Комментарии 15
Гораздо удобнее было бы сравнение вида:
Берем какой-нибудь docker образ с вот-такой-конкретной-моделью и запускаем его на наших серверах (таком, таком и таком)
Выполняем одни и те же запросы/обучение и смотрим разницу во времени
Сейчас прогоняю тесты на A4000/5000 4900 H100 Epyc 4-поколения на koboldcpp (хотя можно любой бенчмарк, но тут тоже удобно и окно ответа задать и gpu offload) на иференс с модельками Mixtral и Lllama с разным квантованием и размером.
Starling-LM-10.7B-beta-Q4_K_M.gguf
mixtral-8x7b-instruct-v0.1.Q3_K_M.gguf
llama-2-70b-chat.Q4_K_M.gguf
7.5, 26 и 41 гиг соответственно весят.
единственное что среднюю модельку попробую загнать по слоям полностью в GPU, возьму чуть меньше. Все с максимальный использованием gpu offload.
Еще добавлю свою личную RTX 4060 в сравнимых условиях, так как в теории она по производительности равна A4000 но проигрывает в памяти (8 против 14 гигов)
H100 у нас на EPYC 7451 24 ядерных, 4090 на i9-14900 или на Райзенах, но CPU не буду трогать, но попробую без GPU и на десктопных 8x7b модель.
Все в единую табличку сведем, еще добавлю производительности в том же Automatic1111 c SD XL моделью.
По обучению смотрю, как лучше тест сделать, чтобы сравнение было корректным, если подскажете, буду рад, как и по тестам, что еще хотелось бы сравнить.
Без цен на железо и затрат энергии на fflops, нет никакого смысла обсуждать, какое лучше железо выбирать. Да бывают минимальные требования по объему памяти на ноду, но в этих случаях не до жиру, бери что надо и не заморачивайся.
Разница в производительности cpu и gpu может разниться от 10крат до 100 (например если нужны batch вычисления с одной нейронной)
Сравнение от людей, которые не понимают о чем пишут. На уровне рекламы - есть 5 по 2 или 4 по 3. Выбирайте!
Если вы ищете стабильность в долговременных вычислениях для обучения моделей, можно рассмотреть видеокарты Nvidia RTX A4000 или A5000.
Раскройте нам глупым сию причинно-следственную связь, ну и смысл предложения заодно в части «стабильность в долговременных вычислениях». При том что эти карты вообще не для обучения, как бы.
С чего вы взяли что они не для обучения? По производительности да, A4000 это 3070 Ti примерно, и сама NVidia именно A4000/5000 преподносила и для машинного обучения (да, это PCI-E, типа рейтрейс, CAD и видео, но по тестам норм и в обучение применяли, где хватало 16+ Гб). А вот наличие той же ECC памяти или необходимости работать пару суток под нагрузкой вам скажется на десктопных картах. Это извечный спор (reddit вам в помощь), что нафига карта в 3-5 раз дороже десктопной, но для чего то они существуют и покупаются? Вот пример бенчмарков на Deep Learn: https://www.exxactcorp.com/blog/Benchmarks/nvidia-rtx-a4000-a5000-and-a6000-comparison-deep-learning-benchmarks-for-tensorflow
Даже в инференсе по тестам та же 4090 на длинных текстах начинает ошибки выдавать в больших моделях (понятно, что которые влазят в 24 гига 4090) гораздо раньше и чаще, чем H100 - хотя карты тоже сравнимы.
Возможно, Вы путаете инференс и обучение? Понятно, что тренировать можно хоть на Jetson, но эти карты не для обучения, а для проф использования и инференса (сервинга моделей).
Официально они для рабочих станций, но и 3090/4090 игровые. ... и A4000/5000/6000 почему-то используют для обучения. Почему бы и нет?
Понятно что сейчас рекомендации A6000 или A100/H100 для больших моделей (официально от Nvidia) и 4080/4090 для S и M моделей (неофициально, но поддержка есть в дровах) и тем более с поддержкой 8-bit Float. Поэтому вопрос будет только в средствах. По мне взять недорогой сервер на A5000, например по цене в два раза меньше, чем на 4090, где по производительности обучения там около 60% разница, а не в два раза для LoRA и небольших датасетов будет оптимальным. И стабильность выше. Люди берут даже 3090 до сих пор для обучения (хотя тут A5000 при текущих ценах надежней будет и одинаково).
