Achievement unlocked: на Stack Overflow появился первый пользователь с 1 миллионом баллов репутации.
Stack Overflow открыт в сентябре 2008 года и с тех пор помогает разработчикам со всего мира находить необходимые ответы на технические вопросы. Например, сайт показал миллиону пользователей выход из Vim. На январь 2017 года на Stack Overflow 8 миллионов зарегистрированных пользователей, 15 миллионов вопросов и 24 миллиона ответов. Еще десять лет назад ничего этого не было.

Stack Overflow открыт в сентябре 2008 года и с тех пор помогает разработчикам со всего мира находить необходимые ответы на технические вопросы. Например, сайт показал миллиону пользователей выход из Vim. На январь 2017 года на Stack Overflow 8 миллионов зарегистрированных пользователей, 15 миллионов вопросов и 24 миллиона ответов. Еще десять лет назад ничего этого не было.

 Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают
Всем привет. Меня зовут Игорь Акимов, я руководитель направления мобильных продуктов ABBYY. Наверное, многие знают  Мы уже
Мы уже  В предыдущем посте мы
В предыдущем посте мы  Хорошая новость™: теперь в
Хорошая новость™: теперь в  Думаем, читателям нашего блога не нужно рассказывать подробно, что такое словарь ABBYY Lingvo. C этого продукта началась компания ABBYY 27 лет назад. Сначала словарь можно было использовать только на компьютерах, потом появились мобильные приложения и онлайн-сервисы. Недавно мы открыли доступ к словарям Lingvo для сторонних разработчиков на сайте
Думаем, читателям нашего блога не нужно рассказывать подробно, что такое словарь ABBYY Lingvo. C этого продукта началась компания ABBYY 27 лет назад. Сначала словарь можно было использовать только на компьютерах, потом появились мобильные приложения и онлайн-сервисы. Недавно мы открыли доступ к словарям Lingvo для сторонних разработчиков на сайте  Несмотря на прогнозы о скором наступлении светлого безбумажного будущего, объём бумажных документов всё ещё огромен. Часть из них сканируется и продолжает свою «жизнь» уже в электронном варианте – но только в виде изображений. В среднем в организациях объем сканированных копий составляет 30% от всех документов, которые хранятся в электронном виде. В госсекторе он достигает 41,5%, в ритейле – 17%, в сфере услуг – 23%, в банках и телеком-сфере приближается к 45%. Когда сканы документов лежат себе в нужной папке или делают работу, для которой они предназначены, – это хорошо. Плохо, когда кто-то пытается использовать данные из этих сканов в мошеннических схемах или как-то иначе злоупотреблять ими. Чтобы конфиденциальная информация не «утекла», в информационные системы компаний устанавливают DLP – системы предотвращения утечек.
Несмотря на прогнозы о скором наступлении светлого безбумажного будущего, объём бумажных документов всё ещё огромен. Часть из них сканируется и продолжает свою «жизнь» уже в электронном варианте – но только в виде изображений. В среднем в организациях объем сканированных копий составляет 30% от всех документов, которые хранятся в электронном виде. В госсекторе он достигает 41,5%, в ритейле – 17%, в сфере услуг – 23%, в банках и телеком-сфере приближается к 45%. Когда сканы документов лежат себе в нужной папке или делают работу, для которой они предназначены, – это хорошо. Плохо, когда кто-то пытается использовать данные из этих сканов в мошеннических схемах или как-то иначе злоупотреблять ими. Чтобы конфиденциальная информация не «утекла», в информационные системы компаний устанавливают DLP – системы предотвращения утечек. 

