил в пуле этого временно выбывшего из строя воркера. Хакер-клиент же спокойно получит свою 500-ую, остальные даже не заметят локальной катастрофы.
Это у вас уже какая-то сверхидея собственной исключительности.
Боже упаси. Это все давно известные и вовсе не мои идеи. Я единственно просто не могу найти их собранные в одном нормальном бэкэнд фреймворке, только в разбросанные частях в разных имплементациях разных людей, еще и на разных языках. А вот чтоб целостно - увы такого ни у кого нет, и это удручает, т.к. заниматься продуктизацией и популяризацией очередного userver или какого еще одного тарантула не сильно и перспективно, даже нелепо.
Хакер-клиент же спокойно получит свою 500-ую, остальные даже не заметят локальной катастрофы.
Если мы говорим про child процесс, созданные через fork, то что мешает хакеру вызвать из дочернего процесса mprotect на все созданные mmap c MAP_SHARED и прочитать/записать все что нужно?
о что мешает хакеру вызвать из дочернего процесса mprotect на все созданные mmap c MAP_SHARED и прочитать/записать все что нужно?
Мы защитное программирование делали не сколько от хакеров, сколько от дятлов и багов (кстати помогает, судя по логам). А так - что-то мне подсказывает, что mprotect это по сути указатель на куда-то там, и этот указатель можно попробовать ловко скрыть, натолкать туда редирект какой, а реальный вызов mptotect() делать как-то отдельно, по команде от монитора процессов...
Но это уже пошел хакинг, интересный конечно, как таска для воскресного бэклога. И за наводку в pkeys спасибо, хотя выглядит это пока не сильно вдохновляюще (не всякий x64 сможет): https://www.kernel.org/doc/html/next/core-api/protection-keys.html
Но идея конечно зачетная. Треды друг от друга позабарикадировать. Мы треды применяем для Development/DEBUG режима, потому как обычно отлаживать в VSCode/LLDB кучу дочерних процессов вообще никакого удовольствия нет, надо c pid этими возиться и тормозит оно в отладчике прилично...
А так и повод железки обновить...
Так будет гонка на доступе к общей области памяти и всеравно нужно будет делать механизм синхронизации, мемори барьеры и прочее.
Шареная память нужна далеко не всегда. Только там, где мегакритично быстродействие именно транспорта.
Просто обмен информацией (там, где скорость этого обмена не является бутылочным горлышком) между заданиями возможно организовать через систему "почтовых ящиков" (например, unix sockets) или конвейера (например, pipe).
И тогда не будет никаких проблем с синхронизацией.
Да можно, да есть задачи где постоянно копирование данные будет не критично. Есть задачи где разделение на саб-процессы сделает систему устойчивей. А есть задачи где постоянное копирование данных критично, где несколько лишних микросекунд будут влиять на работу приложения. Речь же не про то, что мы не можем использовать fork модель для асинхронной работы, а про то, что утверждение "потоки используют только люди с низким уровнем квалификации и везде надо переходить на модель с fork/clone" мягко говоря спорное.
Да, согласен. Писал об это (ниже или выше?) что конкретное решение от задачи должно идти.
Просто утверждение "везде использовать только потки, но не процессы (задания)" столь же спорное. В каждом конкретном случае решение стоит выбирать принимая во внимание все факторы.
Мне вот больше приходится работать с задачами параллельной обработки больших объемов данных (десятки и сотни миллионов элементов, обработка каждого независима от остальных и занимает определенное время). И тут применяется несколько заданий-обработчиков + одно головное, которое раздает данные. При этом приходится следить за состояние конвейера чтобы он не переполнялся т.к. скорость раздачи всегда выше скорости обработки и разбора. Увеличивать количество обработчиков тоже бесконечно нельзя т.к. это далеко не единственная задача системы и есть ограничения по количество процессорных ресурсов на нее выделяемых. Т.е. всегда балансируем между временем выполнения и общей загрузкой системы.
При этом приходится следить за состояние конвейера чтобы он не переполнялся т.к. скорость раздачи всегда выше скорости обработки и разбора. Увеличивать количество обработчиков тоже бесконечно нельзя т.к. это далеко не единственная задача системы и есть ограничения по количество процессорных ресурсов на нее выделяемых. Т.е. всегда балансируем между временем выполнения и общей загрузкой системы.
Подобные задачи даже на bash с его &, wait, sleep, +check $(jobs | wc -l) вполне себе успешно решаются. Треды то там зачем?
Можно пример задачи (область), где обработчикам нужно друг с другом общаться?
Ну вот задача с которой работаю сейчас.
Есть таблица клиентов. Сейчас там порядка ~50млн записей. У каждого клиента есть несколько адресов (разные типы - фактический, юридический, почтовый, регистрации и т.п.). В данном случае нас интересуют 5 разных типов. Т.е. 5 адресов на клиента. ~250млн адресов.
Есть таблица злодеев (террористы-экстемисты). Там... Точно не скажу, но несколько сотен тысяч персонажей. И у каждого несколько имен, несколько паспортов, несколько адресов. Короче, все по классике:
Она же Анна Федоренко, она же Элла Коцнельбоген, она же Людмила Огуренкова, она же..., она же Изольда Меньшова, она же Валентина Понеяд.
Задача состоит в том, что нужно составить список совпадений адресов (заполнить табличку в БД). Где будет Идентификатор клиента, идентификатор субъекта, тип адреса клиента и сам адрес по которому совпало.
Плюс условие - адреса нельзя сравнивать "строка в строку". Адреса
Российская Федерация, г.Урюпинск, Коммунистический тупик, д.6, кв.13и
тупик Коммунистический д.6 кв.13, г.Урюпинск, Российская Федерацияявляются одинаковыми.
Т.е для сравнения два адреса разбиваются на наборы элементов и сравнивается содержимое этих наборов.
Прикиньте количество комбинаций для сравнения :-)
И вот тут уже приходится работать в несколько потоков. Один поток - головной. Он делает выборку из БД (там тоже есть некоторые условия дополнительные) и выкладывает на конвейер пакеты с теми, кого надо обрабатывать. И есть несколько заданий-обработчиков. Которые берут с конвейера пакет и обрабатывают его содержимое.
Естественно, что обработчики между собой не общаются никак - им это не нужно. Состояние обработчиков (активен, выпал в ошибку и т.п.) отслеживается головным заданием (там на разные ситуации есть разные действия).
Разными ухищрениями удалось добиться времени обработки порядка часа (чуть меньше) на 120-ти ядрах power9 в 5 потоков-обработчиков. При этом загрузка машины незначительна т.к. это всего лишь один и тысяч разных процессов которые там крутятся одновременно и тянуть на себя слишком много ресурсов нельзя (там вообще не допускается общая загрузка машины более чем на 60% в нормальном режиме т.к. всегда должен быть запас на случай периода пиковых нагрузок). Т.е. любая поставка проходит через нагрузочное тестирование на копии промсреды со снятием статистик специальным инструментом (PEX - PErformance Explorer - интересная штука, очень много чего показывает и всегда можно увидеть на что внимание обратить). Там вот такого план картинки (представление можно менять для наглядности)
Т.е. там по стеку видны наиболее "тяжелые" места.
Т.е для сравнения два адреса разбиваются на наборы элементов и сравнивается содержимое этих наборов.
Прикиньте количество комбинаций для сравнения :-)
Возможно не совсем понял задачу, но мне кажется там нужно просто привести адреса к некоей нормальной форме (Субъект|Район|Нас. пункт|Улица|дом-строение|квартира-кабинет|) и потом просто отсортировать и так и обрабатывать потом потоком. Дефективные данные можно вычислить по непопаданию в КЛАДР (хотя это еще тот эталон) и отдельно нечетким поиском. Да даже просто по кластеризации от имени улицы-проспекта-переулка можно уже сильно сократить поиск.
Естественно, что обработчики между собой не общаются никак - им это не нужно.
Ну вот, треды не нужны, синхронизация не нужна. Исходный блоб с данными лежит на диске, мапим его через mmap() в разных процессах и жуем себе данные каждый рабочий независимо друг от друга.
Но 50млн - это вроде совсем не много, базы данных такое пережевывают за секунды (минуты, если какие регексы туда в SQL запускать).
Возможно не совсем понял задачу, но мне кажется там нужно просто привести адреса к некоей нормальной форме
Заморочно это. Не так там все просто. И КЛАДР вообще не при делах т.к. адреса не только в РФ.
Исходный блоб с данными лежит на диске, мапим его через mmap() в разных процессах и жуем себе данные каждый рабочий независимо друг от друга.
Этот этап давно прошли. Не годится т.к. получаем неравномерную загрузку обработчиков - один отработал условно за час, другой работает 5 часов. Просто потому что процесс сравнения может занимать разное время. Количество совпадений (каждое из которых надо зафиксировать в БД) тоже разное.
Подход с конвейером, кода выкладываются небольшие (по 100, например, элементов) пакеты для обработки дает равномерную загрузку обработчиков и в сумме меньшее время обработки. Ну кто-то из обработчиков меньше пакетов обработает, кто-то больше, но в сумме они одновременно стартуют практически одновременно завершаются.
Такого рода задач у нас много и под них разработана библиотека где нужно просто прописать процедуру формирования пакетов для головного задания и процедуру обработки пакета доя обработчика. А все общие операции (запуск обработчиков, мониторинг их состояния, работа с конвейером) уже реализованы в библиотеке.
