Последние полгода я активно занимаюсь разработкой сервисов на базе больших языковых моделей, они же «LLM». Для каждого проекта мне приходится подбирать модель по определенным критериям: языковая поддержка, требования к памяти, типу (instruction-based или completion), скорости генерации и т.п. Первое время я использовал платформу HuggingFace, где ежедневно публикуются около сотни новых моделей. Но кто им пользовался, знает, насколько там неудобный и слабый поиск: даже точные совпадения по названию он иногда не выдаёт. Плюс к этому, приходится тратить достаточно времени, чтобы найти и сравнить модели по нескольким критериям. В этой статье я расскажу, как решил проблему выбора языковых моделей.
В этой статье я покажу, как можно без программирования парсить, анализировать и визуализировать данные из RSS- и Atom-лент на примере загрузки и парсинга фида Apple iTunes, а также проведения последующего конкурентного анализа приложений.
Представим, что мы собираемся публиковать в App Store мобильное приложение по тематике “медитация”. И хотим посмотреть, как обстоят дела в этой нише. При этом сделаем вид, что не знаем о существовании таких сервисов, как App Annie, Sensor Tower и аналогичных. Или знаем, но нам расхотелось делать в них детальный анализ, как только мы узнали стоимость месячной подписки. Поэтому будем действовать как экономные бутстрапперы и анализировать “сырые” данные от компании Apple. Тем более, что сделать это оказалось очень просто.
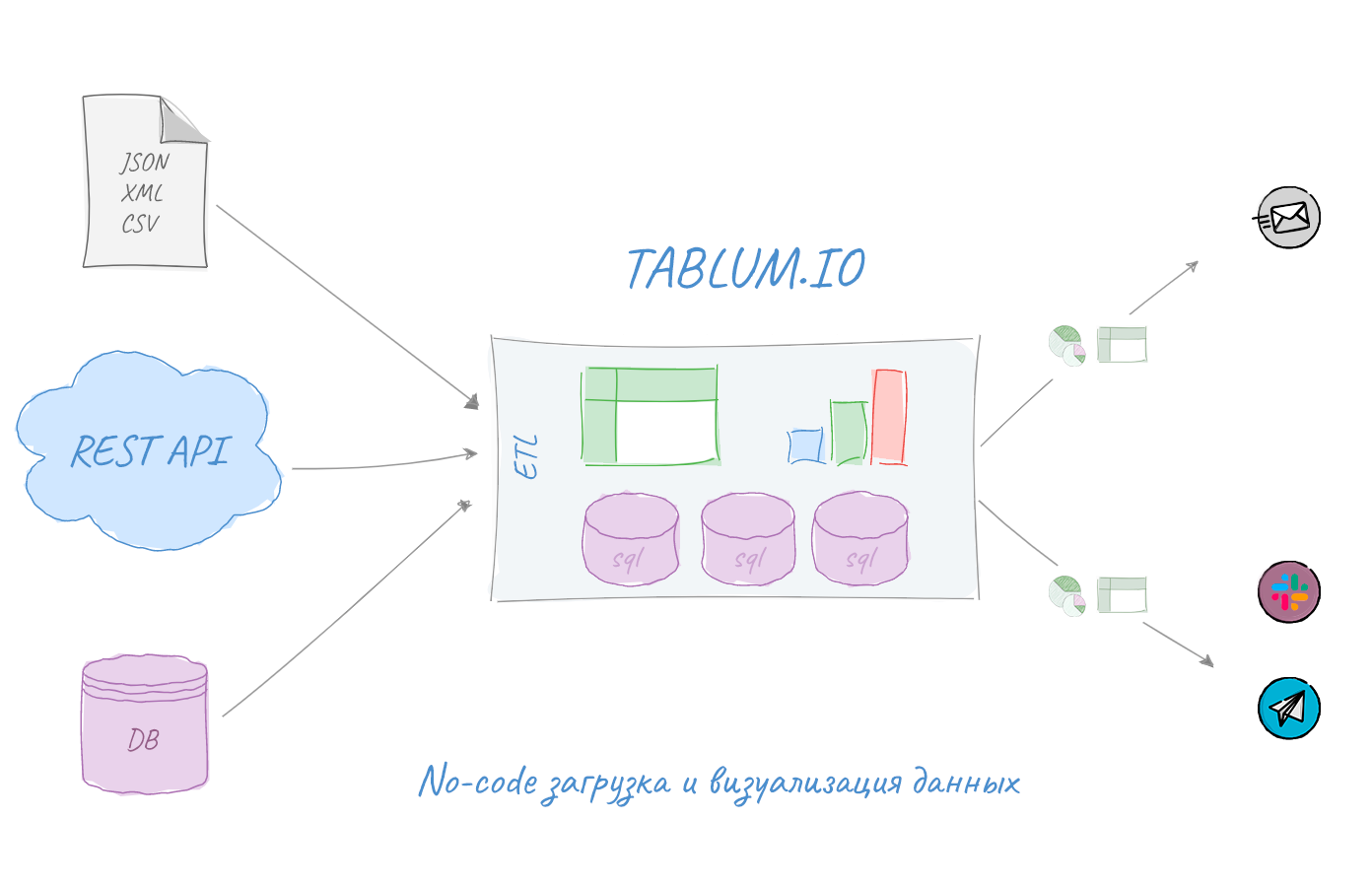
Признаюсь честно, у меня как у программиста, хоть и не настоящего, есть недоверие к «no-code» решениям. То есть тем, которые не требуют программирования, где всё можно делать через drag-and-drop и клики мышкой. Но после полугода разработки собственного «no-code»ETL сервиса с визуализацией данных я изменил отношение к этому классу продуктов, начал ими пользоваться и даже получать пользу, экономя время на рутинных операциях по анализу данных из логов, баз данных и файлов.
В этой заметке я предложу несколько вариантов загрузки и парсинга данных из сервисов и по URL с «материализацией» в SQL базу, покажу как за пару минут собрать свой информер с отправкой в Telegram, Slack или на email. И всё это произойдет без единой строчки кода (потому что в сервисе TABLUM.IO этот код уже кто-то написал ;-). «Алхимия данных» начинается под катом.
По работе мне часто приходится рисовать разные схемы, диаграммы процессов и графики, в том числе и те, которые потом используются в качестве иллюстраций для сайта, статей и презентаций. Всё бы ничего, но есть у диаграмм и графиков, сделанных в популярных онлайн-сервисах наподобие draw.io или lucidcharts одна беда — они выглядят как-то слишком уныло и «олдскульно», в духе «90-х». Всю эту инфографику хотелось бы сделать более заметной, привлекательной и душевной (и, желательно, без привлечения дизайнера).
Так у меня возникла идея создания инструмента для отрисовки диаграмм и графиков в стиле «нарисовано от руки». Об истории создания сервиса и «подводных камнях» я расскажу в этой заметке.
В мае 2021 года меня похитили инопланетяне и приказали разработать сервис аналитики данных, в простонародье именуемый “self-service BI (business intelligence)”. И не просто какой-то аналог Redash или Superset в масштабе 1:43, а с нормальной поддержкой загрузки данных из файлов (локальных и через веб), ну и, конечно, с коннекторами к популярным базам данным. Например, чтобы можно было импортировать содержимое файлов json, xml или логов, а потом сджойнить их с выгрузкой из clickhouse. И ещё чтобы графики рисовались. Дашборды тоже было бы неплохо, но можно и без них.