Комментарии 37
Спасибо за ссылку. Нет, на прямую не пробовал. Хотя просматривается некая схожесть подхода. И не хотеться все описывать полиномами, каким ми бы хорошими они не были (см. лирическое отступление выше).
Можно поинтересоваться, с какой целью вы вставляете не прямую ссылку, а через yandex.kz с учётом переходов?
О… случайно — поторопился. Исправляю
МГУА
МГУА
Еще не маловажным моментом является, тот факт что практически все программы при осуществлении фиттинга работают лишь с данным сигналом Y и автоматически не осуществляют фиттинг производной этого сигнала, что может привести к малозначимым результатам.
Не могли бы вы пояснить данное утверждение? Желательно примером.
Пытаясь описать один и своих экспериментальных сигналов тремя гауссианами в Ориджине, я был несколько удивлен, когда программа спросила меня, а где должны быть вершины (максимумы) этих пиков. Одной из задач фитинга, как раз и является их нахождение, а Ориджин пытается получить эту информацию от пользователя, чтобы потом применить один из своих алгоритмом для описания «веток». При этом получается полная ерунда.
А причиной тому, по моему, является тот факт, что Ориджин автоматически не учитывает в алгоритме мультифитинга требование к совпадению производных оригинального сигнала и глобальной расчетной функции.
Получается, что вроде, отличие расчетного сигнала (красная кривая на графике) от экспериментального не очень большие (Ориджин, как мог провел оптимизацию), но результат не тот, что надо.

А причиной тому, по моему, является тот факт, что Ориджин автоматически не учитывает в алгоритме мультифитинга требование к совпадению производных оригинального сигнала и глобальной расчетной функции.
Получается, что вроде, отличие расчетного сигнала (красная кривая на графике) от экспериментального не очень большие (Ориджин, как мог провел оптимизацию), но результат не тот, что надо.
Ориджин спрашивает про начальные параметры. Во многих случаях это правильно, потому что положения максимумов известны (в XPS, например). И если вам не удалось что-то подогнать в ориджине, это значит что вы не умеете им пользоваться (и настраивать). Ваш пример прекрасно это иллюстрирует.
Когда положения максимумов известны, это не может не радовать. Бывает, что и в XPS (видел примеры, когда расшифровывали сигналы от разных атомов углерода (около 10 шт) не очень сложных органических молекул, адсорбированных на атомарно чистых определенных металлических поверхностях ) положения некоторых максимумов приходилось искать фиттингом, так как на оригинальном спектре их присутствие было крайне не просто заметить.

При фите Origin действительно не учитывает производные от сигнала. Но когда Вы задаете начальное приближение в Peak Analyzer можно воспользоваться функцией Find Peaks и там уже Origin умеет находить пики с помощью разных алгоритмов, в том числе с помощью первой и второй производных. Правда если у вас сложный спектр, в котором к тому есть шум, то это всё работает плохо, пару сотен лишних пиков Origin запросто добавить может :)
А причиной тому, по моему, является тот факт, что Ориджин автоматически не учитывает в алгоритме мультифитинга требование к совпадению производных оригинального сигнала и глобальной расчетной функции.
А должен? См. комментарий от koreec выше (увы, плюсик поставить не могу). А если так, то хотелось бы видеть математико-статистическое обоснование вашего подхода. Просто без него он абсолютно непригоден для серьезного использования.
Получается, что вроде, отличие расчетного сигнала (красная кривая на графике) от экспериментального не очень большие (Ориджин, как мог провел оптимизацию), но результат не тот, что надо.