Но 50млн - это вроде совсем не много, базы данных такое пережевывают за секунды
Не... Смотрите. 50млн клиентов, у каждого 5 типов адресов. итого 250млн адресов клиентов.
300тыс субъектов списков (речь о списках Росфмнмониторинга - подозреваемые в экстремизме, подозреваемые в пособничестве терроризму, подозреваемые в распостранении оружия массового уничтожения, список ООН, список решений суда, по адресам нас интересуют только ПЭ и ППТ списки). У каждого три типа адреса и может быть не по одному адресу каждого типа. Ну для круглости считаем миллион адресов.
Итого 250млн х 1млн = 2.5х10^20 пар для поэлементного сравнения. И сравнивать нужно каждый день т.к. каждый день могут изменяться адреса у каких-то клиентов а примерно раз в неделю приходит новая версия списка и происходят изменения у адресов субъектов. А таблицы совпадений используются в процессах комплаенс-контроля (в т.ч. проверки при заведении нового клиента, контроль платежей и т.п.)
Но не все так плохо на самом деле. Во-первых, под эту задачу сделана витрина адресов клиентов. Три таблицы - в первой ПИН клиента, тип адреса, идентификатор адреса. Во-второй уникальные элементы (слова) адресов - слов, его идентификатор. Третья - связи - идентификатор адреса, идентификатор слова, номер слова с строке адреса.
Т.е. тут уже все по словам разложено. Витрина один раз заполняется и далее поддерживается фоновым процессом который отслеживает изменения адресов клиентов и актуализирует их в витрине.
Кроме того, для каждого адреса считается хеш, обладающий свойством коммутативности относительно элементов (не зависит от порядка следования слов в строке, только от набора слов). Этот хеш хранится в первой таблице витрины рядом с идентификатором адреса.
Точно такой же хеш считается для адресов субъектов списков и хранится рядом с адресом в таблице адресов субъектов.
Таким образом, нам не надо проверять поэлементное совпадение всех комбинаций. Только тех, для кого совпали хеши (а там получается очень высокая селективность) - это уже делается несложной выборкой.
Далее. Полная сверка делается только один раз, при начальном заполнении таблицы совпадений. Дальше уже работаем по дельте - или "от клиентов" с выборкой тех клиентов, у которых за прошедшие сутки були изменения в интересующих типах адресов, или "от субъектов" после загрузки очередной версии списка с выборкой тех субъектов, у которых были изменения в адресах.
С точки зрения разработки (с учетом имеющихся библиотек) нам все равно - делать все в одном задании или распараллеливать.
С точки зрения запуска тоже - запускается всегда одно головное задание, дальше оно уже все делает само.
Тредами практически не пользуемся. Более того, они запрещены для обычных заданий на уровне JOBD (функция создания треда в таком задании просто возвращает ошибку). Если надо - нужно запускать отдельное задание с JOBD где треды разрешены.
А вот задания - это обычный элемент работы с системе. Любая терминальная сессия - это отдельное интерактивное задание. Запустить программу в фоновом задании - хоть из терминала командой SBMJOB (Submit Job), хоть из программы С-шной spawn.
Отладка тоже без проблем - встроенный системный отладчик позволяет ставить брейкпойнты в тех программах, что будут работать в фоновых заданиях (сервисный брейкпойнт) и потом их перехватывать. Ну там пара лишних телодвижений, но в целом никаких проблем.
Если нужно в реальном времени смотреть - есть "очередь сообщений". Создаешь очередь, расставляешь в программе вывод трейсовых сообщений в очередь в нужных местах и в реальном времени смотришь что валится в очередь сообщений.
Поначалу это вся идеология немного непривычна, но быстро привыкаешь и все становится просто и естественно.
а про то, что утверждение "потоки используют только люди с низким уровнем квалификации и везде надо переходить на модель с fork/clone" мягко говоря спорное.
Никакого тут спора нет. Там вверху было обозначено - потоки обычно нужно просто заменять на асинхронный I/O (epool и т.п.), т.к. в большинстве случаев эти ваши треды просто используются для обхода ограничений этого вашего blocking I/O, а это и есть признак низкой квалификации. Хотя почти все так до сих пор и делают.
Да, не всякие библиотеки к каким базам данных умеют даже в наше время в асинхронность, но... таки да, легким движением руки неасинхронные базюки делаются асинхронными через пул коннектов к ним, там простительно.
А так чтоб прям кучу CPU нагрузить реальной нагрузкой - это еще надо задачи такие найти. Я лет 15 назад в бытность очень сильно удивился, когда даже на задаче обработки-перекодирования потокового видео со спутника замена многотредовой модели на асинхронное I/O дала прирост в 10 раз, нагрузка на CPU упала с 90% до 8-9%, и позволило подключить в 5 раз больше карт на каждый сервер, больше туда просто уже не влазило физически.
Потом и выяснилось, что pthreads и примитивы синхронизации в ядре - это еще та халтура наколеночная. Может для какого httpd apache с его 5 реквестами в секунду это и ок, но в целом... впрочем, в целом обычно и так все понятно, что треды - это не про перфоманс, а просто "хочется для резюме и опыта попробовать".
Простите, но как вам там живётся в 2004?
Нормальный асинхронный ввод-вывод уже тогда был лет 10 как (в нормальных ОС). Нет, я не про макросы типа FD_SET, а именно асинхронный в/в. И даже в линупс его завезли примерно к 2010. Лет 5 назад там так вообще нормально сделали.
Потоки сегодня нужны, ну, для параллельной обработки, когда у вас легко может быть сотня ядер.
Простите, но как вам там живётся в 2004?
В 2004м жилось замечательно, свежие девки (и это не только DevExpress), Delphi, IE6/Maxthon, Windows XP SP2, RHEL 3, Oracle 9iR2, Rock solid stuffs everywhere
Потоки сегодня нужны, ну, для параллельной обработки, когда у вас легко может быть сотня ядер.
Опять 25. Я говорю что потоки не нужны, т.к. в линапсе они сейчас почти ничем не отличаются от процессов. Зато потоки в отличие от процессов не имеют защиты по памяти (куча и стек как минимум).
Единственное значимое отличие - что gdb/lldb сильно туго умеют отлаживать сразу много процессов, это да, напрягает. Но это можно пережить, если для отладчика пересобирать проект в режиме - "ну ок, а вот теперь все наши дочерние процессы становятся тредами". Но и это нужно редко, только если интенсивный межпроцессный пинг-понг отлаживать.
Я больше говорил что pthreads давно пора выкинуть на помойку, вместе с System V IPCs. А все делать строго в один поток на одном единственном ядре единственного CPU - я такого нигде не говорил.
И даже в линупс его завезли примерно к 2010. Лет 5 назад там так вообще нормально сделали.
А epoll() и 10к начали активно форсировать емнип только в 2009-2012м, довели до ума сильно позже, считай что позавчера.
А libaio ужасы - там я уже не помню, но кажется в Userland создавались пулы потоков, которые вокруг blocking I/O крутились, в общем костыль какой-то был сильно странный для Oracle, больше его никто и не использовал.
Это все сильно древние и темные времена и уже давно бесполезные знания, вроде навыков в FreeBSD. Осталось только про himem.sys чего вспомнить :)
Почему можно иметь пул потоков, но нельзя иметь пул процессов, предварительно зафорканых и общающихся между собой через mmap() области (shm)?
Только вот работа с памятью, разделённой между процессами, куда сложнее работы с памятью, разделённой между потоками. Куча языков программирования из коробки поддерживают второй способ, всячески ставят палки в колёса первому.
Ну и ещё тут вопрос есть - а зачем? Зачем делать пул процессов в условиях, когда пул потоков делается гораздо проще?
Ну хотя бы потому что пул потоков менее безопасен чем пул процессов. И менее управляем.
Вот вы работаете в сопровождении. И видите что какая-то задача, которая давно должна была завершиться, все работает и работает. Ваши действия? Вы можете только грохнуть всю задачу целиком, не понимая что там внутри происходит.
Если у вас пул процессов, то вы видите состояние каждого процесса. И можете увидеть что 9 из 10-ти работают нормально (или уже завершились), а 10-й выпал в ошибку (или продолжает работать когда остальные 9 давно завершились). И вы можете принудительно завершить этот процесс, никак не затронув все остальные.
Также вы для каждого процесса можете строит свое индивидуальное окружение. Вы можете быть уверенны, что никакой процесс случайно не залезет в память к соседу.
Насчет работы с памятью - не настолько сложнее, насколько вам это кажется. Разделяемая между процессами память поддерживается практически в любой системе. Вместе со средствами ее синхронизации.
Да и, как уже говорил, далеко не всегда нужна именно разделяемая память. Часто вполне достаточно (если речь идет о параллельной обработке больших объемов данных или обработке каких-то потоков в стиле "принял, трансформировал-передал дальше") реализовать механизмы почтовых ящиков или конвейеров, не требующих разделяемой памяти, но использующих системные средства межпроцессной коммуникации.
На самом деле, тут каждый механизм по-своему хорош и имеет как плюсы, так и минусы. И выбор конкретного механизма идет от конкретной задачи. И даже их сочетания в виде пула процессов, каждый из которых содержит в себе пул потоков.
Просто надо уметь и то и другое, не упираясь во что-то одно любой ценой, и понимать особенности работы разных подходов. Тогда сможете максимально безопасно и эффективно решать широкий круг задач.
Вот вы работаете в сопровождении. И видите что какая-то задача, которая давно должна была завершиться, все работает и работает. Ваши действия? Вы можете только грохнуть всю задачу целиком, не понимая что там внутри происходит.
