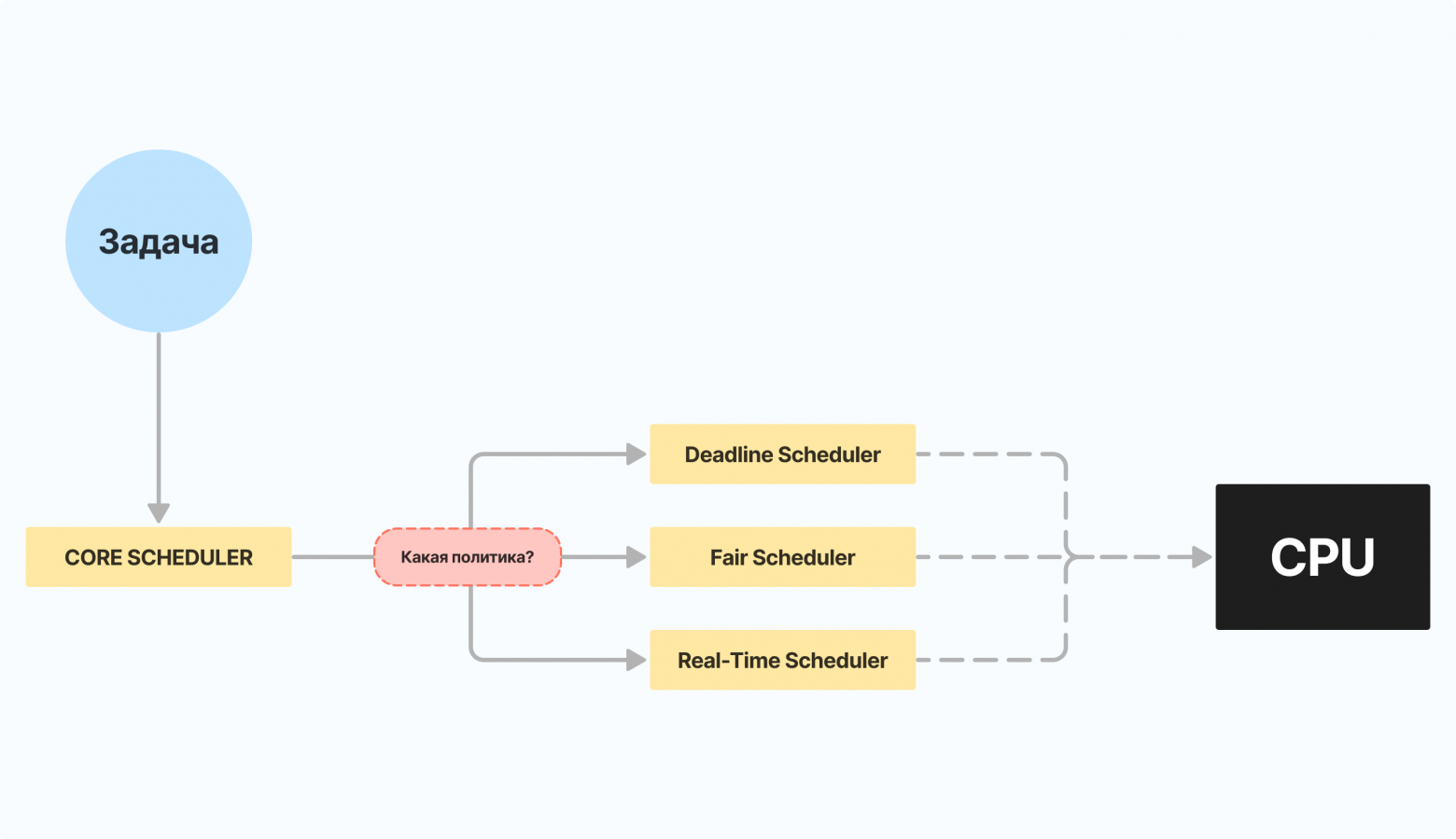
Привет, Хабр! Меня зовут Матвей Мочалов, я — компьютерный инженер и один из авторов корпоративного блога cdnnow! Мы с вами познакомились в этом посте про историю DRM для видеоконтента. Сегодня я хочу поговорить с вами про Docker, а точнее про то, о чём многие забывают: различиях в нём для разных систем. Нам, как CDN-провайдеру Docker, все его 50 оттенков близки и знакомы. И, к счастью, наше взаимодействие с ним происходит из-под Linux, но, увы, не всем так везёт.
Как это часто бывает, с мультиплатформенностью и прочими «красивыми» словами в IT, всё не так однозначно. У всего своя цена, и под капотом один и тот же инструмент на разных системах, по сути своей может представлять из себя несколько разных вещей с различными принципами работы и производительностью. А обещания революции скрывают за собой эволюцию, либо вовсе регресс и топтание на месте.