У вас получилось лучше? Сильно сомневаюсь, хотя бы потому что несмотря на то, что Вы приводите более или менее правильную формулу в тексте публикации (после слов):
Ошибка — она же метрика качества аппроксимации исходного сигнала и его производной определяется по стандартной формуле:
в коде вы считаете ее неправильно:
def Two_Signals_error(self, data_exp_x, data_exp_y, data_th_x, data_th_y): # Intended be to called with any two signals which have to be compared
try:
error_y = np.zeros(data_th_x.size, dtype='f2')
for i in range(0, data_th_x.size):
error_y[i] = math.sqrt( (data_exp_y[i] - data_th_y[i])**2 )
return 1000*np.sum(error_y)/math.sqrt((data_th_x.size-1)*data_th_x.size)
except AttributeError:
pass
Большое спасибо, действительно, ошибка ранее считалась не так, как указано в формуле в тексте статьи. Исправил, перезалил на гитхаб. Абсолютная величина ошибки уменьшилась, прочих, сколь-либо существенных изменений нет.
Должен ли Ориджин учитывать производную при фитинге — не знаю, это вопрос к Ориджину.
Подумав на эту тему (нужно ли учитывать поведение производной при фиттинге или нет), могу сказать, что тут нужно не давать математико-статистическое обоснование, уточнить для чего нужно описывать экспериментальные данные той или иной теоретической зависимостью.
Если формально ставить задачу, таким образом: «на заданном промежутке подобрать такую функцию, чтобы ошибка была меньше допустимой величины». То, тут точно нет никаких требований на производную.
Если же в метрику добавить условие на минимизацию ошибки производной, то можно получить от расчетной функции нечто большее. К примеру из общефизических представлений, она будет лучше повторять контур оригинального сигнала, ценность (полезность) ее значений за пределами ранее заданного интервала может также возрасти.
Должен ли Ориджин учитывать производную при фитинге — не знаю, это вопрос к Ориджину.
Подумав на эту тему (нужно ли учитывать поведение производной при фиттинге или нет), могу сказать, что тут нужно не давать математико-статистическое обоснование, уточнить для чего нужно описывать экспериментальные данные той или иной теоретической зависимостью.
Если формально ставить задачу, таким образом: «на заданном промежутке подобрать такую функцию, чтобы ошибка была меньше допустимой величины». То, тут точно нет никаких требований на производную.
Если же в метрику добавить условие на минимизацию ошибки производной, то можно получить от расчетной функции нечто большее. К примеру из общефизических представлений, она будет лучше повторять контур оригинального сигнала, ценность (полезность) ее значений за пределами ранее заданного интервала может также возрасти.
Если же в метрику добавить условие на минимизацию ошибки производной, то можно получить от расчетной функции нечто большее.
Что конкретно? В цифрах, пожалуйста. А я пока предскажу, что сумма квадратов отклонений экспериментальных данных от предсказания у Вас будет больше по сравнению с классическим нелинейным методом наименьших квадратов.
К примеру из общефизических представлений, она будет лучше повторять контур оригинального сигнала, ценность (полезность) ее значений за пределами ранее заданного интервала может также возрасти.
Извините, это называется «лучше на мой выпуклый военно-морской глаз». Что такое «ценность (полезность)» в цифрах с научной точки зрения? Так, чтобы эта ценность была объективно одинаковой не только для вас, но и для других исследователей и тех людей, которые будут пользоваться Вашими результатами. Т.е. объективной и повторяемой. Нет — значит это не научный подход. Поймите, вариант, «я художник, я так вижу» в науке не работает.
И, да, когда вы пытаетесь минимизировать одновременно и сумму квадратов отклонений функции от предсказания и сумму квадратов отклонений ее производной (сглаженной ручками — опять субъективный произвол!), то вы минимизируете сумму весов огурцов и бананов. Единицы измерений у этих сумм разные. Ах, нужен коэффициент? Так это опять произвол. Вам нравится один вариант, другому исследователю другой, а какой правильный? Где критерий?
P.S. Ну, не верите, можете попробовать отправить статью в серьезный рецензируемый научный журнал, или просто поговорите со знакомыми специалистами по мат.статистике.
Я понимаю, что это дополнительное требование вызывает подобного рода вопросы, т.к. обычно его не предъявляют в задачах аппроксимации. В тоже время меня искреннее удивляет, что для вы не видите реальной пользы от этого требования. Подскажу, ее научная польза — это не дальнейшее уменьшение ошибки между расчетным и экспериментальным сигналом, начиная с какого-то уровня ее дальнейшая минимизация будет уже бессмысленна.