Только вот не любая задача в принципе может оказаться в такой ситуации.
Просто надо уметь и то и другое, не упираясь во что-то одно любой ценой, и понимать особенности работы разных подходов. Тогда сможете максимально безопасно и эффективно решать широкий круг задач.
Вот именно, надо уметь и то и другое. А не заявлять как мой оппонент выше - "На текущем уровне развития IT наличие потоков в прикладном коде - это явный сигнал о кривой архитектуре"
Только вот не любая задача в принципе может оказаться в такой ситуации.
Увы, но за 30+ лет практики убедился что рано-поздно может случиться то, что кажется невозможным.
А дальше уже встает вопрос о цене ошибки. Или игрушка вылетела, или Вася не смог зарядник на маркетплейсе купить или у крупного корпоративного клиента 10 лямов непойми куда пропали...
Вы, видимо, просто с графами не сталкивались. Вы можете не называть это гц и изобретать велосипед по месту (а потом долго и безуспешно отлаживать), а можете взять с полки готовый алгоритм и ничего больше не делать.
А нет, в ванильном С++ не можете (а для эффективной реализации, увы, нужна поддержка компилятором, потому что там под капотом чёрная магия над старшими битами указателей)
потому что там под капотом чёрная магия над старшими битами указателей
Идея со старшими битами так себе. Да, по факту сейчас практически все компьютеры 48 битные (адресуемость до 256 терабайт, типа их хватит всем), но это уже сегодня довольно серьезный косяк/ограничение.
Вот было бы ну очень прикольно иметь возможность обращаться к любой ноде в каком infiniband супер кластере с экзабайтом оперативки просто напрямую, без RDMA API
Хотя какие китайцы может быть и запилили уже подобное...
У больших машин IBM под AIX это давно. Там вся память, включая диски, имеет адрес в едином пространстве. (Ну или имела 20 лет назад, когда я последний раз слышал про AIX)
Таки да, там и правильная бухгалтерская математика для Libdfp реализована в кремнии, и вообще много прикольных вещей. Жаль только что это все в итоге будет выброшено на свалку, об обратном приходится лишь мечтать. Идиократию не победить, весь мир вон считает деньги в double и вообще не парится же (только PostgreSQL с Oracle и спасают от краха цивилизации).
Мир продолжает считать деньги на COBOL :-) А там вся эта математика бухгалтерская реализована на фиксированной точке. То, что в SQL называется decimal и numeric (отличаются способом хранения в памяти).
Там, где используется IBM i (см. выше) вместо COBOL (хотя он тоже поддерживается) используется RPG (который хоть и ровесник COBOL и начинался как "эмулятор табуляторов" с жутким позиционным - FIXED - синтаксисом и cycle mode режимом выполнения программы, но в современном диалекте является нормальным процедурным языком с легким послевкусием PL/I в синтаксисе) где нативно поддерживаются все SQL типы данных - packed соответствует decimal, zoned - numeric. Так же есть типы date, time, timestamp, char, varchar соответствующие SQL типам.
Естественно, для них поддерживается вся арифметика, включая операции с округлением. Например:
dcl-s p1 packed(15: 3); // 15 знаков, 3 после запятой
dcl-s p2 packed(15: 2); // 15 знаков, 2 после запятой
p1 = 123.345;
p2 = p1; // p2 = 123.34 - присвоение без округления
eval(h) p2 = p1; // p2 = 123.35 - присвоение с округлениемКак специализированный язык для работы с БД (как прямой доступ, так и возможность использовать embedded SQL в RPG коде) и коммерческих расчетов весьма хорош, быстр и эффективен. С одной стороны достаточно простой, с другой - все необходимое для выполнения специфических задач есть - работа с датой, временем, строками, арифметика с фиксированной точкой, перезагрузка (overload) процедур, динамические массивы (как с ручным управлением размером, так и с автоматическим. Очень гибкая идеология работы со структурами. Тот же union тут просто не нужен т.к. все это можно реализовать в описании структуры.
Более 80% кода на IBM i пишется именно на RPG.
Не только AIX. IBM i (это не mainframe, а поменьше - middleware), под которую пишу последние 6+ лет также использует "одноуровневую память" (SINGLE LEVEL модель памяти) с 128-битными указателями (там кроме собственно указателя еще много чего содержится). Хотя там есть и другая модель - TERASPACE где указатели могут быть как 128, так и 64 бит (считается что в TS модели 64-бит указатели эффективнее). При этом код, написанный в TS (например, "сервисная программа" - это что-то типа динамической библиотеки, DLL в винде) может вызываться из кода, написанного в SL (но на внешних интерфейсах, если аргумент является указателем, надо добавлять спецификатор _ptr128 для совместимости с SL).
Впрочем, TS модель здесь используется не слишком часто. Там, где требуется динамическое выделение больших объемов памяти одним куском (ограничение тут 2Гб, тогда как в SL ограничение 16Мб). Мне за все время потребовалось всего один раз такое. А так - работа в SL модели и никогда не знаешь где именно выделилась память - на диске или в оперативке.
Это не вопрос готовности, знаний или уровня интеллекта, это вопрос того, что все люди совершают ошибки. Нет никакого порога, пройдя который вы волшебным образом станете писать код без багов. И те инструменты, которые сейчас предлагают, решают именно эту проблему - мы не можете исправить людей, не можем сделать из них неошибающихся роботов, но можем дать людям такие тулы, которые технически уменьшают вероятность ошибки.
Во-первых давайте будем откровенными, очень малая группа людей, даже среди программистов, ставит безопасность кода на первое место. Конечно это проблема для тех кто озабочен госбезопасностью или безопасностью корпораций и это довольно важные шишки, но это никогда не будет на первом месте для большинства людей. Всё же на первом месте у нас обычно другие критерии. Тем более если речь идёт о прикладном ПО. Что, нам так важна безопасность какой-нибудь игрушки типа пасьянса? Дыра в безопасности какого-нибудь текстового редактора будет неприятна, но по большому счёту наплевать. Ведь правда? Язык с++ это язык общего назначения, соответственно и безопасность у него находится на том же месте, что и у большинства людей. Это логично и правильно.
Во-вторых есть действительно критичный код, от которого мы ожидаем повышенного уровня безопасности, типа sudo или passwd. Именно этот код следует писать с учётом повышенной безопасности и возможно там нужны специальные языки или специальные подходы в имеющихся языках. Но переписывать всё на безопасных языках? По-моему это идиотизм.
Вообще мне кажется, что многие на Rust уходят не из за безопасности, а просто потому что на нём удобнее писать при том, что результат выходит сравнимым с плюсами
что результат выходит сравнимым с плюсами
Java программисты говорят точно так-же. Даже утверждают, что из Java может быть и быстрее чем C++, и они лично на каких-то блогах про это читали.
Про быстрее на примерах с массивами, без GC - таки вполне может быть в отдельных случаях, особенно если сравнивать с march=x86-64 (generic) и забыть про профилирование и всякие SIMD.
Даже утверждают, что из Java может быть и быстрее чем C++
В теории может, если на С++ собирать под любой процессор. Но пока нет достаточно хорошего и достаточно быстрого компилятора из байт кода в машинный (под конкретный процессор). Тупо не хватает времени использовать все оптимизации. Так я слышал.
Java не сравнима по результатам хотя бы по тому, что там есть рантайм. Rust же может как и Си собираться под совсем голое железо.
Даже утверждают, что из Java может быть и быстрее чем C++, и они лично на каких-то блогах про это читали.
Не так. Если написать две программы написать на нормальном С++ и на нормальной Джаве с уклоном в читаемость и поддерживаемость кода, то Джава и победить в каких-то случаях может. Рантайм оптимизация это на самом деле сила.
А вот если постараться выжать максимум производительности жертвуя всем, то С++ побеждает без вариантов. В Джаве просто нет механизмов для такого выжимания производительности.
Разнообразные GraalVM это не изменят. Они могут как-то ускорить или замедлить Джава программы, но человек упоровшись в оптимизацию все равно сейчас делает это лучше. А механизмов для такого упарывания Джава все еще не дает.
В Джаве просто нет механизмов для такого выжимания производительности.
Не факт, что компилятор переводит на ассемблер хуже человека. Уже сейчас программы на фортране часто работают быстрее программ на ассемблере. В теории, очень умному компилятору всё равно с какого языка компилировать. Осталось только дождаться, когда компиляторы станут достаточно умными.
Rust по производительности намного ближе к плюсам, чем к джаве. Если взять плюсы за единицу, то Раст будет, условно, в два раза медленнее, а Джава, условно, -- в пятьдесят.
и наверняка у вас есть какой-нибудь приличный тест про 50 раз?
Нету. Пусть будет вместо Джавы Пайтон, суть моего комментария не в этом. Раст -- это разумный компромисс между скоростью и удобством (при условии, что человек в состоянии на нем писать).
Да, плюсы быстрее (а си еще быстрее), да, Пайтон проще, но Раст -- это возможность получить удобство, соизмеримое с Пайтоном и скорость, приближающуюся к плюсам.
Если кому-то удобно на расте или на питоне, пусть конечно пишут на там что им больше подходит. Пусть расцветают все цветы. Статья не об этом.
Есть где-нибудь ликбез по небезопастьсть C++ и безопасность Rust/Java/C#/... ?
Это не понятно потому, что современные средства C++ позволяют вообще не работать с паматью вручную.