 От редактора. Сделать эту статью меня вдохновил
От редактора. Сделать эту статью меня вдохновил 
 В чем разница между двумя этими определениями инициализированных локальных переменных С/С++?
В чем разница между двумя этими определениями инициализированных локальных переменных С/С++? Но для начала – маленькое отступление. Систему распознавания текста в наших продуктах можно описать очень просто. У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы. Задача сегментации ставится примерно так: есть страница, надо её декомпозировать на текстовые и нетекстовые элементы.
Но для начала – маленькое отступление. Систему распознавания текста в наших продуктах можно описать очень просто. У нас есть страница с текстом, мы разбираем ее на текстовые блоки, затем блоки разбираем на отдельные строчки, строчки на слова, слова на буквы, буквы распознаем, дальше по цепочке собираем все обратно в текст страницы. Задача сегментации ставится примерно так: есть страница, надо её декомпозировать на текстовые и нетекстовые элементы. 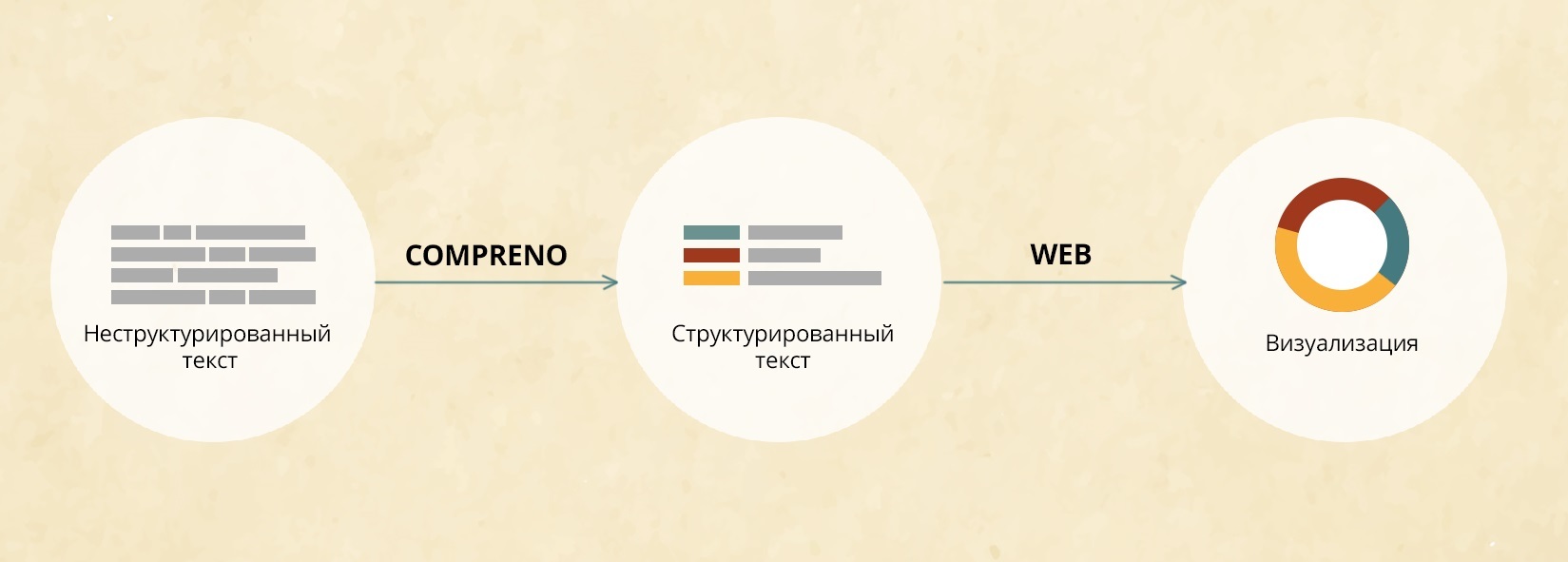
 Новейшая история денежного обращения в Бразилии – это череда деноминаций, первая из которых была проведена в 1942 году, а последняя – в 1994 году. К 1994 году национальная валюта Бразилии – крузейро – была настолько слабой, что в магазинах цены назначались в условных единицах, рядом с цифрами писали слово “real” – «настоящая» цена. В 1994 от лишних нулей решили избавиться, а слово “real”, к которому все привыкли, стало названием новой валюты – реал (впрочем, точно так же называлась денежная единица Бразилии до 1942 года).
Новейшая история денежного обращения в Бразилии – это череда деноминаций, первая из которых была проведена в 1942 году, а последняя – в 1994 году. К 1994 году национальная валюта Бразилии – крузейро – была настолько слабой, что в магазинах цены назначались в условных единицах, рядом с цифрами писали слово “real” – «настоящая» цена. В 1994 от лишних нулей решили избавиться, а слово “real”, к которому все привыкли, стало названием новой валюты – реал (впрочем, точно так же называлась денежная единица Бразилии до 1942 года). 