Попробую пояснить, но уже завтра. Хотя, в принципе, все уже написано.
Замечу, что никто не пытается минимизировать суммуошибок «огурцов» и «бананов», они минимизируются отдельно друг от друга, пусть даже по одному принципу. Статей в серьезных научных рецензируемых журналах у меня достаточно :)
Попробую пояснить, но уже завтра. Хотя, в принципе, все уже написано.
Замечу, что никто не пытается минимизировать суммуошибок «огурцов» и «бананов», они минимизируются отдельно друг от друга, пусть даже по одному принципу. Статей в серьезных научных рецензируемых журналах у меня достаточно :)
Замечу, что никто не пытается минимизировать суммуошибок «огурцов» и «бананов», они минимизируются отдельно друг от друга,
С интересом услышу объяснения.
Попробую объяснить, привлекая абстрактные и реальные примеры. С ходу вижу пару причин (необходимостей).
Необходимость №1.
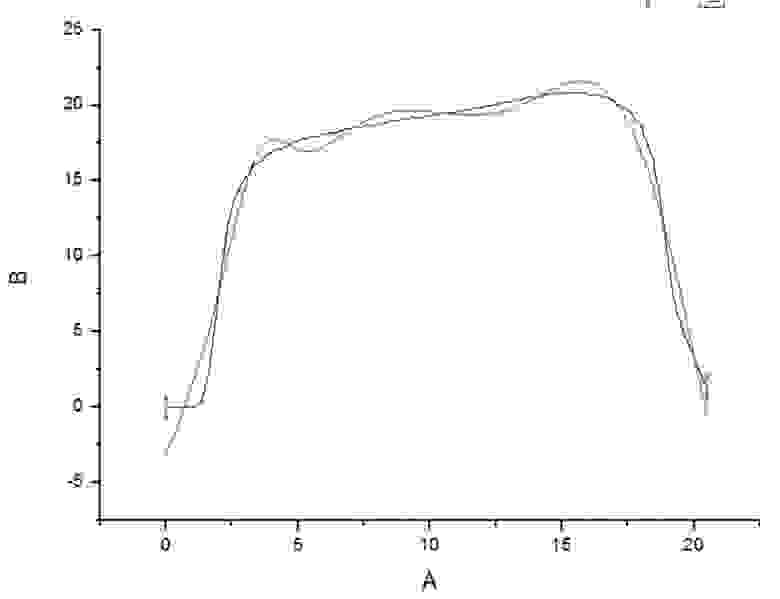
Если ограничиться лишь условием минимизации ошибки между экспериментальным и расчетными сигналами, то, в зависимости от выбранной(ых) функции(й) могут получиться ситуации (Рис 1), когда расчетный сигнал (Th1 или Th2), вроде, и дает маленькую и приемлемую по своей величине ошибку (тут тоже возможны варианты, к примеру, что какая-то Thi будет очень точно попадать в экспериментальные точки, но между ними будет вести себя совсем не так, как «истинная» кривая. Или вариант, когда она не совсем попадает в экспериментальные точки, но попадает довольно близко, так, что разница — delta будет в пределах допустимой экспериментальной ошибки), но огибает точки не так, как это бы делала «истинная» кривая, соответствующая модели, которая описывает данный эксперимент. При этом неизбежно будут возникать бессмысленные минимумы и максимумы (вы ведь не требовали минимизации ошибки производных экспериментального и расчетного сигналов).
У физиков, химиков и т.д. задачей, как раз и является нахождение «истинной» кривой, пусть даже она даст большее (иногда даже очень большое) значение ошибки, чем абстрактная Thi, но в ней будет смысл, стоящей за ней физической или химической модели.

Рис. 1. Абстрактный пример, когда значения расчетной функция Th1 или Th2 довольно близки к экспериментальным значениям, но для них нет требования к близости их производных к производной экспериментального сигнала.