Пожалуй, в каждом первом учебнике по Rust его преимущества описываются через недостатки C++. В Java//C# GC и сложность доступа к указателям закрывают все вопросики.
С передачей владения умными указателями и мутабельным алиасингом можно смело продолжать косячить.
Сделайте дабл линкет лист на С++. Подумайте где при этом можно ошибиться и получить лик памяти или dangling pointer.
Делается одной строчкой со 100% надежностью:
std::list<int> doubleLinkedList;
Там в одном только векторе 20 лет развития и хитростей с strong exception guarantee, это только на поверхности выглядит, что создать дефолтный контейнер это же так просто.
Ну и класическое нинужон, если в коробке есть, а написать лучше это очень-очень много работы.
Фейсбук писал свою строку, лучше стандартной не получилось (получилось примерно тоже самое), а ведь Александреску совсем не дурак.
речь не об этом, а том, что человек не понимает какие могут быть сложности и задачи про работе с памятью в С++. Написание собственных контейнеров для графа это хорошее упражнение, чтобы разобраться в подобном вопросе.
Да, не понимаю. Для большинства задач стандартной библиотеки более чем достаточно. Получить проблемы с паматью используя стандарнтную библиотеку - тест на профпригодность.
Агрумент про собственный контейнер не актуален, такие задачи в типовой разработке не встречваются.
Ой да ладно вам, в плюсах начиная с определённого количества KLoC получить протухший указатель становится проще, чем непротухший. Достали сырой указатель, передали вниз по стеку (потому что там внизу либы, которые с сырыми указателями работают), оно там где-то куда-то сохранилось чтобы полезть позже, а потом когда полезло - по этим адресам уже совсем другие объекты. Нуивот.
Он забыл сказать самое важное. Весь api, во всех системах, во всем мире на C. На C++ никогда его не будет, потому что плюсы, бинарно никак не стандартизированы и не будут. И всегда в плюсах будет код си, и всегда будут сырые указатели на строки на все остальное. И никак это не обернуть в плюсах и ни как это спрятать и не запретить. И никак не не могут завести модули. Плюсы тако1 современный язык, и как он сильно изменился, ха, но как и си, это портянка хедеров, где важен порядок, и макросы, которые легко могут все поломать.
На C++ никогда его не будет, потому что плюсы, бинарно никак не стандартизированы и не будут
Как и C, который никогда не определял никакой abi. Это всё уровень платформы, ОС и конкретного компилятора.
И никак это не обернуть в плюсах и ни как это спрятать и не запретить.
Я бы не был таким оптимистичным. Маразм и деградация дошла до того, что скоро все API могут стать текстовыми с упаковкой данных в JSON.
никак не не могут завести модули.
Какие такие модули? Скрипач не нужен.
И никак не не могут завести модули.М
Модули в С++ уже есть, и CMake их поддерживает (уже год как). И работают весьма неплохо.
Они правда довольно хреново совместимы с STL, но это как раз еще один повод чтоб задуматься о ее аннигиляции.
Все равно Его Величество Ассемблер и мастерство его пользователя в конечном итоге определяет безопасность кода. А все уязвимости это следствие ошибок пользователей Ассемблера, создающих компиляторы или просто банальные закладки или ошибки разработчиков процессорных чипов.
Проблема в том, что у С/С++ самая лучшая инструментальная инфраструктура (бэкэнд, оптимизирующий компилятор, LTO, DCD, LLVM и вот это вот все). Все остальные находятся на уровне если не детсада, то строительного техникума и курят в сторонке. Альтернативы ей нет и не предвидится.
Но фронтэнд, который для человеков, он не просто эстетически ужасен, он какой-то просто человеконенавистнечиский. Простые вещи делаются до предела странными, сложными и многословными конструкциями, это никак не способствует чтению и верификации кода. И делается почти всегда не как у всех, что особенно печально.
Про то, что изначально все базовые примитивы принципиально сделаны не так как у Swift, Kotlin, Java и пр. наследников С++ это понятно (типа кто там первый был и мог подумать как на самом деле надо было), но что мешало уже сделать потом нормально? Зачем тянуть в века это замшелое и посредственное говно мамонта под названием библиотека SGI STL, зачем-то называя ее стандартом? Она даже хешмапы делает плохо, есть более быстрые и удобные. И почему именно эту библиотеку в стандарты двинули, почему нельзя взять любую другую, которая хотя бы строки и контейнеры будет делать в стиле Java (к примеру), и в camelStyle нотации имен? Сколько можно этими подчеркиваниями мучаться?
100500 способов 32 битное целое называть - это вообще зачем? Почему нельзя один раз всем сказать, что со следующего стандарта int это всегда знаковое 32 битное целое и успокойтесь там уже со своим PDP-11, сидите в своем музее на на старом стандарте, вас никто не трогает.
И кому реально так сильно впилась эта обратная совместимость, все равно же без флагов --std= в реальной жизни не обойтись? Хочется писать в духе С++98, ну и отлично - вот вам песочница и отдельные .deb/.rpm со "стандартными" библиотеками, не плачьте.
А вот небезопасные штуки доступа к памяти можно было вполне запретить по дефолту, в равной степени как и принудительную верификацию диапазонов и прочих выходов за границ обязать делать - это все вполне можно было через опцию флажками компилятора привинтить, да и стандартную библиотеку давно пора переписать с нуля, начиная с спецификаций интерфейсов, тут никакой Америки нет. Кому прям очень надо там для какого CRC32 алгоритма - старый стандарт или unsafe флаги в помощь.
Но мир видимо решил проявить упорство в своем безумии и все надежды возложить на весьма странных парней из Rust (как минимум странных своими чумовыми названиями - все эти трейты, крейты, опять не похожий на всех синтаксис), дескать они уж точно знают как надо. Наивность веры в Rust просто невероятно поражает, учитывая, что им пока не удалось ничего более внятного, чем несколько относительно неплохих библиотек для веб микросервисов написать и сильно ограниченно их популяризовать (и то, даже на C++ есть библиотеки и побыстрее, и в целом покруче).
Альтернатива где? Не на Swift же переходить? Хотя поневоле задумаешься, они там уже и на UTF-8 догадались переползти, и даже начали макросы применять, не пройдет и 30 лет как совсем взрослыми станут.
Если проекты типа https://github.com/cloudflare/pingora - "относительно неплохо", то что в вашем понимании "круто" тогда?
Так есть же известный биорекатор для писькомерства.
https://www.techempower.com/benchmarks/
Туда кстати периодически весьма прикольно заглядывать. По разным закладкам вон меряются и длиной, и скоростью, и пропускной способностью, джедайские техники иногда всякие разные показывают, забавные (вроде half closed connection... или это в Go изначально придумали), или реализации NETMAP/UDP (и даже собственных TCP) в userspace, без похода в ядро через эти ваши дурацкие sockets API... обчитаться до заикания, и потом обратно в родной jetty/httpd/nginx/haproxy
Но надо отдать должное - чуваки на Rust ну прям сильно сильно стараются, прям как в последнюю битву еще один раз, уж очень хочется прославиться как самый самый... перспективно небесполезный язык?
Пока не приходят ребята с каким H2O и libreaсtor c С (иногда и с С++ какой lithium) наперевес и не сбрасывают их с первых мест. И так до следующей итерации.
Про пингору писать не буду. Да, молодцы, добрались до 7 класса школы. Как в техникум пойдут (и что-то скажут чего на тему Raft), можно будет еще раз на них посмотреть.
Непонятно, почему Расту надо быть быстрее С++, чтобы быть лучше? Там достаточно преимуществ при сравнимой скорости. Пусть даже Раст будет в три раза медленнее плюсов -- он все равно в десятки раз быстрее джавы или пайтона.
А если не более быстр, то зачем он вообще тогда нужен?
По безопасности там нет никаких преимуществ, на самом-то деле. Да, Modern C++ ужасен и неюзабелен, PreModern C++ тоже. Это надо кому-нибудь исправить, но все сильно боятся дедушку Страустрапа и его права вето, при его тупиковой и противоестественной философии (хранить старые ошибки любой ценой, вместо эволюционного выпалывания оных с заменой общепринятыми удачными подходами).
Но и Rust продает, извините, старые гнилые помидоры в виде детской пропаганды. Да, они якобы решают определенные классы потенциальных проблем через принудительное накладывание дополнительных ограничений на разработчика.
Но далеко не все проблемы решаются, далеко не самым оптимальным образом (ownerships, reference counting - это скорее благоглупость от отчаяния непонимания memory models and lifecycles, остальное аналогично). Кому-то эта невеселая принудиловка в виде старых песен о главном нравится, мне лично - нет.
Хотя больше не нравится просто синтаксис Rust. Я бы лично предпочел доразвитый исправленный C with Objects (там не много надо поправить), сохраняющий разумную преемственность к C в части читабельности кода.
Даже вот в таких мелочах как i8, i16, i32, i64, i128 - почему нельзя было просто оставить byte, short, int, long, wide ?
mod my { почему mod, а не module? там что, надо 100500 раз это слово в файле писать?
let mut блин, почему нельзя просто var было вместо и так далее и т.п. зачем вообще с этим mutable постоянно носиться?
Да, многое наболевшее они решили (писать тип справа от имени переменной - мое почтение, ура, не прошло и 50 лет). А точки с запятой оставили (кринж). И std:: оставили, кринж в кубе.
Макросы - это просто издевательство. Ладно макросы в C/C++ куцые недоделки, но что, парням из Mozilla никто M4 так и не показал?
