
Оглавление (на данный момент)
Часть 1. Описание, операции, применения.
Часть 2. Ценная информация в дереве и множественные операции с ней.
Часть 3. Декартово дерево по неявному ключу.
To be continued...
Тема сегодняшней лекции
В прошлый раз мы с вами познакомились — скажем прямо, очень обширно познакомились — с понятием декартового дерева и основным его функционалом. Только до сих мы с вами использовали его одним-единственным образом: как «квази-сбалансированное» дерево поиска. То есть пускай нам дан массив ключей, добавим к ним случайно сгенерированные приоритеты, и получим дерево, в котором каждый ключ можно искать, добавлять и удалять за логарифмическое время и минимум усилий. Звучит неплохо, но мало.
К счастью (или к сожалению?), реальная жизнь такими пустяковыми задачами не ограничивается. О чем сегодня и пойдет речь. Первый вопрос на повестке дня — это так называемая K-я порядковая статистика, или индекс в дереве, которая плавно подведет нас к хранению пользовательской информации в вершинах, и наконец — к бесчисленному множеству манипуляций, которые с этой информацией может потребоваться выполнять. Поехали.
Ищем индекс
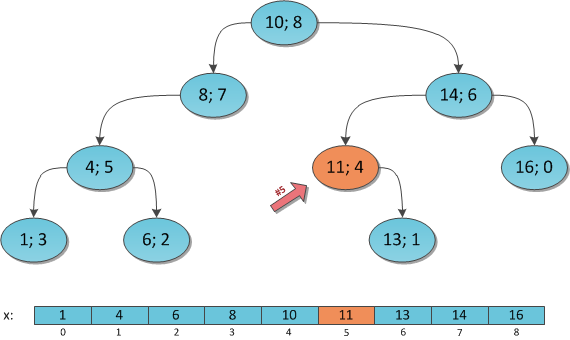
В математике, K-я порядковая статистика — это случайная величина, которая соответствует K-му по величине элементу случайной выборки из вероятностного пространства. Слишком умно. Вернемся к дереву: в каждый момент времени у нас есть декартово дерево, которое с момента его начального построения могло уже значительно измениться. От нас требуется очень быстро находить в этом дереве K-й по порядку возрастания ключ — фактически, если представить наше дерево как постоянно поддерживающийся отсортированным массив, то это просто доступ к элементу под индексом K. На первый взгляд не очень понятно, как это организовать: ключей-то у нас в дереве N, и раскиданы они по структуре как попало.
 Обнаружение пешеходов используется главным образом в исследованиях, посвященных беспилотным автомобилям. Общая цель обнаружения пешеходов — предотвращение столкновения автомобиля с человеком. На Хабре недавно был топик про «
Обнаружение пешеходов используется главным образом в исследованиях, посвященных беспилотным автомобилям. Общая цель обнаружения пешеходов — предотвращение столкновения автомобиля с человеком. На Хабре недавно был топик про « Итак, мы постепенно выходим на финишную прямую сборки Кубика Рубика 5х5х5! Осталось дособирать рёбра куба и центральные квадраты. Кроме того, есть программа-эмулятор кубика, так что даже если куба нет, можно попробовать собрать его на ПК.
Итак, мы постепенно выходим на финишную прямую сборки Кубика Рубика 5х5х5! Осталось дособирать рёбра куба и центральные квадраты. Кроме того, есть программа-эмулятор кубика, так что даже если куба нет, можно попробовать собрать его на ПК.
