По схемам же - вот такое есть: https://fullstackdeeplearning.com/cloud-gpus/dettmers_recs.png
Тут также можно не соглашаться :)
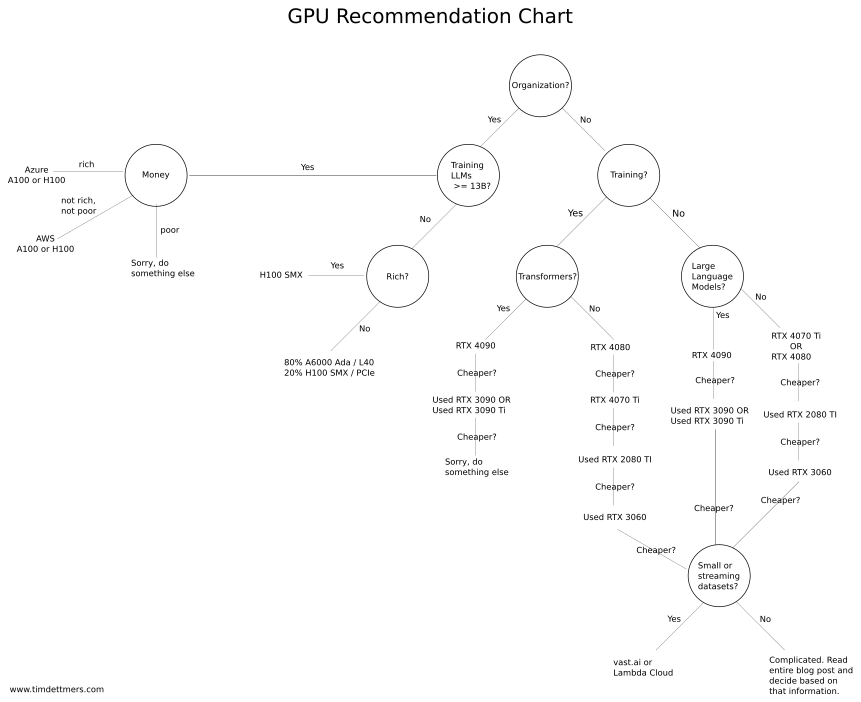{kind=link}
Блин, зачем собирать север под временную, да и несколько не конкретную задачу, когда можно просто снять в аренду? Купленный/собранный собственный сервер может не вывезти ваш проект, может оказаться избыточным, потом потребует апгрейда или продажи с потерей средств. Если есть задача обучение ИИ - то всегда лучше временная аренда конкретного железа для конкретной цели. Тот же популярный Vast.AI или самый доступный Clore.AI - там есть любые сервера под очень разные задачи. Зачем тратить время (самый ценный ресурс) на выбор/сборку и обслуживание железа, когда его лучше потратить на то в чем шариш - написание кода? Для тех кто создает и обучает нейросети сборка железа, это как шаг назад, имхо.
по теме вопроса, нейронку то зачем то обучают? наверное хотят пользоваться? под это тоже аренда?
Всегда нужно уметь считать затраты - либо их большая часть пойдет в капитальные либо операционные. При использовании облачных услуг идет значительная переплата в операционных затратах но почти обнуляются капитальные.
Если характер использования ресурсов постоянный, то выгоднее приобрести свое железо (если смотреть по ценам на облачные услуги, а у вас не мегаватный суперкомпьютер, то уже через 3-6 месяцев непрерывного использования свое железо выгоднее) а вот если эпизодический, то скорее всего выгоднее взять в аренду.
Ну и все решают минимальные требования,куда деваться, если требуется дообучить 70B llama? даже 8bit квантизация при тюнинге с помощью peft (например тюнинг токенизера) даже с десктопными 24gb собрать будет не просто. А серверные gpu повышают стоимость раз в 10.
p.s. доступный clore? это самый дорогой из известных мне, раза в 4-5 дороже vast
В любом случае вы арендуете что-то: или серверное время (причем не факт, что оно вам на 100% достанется и вы не выберете ресурсы) или мощности. VPS или VDS - тут ваш выбор. Первое дешевле и уже в готовой конфигурации, выделенный же 100% гарантирует, что все эти мощности ваши и они тоже идут в готовой конфигурации. Я вот на тесте VPS-ки проверяя маленькие модельки в чатботе на CPU выбрал 500% загрузки процессора. То есть на любом таком ресурсе вы получите одну ноду забитую до отказа страждущими. И ресурсы там получит тот, кто больше заплатил.
Как выбрать правильный сервер c подходящими для ваших нейросетей CPU/GPU