Т.е. он просто НЕДОпродуман, недоделан, также как и С++ излишне болтив и тем самым тоже уродлив. Если это все двигается прям как вот светлое будущее программирования, то это скорее печальный факт, там два шага вперед и тридцать прыжков на месте, три шага обратно.
Уважаемые товарищи минусующие. На ваш любимый Rust нападают и вам очень это не нравится? Так Rust изначально нападает на C/C++ и пытается его вытеснить, нам это тоже не нравится. Есть что возразить - так говорите, не стесняйтесь.
А молча ставить минусы это уровень детского садика.
Если сократить - то вы сказали что все херово, все херня, все дураки а ты один умный. За такое вы получите еще не один минус, не нужно обижаться на это и обращать внимание.
Я говорил не это. Я говорил что С++ можно и нужно исправить через развитие. Но текущий комитет это блокирует (даже такие банальные штуки вроде перегрузки оператора точка, get/set properties и прочие мелочи) просто потому что у Страустрапа странный бзик об обратной совместимости. И странные представления о нужности-ненужности.
А делать совсем отдельный язык просто для того, чтоб выполоть оператор стрелка -> или заменить auto на var и получить нормальную сегрегацию доступа через интерфейсы без vtable, через get/set свойства, вместо этого вашего Кармаковского const nazi подхода?
И получить по дефолту нормальный String (который string_view), а не этот странный мегакомбайн с реверансом в древний мегакосяк с zero teminated С-style strings. Почему нельзя просто оставить компилятор как есть, немного дополнить его и заново реализовать стандартную библиотеку, взяв некое общепринятое общее от Swift/Javascript/Java/etc? Зачем вместо этого Rust продвигать в массы?
Но вот что еще больше не нравится - так это пропаганда революции через грядущий Rust everywere. Все надо переписать заново, все исправить. Это уже проходили один раз с Java. Потом с C#. Потом с Javascript. Не надоело еще?
А сейчас вот делаешь при включенном epel
sudo dnf list|grep rust
и невольно задаешься вопросом - а кто все эти люди, что они точно знают что они там делают? yansi? serde? uzers? tungstenite? это вообще на каком языке термины?
rust-yansi-term+derive_serde_style-devel.noarch
rust-winnow+unstable-recover-devel.noarch
rust-v_htmlescape+buf-min-devel.noarch
rust-v_htmlescape+bytes-buf-devel.noarch
rust-v_htmlescape+default-devel.noarch
rust-uzers+mock-devel.noarchP.S. tungstenite - Дисульфид вольфрама. Ну отлично, перлит, феррит, аустенит, цементит, еще куча же чумовых названий существует по теме, кафедра материаловедния ликует.
Насчет C++, то если сделать то о чем говорите вы - то он им перестанет быть. И на совместимости он держится не в последнюю очередь. Но и пользователей у него сильно больше чем десяток человек, так что комитет вполне резонно занимается тем чем и должен.
Ну, тут да. Согласен. Если выбросить из C++ его ценнейшую прелесть по имени STL, то это уже можно будет назвать каким The A Language - тем самым C with Objects (C который получился из неудачного B, который и должен был быть изначально, идем обратно по буквам).
Если говорить что комитет просто обязан лишь тащить на себе все мегатонны легаси, то ок. Но мне кажется это в перспективе довольно бредовая идея.
Во-первых через обратную несовместимость уже проходили и не раз (скомпилировать gcc какой С код из 80-х точно не получится).
Переход с С++98 на C++23 тоже в реальности невозможен. Только на одном алиасинге можно очень крупно погореть, а обложить прям все тестами - задача в массе труднодостижимая. Про реальную совместимость msvc, gcc и clang и вовсе говорить не приходится, #ifdef наше все.
Но все равно не понятно, почему нельзя get/set свойства сделать. И уж тем более не понятно, зачем вместо var для выведения типа auto притянули. И обратно несовместимо (уже тут сами себе тотально и эпически противоречат), и смешно же получилось, опять не как у всех.
Но все равно не понятно, почему нельзя get/set свойства сделать
Borland в C++ Builder пытался - у них в классе было такое понятие как __property Очень удобная штука на самом деле. С возможностью определения RO/WO/RW.
Да они и в clang и в msvc тоже есть, __declspec(property) через ms-extensions. Работают кстати очень хорошо, хотя разрдражает видеть в auto-complete для VS Code и свойства и get/set функции одновременно (их заставляют public делать).
Ну и GCC гордый весь такой и их не приемлет.
Вот только это нестандартные расширения, а да заголовочная декларация пропертей в этом расширенно-нестандартном C++ не менее уродлива, чем весь Windows.h.
Можно конечно привыкнуть, но глазам все равно больно, даже если через макросы окультурить.
древний мегакосяк с zero teminated С-style strings
Да, это боль. Еще в паскале придумали нормальные строки (хоть и с ограничением длины), которые потом развили до varchar в том же С представляемый как
typedef struct t_VarChar {
unsigned short uLen;
char Data[...];
};или varchar4
tydef struct t_VarChar4 {
unsigned uLen;
char Data[...];
};работать с которыми и быстрее и проще.
работать с которыми и быстрее и проще.
Интересный код конечно выше. Строки в 64к это ок, но так мало кто уже извращается.
Вообще в когорте правильных парней больше принята пара { *ptr, size_t size }, где лишние нолики в хвосте можно и отбросить или да, и вовсе всегда привести к { *ptr, int(short) size}
https://github.com/fredrikwidlund/libreactor/blob/master/src/reactor/data.h
https://faxpp.sourceforge.net/structFAXPP__Text.html
https://github.com/google/gumbo-parser/blob/master/src/gumbo.h#L88
Это кстати можно и как критерий выбора грамотных фундаментальных библиотек представить.
Если автор библиотеки на старте догадался заменить ASCIIZ строки на нормальные пары указатель+размер, то у него уже явно просветвленное zero-copy сознание в голове (а не мешанина из какой унаследованной и/или бездумно зазубренной из букварей благостной ASCIIZ чуши), и с ним можно иметь дело. Жаль только что их очень мало таких.
А вот чудаки из C++ комитета как всегда отожгли напалмом и сделали через .... в общем все как всегда обычно:
https://github.com/gcc-mirror/gcc/blob/master/libstdc%2B%2B-v3/include/std/string_view#L583
И это лишь одна из причин, по которой с ними дела иметь не хочется от слова вообще, уж сильно у них большой мозг.
Вот еще один, который не очень умеет в безопасный и надежный код:
https://github.com/LMDB/lmdb/blob/mdb.master/libraries/liblmdb/lmdb.h#L286
и надо отдать должное, производный и доведенный до ума проект LMDB -> MDBX исправил и представление строки сразу
https://github.com/erthink/libmdbx/blob/master/mdbx.h#L752
Забавно, забавно. Никогда и не задумывался до этого, что даже по такому признаку, как пишут - {data, size} или {size, data} можно сразу отделять тех, с кому тебе скорее всего точно не по пути.
Можно сказать дискуссии прошли не зря, потраченное время уже окупилось.
Вообще в когорте правильных парней больше принята пара { *ptr, size_t size }, где лишние нолики в хвосте можно и отбросить или да, и вовсе всегда привести к { *ptr, int(short) size}
А вот вопрос - вы в качестве аргумента получили указатель на такую вот структуру. И как вам догадаться по какому смещению от полученного указателя находится реальный размер?
Вот у нас в языке есть именно такой varchar как я написал выше. И он совпадает с типом VARCHAR в БД (DB2 если что).
И я могу (отдельная тема как - это уже системное) написать кусок кода на С, прицепить его к основному коду на нашем языке и вызывать функцию на С из кода на нашем языке. Вглядит это примерно так:
typedef _Packed struct tagVarChar {
unsigned short int uLen;
unsigned char Data[];
};
typedef tagVarChar* PVarChar;
extern "C" void VCharCommHash(PVarChar pData, char strHash[8])Это С-ишная часть (дальше там уже собственно реализация)
Чтобы это вызывалось из нашего языка достаточно в коде правильно описать прототип функции
dcl-pr getAddressHash extproc(*CWIDEN : 'VCharCommHash');
Address varchar(512) options(*varsize); // Строка с адресом
Hash char(8); // Коммутативный по элементам хэш адреса
end-pr;И все. Причем, передавать туда я могу любой varchar, не обязательно 512, можно 256 или 1024 - на это указывает модификатор options(*varsize), который предполагает что тип будет varchar, а вот реальный его размер может быть любым.
А на С-шной стороне я всегда буду знать фактическую длину строки по полю pData->uLen. И если оно объявлено как varchar(512) (т.е. под строку выделено 512 символов), но реально там всего 50, то uLen будет равно 50-ти.
Или туда передано varchar(128) внутри которого строка длиной 30 символов - ничего не поменяется. uLen будет 30 и всего.
Как в вашем случае в такой ситуации определить длину строки?
По-моему, тут проблем еще больше чем с null-terminated строками...
Как в вашем случае в такой ситуации определить длину строки?
Вопрос не понятен. В моем примере выше строка описывается просто двумя 64х битными числами - указатель и длина, соответственно.
И от того, как располагать - ptr*, size или site, ptr* мало что меняется, это и так и так 16 байтовая структура.
Да, я ошибся. Вы правы.
Но в таком случае возникает вторая проблема - для создания контейнера вам придется создавать два объекта в памяти - собственно строку и контейнер, ее описывающий. И потом следить за целостностью связи между ними? Чтобы не случилось ситуации, когда строка уже удалена из памяти, а контейнер ее описывающий еще нет.
И ради чего? Только ради легкого кастинга к указателю на данные?
И потом следить за целостностью связи между ними?
Я там выше вроде говорил про это. Что данные для строк - это как правило или замапленный в память файл, или буфер обмена от сетевого I/O, или какой даже какой другой строковый буфер. И у этих всех источников там свой жизненный цикл, к отдельной строке ссылке на свой фрагмент имеющий перпендикулярное отношение.
Строка из пары указатель+размер это просто способ уйти от always-make-a-copy-with-trailing-zero к подходу zero-copy, когда никакие данные никуда не копируются, а строки (которые к примеру парсер понавыдает) просто ссылаются на исходные данные. Т.е. следить особо и не надо за целостностью, раз исходные данные не меняются.
Ну а если и надо следить, то в чем вопрос? Можно как угодно извратиться, да хоть счетчик ссылок донавернуть, RAII какой на ownership этого куска памяти, но ИМХО это ошибочный путь (хоть и используемый сейчас в 99.9% случаев). Не строками нужно мыслить, а более крупными понятиями, источниками и назначениями потока данных в целом, когда строки это лишь способ ссылаться на их фрагменты.
А вот про случай контатенации строк, т.е. строковый буфер (в т.ч. временный, на стеке) - это вообще отдельно.
Я там выше вроде говорил про это. Что данные для строк - это как правило или замапленный в память файл, или буфер обмена от сетевого I/O, или какой даже какой другой строковый буфер.
Я говорил про общий тип данных. Который используется везде вместо null-terminated string безо всяких оговорок.
Т.е. я всегда и везде могу
dcl-s str char(300);
dcl-s vstr varchar(300);
str = 'This is just a string';
vstr = str;И не надо никаких лишних сущностей в виде маппингов и т.п.
Разница в том, что для определения, скажем, длины null terminated string в С (strlen) нужно пройтись по ней считая символы пока не доберешься до завершающего '\0'.
Для определения длины vatchar нужно просто прочитать первые два байта (или 4, в зависимости от подтипа).
Строка из пары указатель+размер это просто...
...совершенно другой тип данных для совершенно других целей.
Можно как угодно извратиться
Только зачем, когда можно не извращаться там, где можно без этого обойтись? Вспомним достопочтимого старика Оккама и его "бритву".
А можете разжевать для не просветлённых, какое такое фундаментальное преимущество указатель+размер перед размер+указатель.
На мой взгляд размер впереди удобнее. Точно знаешь где лежит размер. И не размер + указатель, а структура с открытым концом - сначала размер (он всегда фиксрован), затем блок данных переменной длины. Такие вещи можно объявлять в статике:
dcl-c vChar varchar(512);будет равносильно С-шному
struct {
unsigned short uLen;
char Data[512];
} vChar;или
dcl-s vChar4 varchar(512: 4);равносильно
struct {
unsigned uLen;
char Data[512];
} vChar4;Что допускает создание статических переменных в compile time.
А вот с
struct {
char* pData;
unsigned short uLen;
} vChar;уже так не проканает - вам придется создавать блок данных динамически в рантайме и потом все это инициализировать. А потом не забыть "подмести за собой". Тут уже нужен объект с конструктором и деструктором. И динамическая работа с памятью. Все это не бесплатно (хоть и дешево).
Теоретически (у меня самого такой реализации нет, но можно и запилить потом наверное), то если располагать сначала указатель, а потом длину, то можно сделать эдакое LEB кодирование size поля, исходя из Little Endian формата хранения числа. Т.е. если там до 127 байт длина, то size гарантированно однобайтовый, если менее 32767 - двубайтовый, ну и так далее. Т.е. не всегда иметь структуру из 16 байт, а иметь структуру переменной длины (9, 10, 12, ... , 16 байт).
В теории, если у тебя миллиарды строк - то это может дать некий выигрыш по памяти.
Но вообще там пост выше был больше стебовый, чем про реальные какие-то бенефиты от порядка расположения полей.
Ну или в LEB формате в чистом виде: https://en.wikipedia.org/wiki/LEB128
и невольно задаешься вопросом - а кто все эти люди, что они точно знают что они там делают? yansi? serde? uzers? tungstenite? это вообще на каком языке термины?
А если погуглить хоть немного?
yansi - A dead simple ANSI terminal color painting library.
serde - библиотека для сериализации и десериализации, это вообще все знают
uzers - This is a library for getting information on Unix users and groups.
tungstenite - Lightweight, flexible WebSockets for Rust.
Все названия кроме последнего вполне понятны. Последнее тоже становится понятным после прочтения README
А если погуглить хоть немного?
И узнать, что все озвученные выше задачи давно решены базовыми системными С библиотеками. Зачем это переписывать на Rust заново? А...наверное безопасная безопасность повысится, да?
Затем, что Rust - это не тот же самый язык, что и Си, и к нему нельзя без "переходника" так просто подключить библиотеку на Си. Да и не всегда библиотека для одного языка так уж хорошо подойдёт для другого: часть задач, решаемых библиотекой в одном из языков, может просто не иметь смысла в другом.
В общем, даже если притвориться что в Си и правда есть аналог serde - наличие такой же библиотеки для другого языка всегда оправдано. Каждому языку свои библиотеки.
Затем, что Rust - это не тот же самый язык, что и Си,
Хорошо, для непонимающих иронию поясню отдельно.
Для нормального программиста видеть в коде любые числа и цифры, отличные от нуля - это ну прям кринж кринжовый. Потому как это цифровое все должно быть вынесено в заголовки, и немедленно заменено символьными именами констант. INT_MAX, N, M и вот это вот все, во всех букварях же про это пишут в первых главах.
Открываем любой код на Rust - и он прям густо густо обвешан ну очень ценными цифрами 8, 32, 64, которые:
а) никакой полезной и нужной информации (как цифры) на самом деле не несут
б) рябят и раздражают, потому что цифры в коде и должны раздражать настолько, чтоб немедленно их заменять на N, M и прочие DEFAULT_POOL_SIZE
Догадаться, что выжить может и должен только LP64 (а все остальное должно отмереть как и BigEndian какой вместе c VAXами), не, мы не такие, а мы лучше свой новый еще один "стандарт" именования запилим, в дополнение к чудным int32, int32_t, __int32, _int32, ____int32, __int32_t, std::int32_t, POCO::Int32, __INT32_TYPE__, int_fast32_t, int_least32_t, signed, int_t, __int32t, __Int32T, Int32T, INT32, i32_t, int32
Ну мы же тоже любим все называть не как у всех. Если чувакам на C/С++ так весело упарываться с алиасами к int можно, то а мы чем хуже, да? Как же вы все без i32 жили до этого, получите распишитесь.
Ну молодцы, таки решили проблему раз и навсегда.
Что за бред вы тут пишете. То есть, если я пишу класс работы с матрицами, мне вместо ясного и понятного Matrix4x4 надо выдумывать MatrixFourByFour, так? А то цифры что-то рябят.
Что за бред вы тут пишете. То есть, если я пишу класс работы с матрицами, мне вместо ясного и понятного
Matrix4x4
Матрица 4 на 4? Это лабораторная работа 2 семестра наверное, а студентам не рассказали про BLAS/LAPACK и т.п.?
И да, применение матриц имеет некую предметную область со своей терминологией... впрочем, начни сейчас расспрашивать про реальное применение - так опять молча минусов понаставят и уйдут с гордой сатисфакцией, так и не выяснив, кто-же бред на самом деле пишет :)
Какое вообще отношение ваш комментарий имеет к моему? Вы точно на наго отвечали?
Для нормального программиста видеть в коде любые числа и цифры, отличные от нуля - это ну прям кринж кринжовый.
У этого же есть причина, если что, чтобы менять в одном месте и где-то случайно не забыть. Разве такая задача стоит для типов данных? (Если стоит -- всегда можно сделать алиас типа).
Открываем любой код на Rust - и он прям густо густо обвешан ну очень ценными цифрами 8, 32, 64, которые:
а) никакой полезной и нужной информации (как цифры) на самом деле не несут
Чем это принципиально отличается от int/ long / short ?
Руку надо переносить на цифровую клавиатуру, хотя честно я понятие не имею как я набираю эти типы - т.е. это вообще не важно. Ну ещё конкретно у этого человека аллергия на цифры, глаза начинают чесаться при чтении, ну бывает, у меня вот аллергия на скобки, у вас ещё на что нибудь - это нормально хотя вероятно не лечится.
После «Даже вот в таких мелочах как i8, i16, i32, i64, i128 - почему нельзя было просто оставить byte, short, int, long, wide ?» дальше можно не читать, всё и так ясно — вы просто не с той ноги встали, вот и бурчите.
Касательно вышеупомянутого примера — парни из Rust молодцы и сделали всё правильно: понятно, предсказуемо, логично и расширяемо. Завтра возникнет необходимость в 256-, 512-, 1024-х битных переменных и вы будете выдумывать очередные superwide, duperlongest, absurdlylongwide и иже с ними, тогда как в Rust уже всё продумали за вас.
После «Даже вот в таких мелочах как i8, i16, i32, i64, i128 - почему нельзя было просто оставить byte, short, int, long, wide ?» дальше можно не читать, всё и так ясно — вы просто не с той ноги встали, вот и бурчите.
При чем тут ноги? Это банальный вопрос читаемости кода.
int есть в C#, Java, C, C++, Vala, Scala, даже прости господи в Nemerle он есть.
Но парни из Rust тим они не такие, им int глаза мозолил настолько больно, что они решили теперь i32 называть. Блин, а почему 32? почему не i4? Завтра байты станут 1024 битные, и дальше что?
Завтра возникнет необходимость в 256-, 512-, 1024-х битных переменных
1024 битный указатель? Да. С нетерпением ждем пришествия этого чуда.
1024 битный указатель? Да. С нетерпением ждем пришествия этого чуда.
128-битные уже есть. Правда, там кроме указателя еще много чего (т.к. это существует в одноуровневой модели памяти).
А ежели поставить своей задачей туда же еще и operational descriptor впихнуть, который описывает то, на что этот указатель указывает, то и 1024 бит может не хватить...
OpDesc на самом деле удобная штука... Вот передали тебе указатель - всегда можно посмотреть, а что там за ним спрятано? А какого оно типа? А какого оно размера? Опять же, с точки зрения обсуждаемой тут безопасности...
int глаза мозолил настолько больно, что они решили теперь i32 называть
Вы считаете, что Rust - это такой наследник C#, Java, C, C++, Vala, Scala, даже прости господи в Nemerle? Это ведь не int стали называть i32, а тридцатидвухбитное целое со знаком стали называть i32, что совершенно логично и не должно по идее вызывать вопросов.
Блин, а почему 32?
Потому что 32 бита.
почему не i4?
Потому что 32 бита, а не байта.
Завтра байты станут 1024 битные, и дальше что?
Ничего? 32-битное целое останется таковым, и задача языка будет обеспечить существование такого типа на машине с 1024-битными байтами.
Это ведь не int стали называть i32, а тридцатидвухбитное целое со знаком стали называть i32, что совершенно логично и не должно по идее вызывать вопросов.
Ок, задам вопрос проще. Почему во всех нормальных языках 32 битное знаковое целое уже много лет как называется просто int, и для чего в Rust его внезапно назвали иначе?
Что бы что случилось? Чтобы безопасность повысилась?
Почему во всех нормальных языках
Какой критерий нормальности? Привычность анониму из интернета?
32 битное знаковое целое уже много лет как называется просто int
Прямо даже интересно стало, сколько языков, у которых в спеке написано, что sizeof(int) равен 4? В случае С и C++ int на многих не самых экзотических платформах 16 бит.
для чего в Rust его внезапно назвали иначе?
Чтобы было удобно видеть диапазон значений типа прямо из названия. Какой диапазон у int? У long? У cardinal? У tinyint, smallint, cent? Это всё названия целочисленных типов в разных языках.
Загляните в табличку: https://en.wikipedia.org/wiki/Integer_(computer_science)#Common_integral_data_types. У какого языка сразу ясна битность типа из названия? Если использовать в C/C++ типы int32_t и остальные этого семейства, то будет почти так же хорошо, как в Расте.
Какой критерий нормальности? Привычность анониму из интернета?
Очень простой - общепринятость. Vast majority. Если у всех по два уха и один нос, а у кого-то ушей четыре и три носа - то он точно не нормальный.
Прямо даже интересно стало, сколько языков, у которых в спеке написано, что sizeof(int) равен 4?
Давай проще, у кого написано, что он не 4?
PDP-11, MS-DOS, Win16 у кого еще? Ну ок, википедия говорит была какая-то Classic UNICOS, у нее int был на 64 бита. И только из-за MS-DOS и UNICOS мы должны все думать, что бывает в мире не 32-битный int? Серьезно?
типы int32_t и остальные этого семейства, то будет почти так же хорошо, как в Расте.
Я уже написал выше, почему цифры в коде это крайне плохо. И в С++ и в Rust с этим очень и очень плохо, но в C++ не так безнадежно, std::int32_t есть конечно любители, но в массе люди просто живут с int
А вот с long конечно сложнее. Из актуальных платформ только Win64 его считает всегда 32-битным, что клинический случай конечно.
Под xNIX уже сегодня можно просто писать long, он практически всегда 64 битный. 32 битные архитектуры практически вымерли, за исключением контроллеров, но там пишут на С, не на С++.
А писать long long - это и просто некрасиво, и просто нелепо. Как и int64_t
В конце концов в проекте можно сделать static_assert(sizeof(long)==64) и на этом и закончить.
А страдальцам из ILP32 мира просто прописать #define long long long
Дефайнить ключевые слова запрещено - не скомпилируется. С младшей школы в букварях учат 8 меньше 16 ровно в 2 раза, ну и далее по списку, а вот байт, ворд, дабл ворд, квадрипл ворд которые изначально и были заменили на шорт инт лонг от слабоумия. Зачем нормальным ЛЮДЯМ иметь в голове мапу слова на число и постоянно заниматься приседаниями что бы понимать что больше и что меньше и во сколько раз? Для этого есть числа, они лучше с этим справляются. СайзТ (как и в расте) это именно размер регистра во всех нормальных языках, а если вам байты (их количество) важно - ну например протокол реализовать, то там в 100500 раз лучше иметь и32 и т.д. вместо непонятного инта. Сразу видно, что вы дальше своей платформы ничего не знаете и крос платформ для вас это ругательства. Что написать в коде что бы не усложнять себе жизнь макросами и гарантировано иметь 64 бита везде?
Я не в курсе кто там у вас эталон правильности, но инженеров интела тоже в проф непригодных запишете с их у64, у128, у256, у512 для симд регистров?
Дефайнить ключевые слова запрещено - не скомпилируется.
Дефайнить можно что угодно - все скомпилируется. Незнание матчасти не простительно.
ворд, дабл ворд, квадрипл ворд которые изначально и были заменили на шорт инт лонг от слабоумия.
Кек кринж. word от short отличается знаковостью и т.д. Слабоумие?
Зачем нормальным ЛЮДЯМ иметь в голове мапу слова на число и постоянно заниматься приседаниями что бы понимать что больше и что меньше и во сколько раз?
Ну зачем мне видеть на КАЖДОЙ странице кода 10-15 напоминаний о том, что в int именно 32 бита, не 31, не 33, а именно 32? Чтобы что? На кой мне вообще постоянно помнить, сколько там бит? В знаковом целом?
Сразу видно, что вы дальше своей платформы ничего не знаете и крос платформ для вас это ругательства.
И в какой такой современной платформе int это не 32 битное целое? И да, даже Windows поддержка это уже ругательство, она как минимум не проходимо не POSIX, никакими MSYS или WSL ее не исправить, остется только выбросить, и что теперь? Тратить время на поддержку любой ценой?
Что написать в коде что бы не усложнять себе жизнь макросами и гарантировано иметь 64 бита везде?
А где сейчас не 64 бита? Мобилки все 64 битные, десктоп 64 битный, серверы 64 битные.
Микроконтроллеры и wifi раутеры?
А вообще забавно конечно. Никогда не думал что даже в таком вопросе, как int vs i32 у стольких рванет тяга к обминусовыванию.
Кто бы мог подумать, что мир программистов настолько разделился на массу скрытых бухгалтеров без намека на эстетическое невосприятие крайне избыточной и бесполезной фоновой информации в коде, и всех остальных.
Даже повод задуматься о причинах такого странного явления. Наверное.
A translation unit that uses any part of the standard library is not allowed to #define or #undef names lexically identical to:
https://en.cppreference.com/w/cpp/preprocessor/replace
А где сейчас не 64 бита?
Эмбед платформы/СОКи/одноплатники на армах. Это НЕ микроконтроллеры и НЕ вайфай. Они все ещё 32 битные и будут такими ещё очень долго.
А про виндоус смешно было конечно. В общем что и требовалось удостоверить, дальше своего уютного мира вы не выходите, так зачем тогда навязываете свое видение как существенно превосходящее все альтернативы?
A translation unit that uses any part of the standard library is not allowed
И? Там написаны просто правила использования некоей стандартной библиотеки. Которая просто еще одна обычная библиотека, не сильно удачная, не самая эффективная, которую к слову никто и не заставляет использовать. Зачем вообще мне нужен этот ваш iostream, если есть stdio.h? (stdio.h тоже кстати можно не использовать, но пока не будем так круто ломать шаблоны).
А раз нам STL не нужна, то просто берем вот такой код.
#include <stdio.h>
#define enum enum class
#define long long long
enum Color {
red, green, blue
};
int main() {
long red = 12;
Color my = Color::red;
printf("%lld %d\n", red, my);
return 0;
}И задаемся вопросом - почему он скомпилируется - хоть clang, хоть g++, хоть чем.
И вообще, чуваки из комитета ISO, они кто? Продавцы и популяризаторы еще одной не сильно удобной библиотеки? А если я вообще не хочу ее использовать, то что теперь?
Лично мне слово std:: вообще ничего не говорит, это не часть языка, это просто еще одна библиотека, которую пытаются продавать вместе с языком как якобы неотъемлемую его часть (что не так), и не более того.
Можно было и не шатать трубу c STL.
Даже там все отлично работает, не смотря на пугалки с сайта
#include <iostream>
#define enum enum class
#define long long long
#define var auto
#define function auto
using namespace std;
enum Color {
red, green, blue
};
function test() {
var red = 12;
var my = Color::red;
var green = 14L;
cout << red << " " << "" << green << " " << int(my); // и кто вспомнит, что такое int(expr) ?
return red;
}
function main() -> int {
var green = test();
return green;
}так зачем тогда навязываете свое видение как существенно превосходящее все альтернативы?
Кому я что навязываю, господи? Мне просто интересно увидеть реакцию на: "А вот теперь выбрасываем псевдо-значимые требования про кроссплатформу, обратную совместимость, и про обязательность STL, и весело пилим простой, безопасный и эффективный C with Objects, таким, каким он и должен был быть изначально, и да, по возможности делаем его максимально похожим на Javascript и/или какой Swift, а почему и нет. Чисто Бьярна и ко посильнее позлить"
Разве это не очевидно?
И судя по толпам минусиющих тут - подобный проект знатно бы рванул кое кому шаблоны.
Эмбед платформы/СОКи/одноплатники на армах. Это НЕ микроконтроллеры и НЕ вайфай. Они все ещё 32 битные и будут такими ещё очень долго.
Прям таки все?
https://www.raspberrypi.com/news/raspberry-pi-os-64-bit/
И RHEL дропнул поддержку не только i386, armel, armhf никогда и не собирался поддерживать. С убунтой аналогично, только 64 бита. RISCV - только 64 бита.
Там даже больше - если попытаться какой альтернативно собранный CentOS i386 поставить, то выяснится, что огромное количество пакетов уже никто под 32 бита и не собирает, а из сорцов просто уже и не собираются, и всем на это плевать.
Мир 32 бит доживает последние годы - как только вздуются конденсаторы на старых платах, то окончательно уйдет в мир иной, это еще лет 5..6, от силы. Останется жить только на каких ФрикОС для микроконтроллеров с 16 килобайтами памяти, и то не факт.
Ох уж эти практически всегда. Мне от этих ваших «практически всегда» ни тепло, ни холодно, для меня это — «хрен знает, что там». В отличие от, которое неоднозначностей не допускает.
Ну и что не так с "практически всегда"? Практически всегда - это и есть практически всегда и везде, за исключением тех областей, где тебе лично никогда в своей жизни работать и не придется.
Микроконтроллеры и wifi раутеры, к примеру. IBM мейнфреймы и прочие i-series. Зачем пытаться постоянно учитывать многообразие этого безумного мира, если твой код и так никогда туда и не попадет? 0.5% потенциальных пользователей твоей библиотеки с 32-х или 31 битностью указателя? 0.005% потенциальных пользователей c OpenBSD?
Зачем они?
где тебе лично никогда в своей жизни работать и не придется.
Стоит ли загадывать?
Я вот никогда не мог предположить, что после 25-ти лет в разработке, мне придется работать на i-Series.
А теперь... Даже нравится и уходить куда с нее ну совсем не хочется :-)
Ну и если обернуться в историю. Начинал с DOS где short и int были по 16 бит, а long 32 бита.
Сейчас уже везде short 16 бит, int и long по 32 бита и появился 64-битный long long...
На этом фоне виндовые BYTE, WORD, DWORD и QWORD просто образец постоянства.
Сейчас уже везде short 16 бит, int и long по 32 бита и появился 64-битный long long...
Утверждение не верное. в xNIX 64 битных изначально long 64 битный и это никто никогда уже менять не будет.
32 битные xNIX это исчезающе малый рудимент, а общая мировая тенденция идет к тотальной 64-х битности.
Адресуемого пространства в 64 бит хватит для всех мыслимых в обозримой перспективе задач (современные CPU и вовсе ограничены 48/52 реально используемыми битами для указателя, больше никому еще не потребовалось).
Единственное место, где еще живет 32 битный long - это win64, но с учетом дрейфа родной компании к Webkit/Edge, WSL/Linux и пр. - я думаю в ближайшие годы там тоже произойдет унификация (в новых SDK). Хотя скорее просто Windows везде заменят на Linux или Chrome OS или Mac OS каким.
К этому уже в индустрии все готово, просто еще нет политического решения. Мир всегда тяготеет к упрощению и унификации, много разных стандартов поддерживать даже на уровне розеток и диаметров сверл очень сложно и банально слишком дорого. И если есть возможность безболезненно убрать лишние стандарты - это так или иначе будет сделано со временем, так было всегда, законы рынка они такие.
P.S. И да, static_assert(sizeof(long)==8), static_assert(sizeof(int)==4) никто не отменял.
Назовите это условиями применения, да хоть EULA.txt , никто никому ничего не обязан же.
В конце концов, даже если в какой системе нет реализации mmap(), epoll() или clone(), и никто не озадачился написать нормальные API врапперы для них, то это проблема исключительно разработчиков и владельцев этой системы, которая "отличная от Linux". Пусть напишут, и проблема кроссплатформы отвалится сама собой.
Говорить что это технически невозможно - не надо. У Microsoft получилось почти весь linux syscall() набор привести к ядру NT в реализации WSL1, могут же, когда захотят.
Адресуемого пространства в 64 бит хватит для всех мыслимых в обозримой перспективе задач (современные CPU и вовсе ограничены 48/52 реально используемыми битами для указателя, больше никому еще не потребовалось).
"640 кб хватит всем".
Кроме того, увеличение разрядности адреса может быть вызвано совсем не потребностями в памяти. Мало ли какие извращения с виртуализацией памяти вылезут.
Да и целочисленные вычисления пока существенно быстрее таковых с плавающей точкой, а очень большие числа складывать, перемножать и т.п. надо.
long по 32 бита и появился 64-битный long long...
А кое где (вышеупомянутые xNix) появился уже long по 64 бита (причем сравнительно недавно). Помнится, знатно ругались, когда перекомпилировали простую програмку, которая отказалась корректно работать только потому, что long внезапно вырос.
И еще не за горами массовые 128 бит процессоры. А тип _int128 местами уже появился, не дожидаясь таких процессоров.
32 битные архитектуры практически вымерли, за исключением контроллеров, но там пишут на С, не на С++.
И на C++ тоже.
1024 битный указатель?
С чего вы взяли, что это именно указатель должен быть? В мире полно задач, где встречаются ОГРОМНЫЕ числа и есть вполне понятное желание запихнуть их в регистр и что-то с ними посчитать (вместо того, чтобы мудохаться с длинной арифметикой). Так что не удивлюсь, если когда-нибудь и такие появятся.
А если не более быстр, то зачем он вообще тогда нужен?
Тем, что он удобнее, избавляет от целого класса ошибок (которые все еще можно сделать в unsafe, да, я знаю), имеет современные средства в языке.
Один из законов Мерфи же:
Если ошибка может быть допущена, она будет допущена.
Единственный вариант на 100% избавиться от ошибок - убрать возможность их внесения.
А с этой точки зрения C++ сейчас ничем не отличается от своего прародителя в 79-м.
Смутно подозреваю, что обитатели белого дома, под термином "безопасный", понимают.... имеют своеобычное понимание :D
Современный мир декларирует безопасность, мягкие стенки, предупреждающие знаки, комфортный воздух с запахом ванили)
Почему бы и нет?
Безопасность поедающая вычислителтные ресурсы, выполняющая бесчисленные проверки, мягко подхватывающая юзера что бы он не оступился. Толстые прослоики абстракций, черные ящики классов покрашенные розовой краской. Современные новые программисты не могут без них.
Их код будет тяжелым и раздутым но безопасным. То что на Си++ весило 60кб будет весить мегабайт на безопасных языках и работать медленнее на проценты. Некритично: ресурсы cpu давно умчались с лихвой закрывая потребности безопасного кода. Для интернета и "грязной" зоны исполнения от безопасных языков не уйти.
Равно как и не уйти от Си там где нам нужна скорость и эффективность кода. Скальпель открытой памяти и жонглирования указателями остр, опасен, и дьявольски эффективен в умелых руках. И операции скальпелем это не масс-маркет программных продуктов. Это острие алгоритмов, фокус программирования. Там не может быть никаких защит - для работы скальпелем они вредны.
Так что - это просто разные ниши) Не надо их смешивать)
в контексте темы? оперативку конечно) неидеальное использование переменных за счет того что используется не линейная модель памяти с единым пространством переменных четко оговоренного размера (как в чистом Си) ну и ресурсы цпу для обслуживания проверок и разной сопутствующей бизнес-логики.
Но это небольшие накладные расходы, в "бытовом программировании" на современных РС вы ничего не заметите.
Напомните, его компилятор, код с руста переводит в псевдо-си?
Для обслуживания проверок чего?
Напомните, его компилятор, код с руста переводит в псевдо-си?
LLVM вам достаточный "псевдо-си", или это уже слишком низкого уровня?
обычные проверки: число (адрес) в указанном (допустимом) диапазоне, число в допустимом списке и тд. Там не очень много алгоритмов проверок но все они сводятся к защите что бы вы не выпрыгнули из песочницы :)
Си не имеет никаких защит "под капотом" и это прекрасно! Обратимся к микроконтроолерам: если вам надо сложить например адрес и адрес вы это сразу делаете, без скрытого чек листа языков "безопасных". И сразу видете что в указанной ячейке памяти, и можете сразу поменять это число. Даже если память эта например в таблице irq. Это скальпель.
На рс у вас этот фокус не пройдет. Ладно, механизмы виртуализации и защиты ОС, но теперь и языки включились в ресурсоемкую гонку безопасности. Опять таки, все правильно для ряда ниш: веб, операционки и тд. Но не следует считать это безальтернативным, о чем многие забывают.
не, это конечно не низкий уровень, чтото среднее. Llvm имеет несколько жирных слоев для поддержания платформонезав симости. Частью это обертки, но частью вполне себе комбайны по переводу из одного представление в другое, а из другого в третье.
Вообще, цена якобы "универсальности" довольно высока, но это тема отдельного семинара.
Страуструп ответил на призыв Белого дома США переходить на языки с безопасностью памяти