Теперь зайдем с конца и рассмотрим готовый результат фиттинга реальных экспериментальных данных (Рис 2 ) тремя кривыми: F1, F2 и F3, суперпозиция которых (F1+F2+F3) не только довольно близко подходит к экспериментальным точкам (абсолютная ошибка мала), но и весьма неплохо повторяет профиль экспериментальной кривой. Если бы вместо, полученной результате фиттинга кривой F1+F2+F3 у нас была бы кривая, типа Thi, полученная по алгоритму из Рис. 1, то было бы невозможно из Thi получить отдельные (главное осмысленные, т.е. отражающие реально происходящие физические процессы) F1, F2 и F3 кривые. У нас было бы много бессмысленных максимумов и минимумов, и совсем не факт, что хотя бы один из них, давал полезную информацию, как F1, F2 и F3.
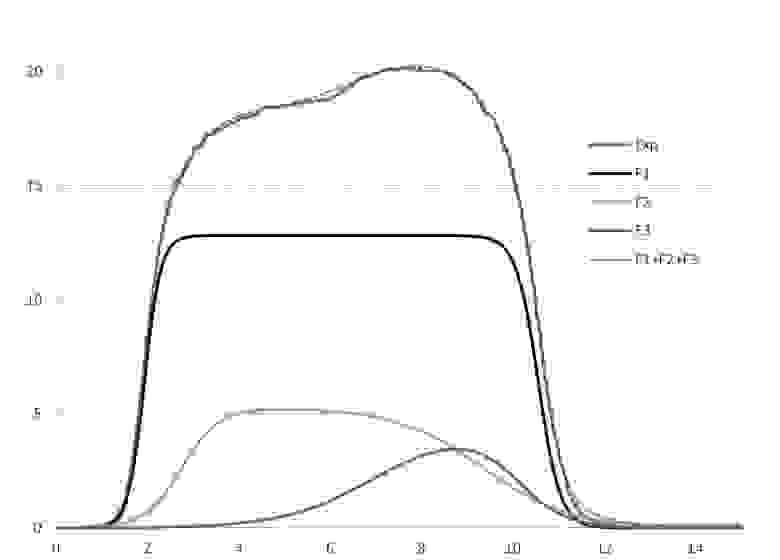
Рис. 2. Пример фиттинга экспериментальных данных (синяя кривая) расчетной кривой (красный пунктир), которая является суперпозицией (суммой) трех функций (F1, F2 и F3). Каждая из которых имеет свой физический смысл и проявляется в ходе эксперимента.
Наложив условие ( и совсем не факт, что это есть достаточное условие) минимизации производных, мы сильно сузили выбор самих функций для фиттинга и довольно просто получили значения параметров каждой из их, Рис. 3.
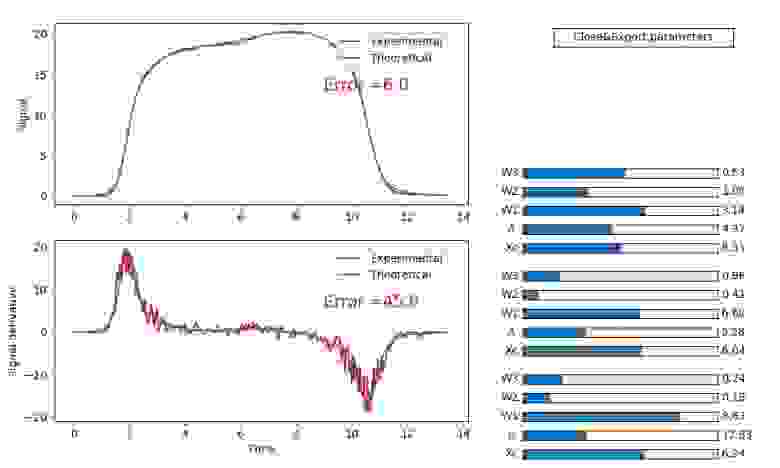
Рис. 3. Пример фиттинга экспериментальной кривой тремя функциями. Расчетная функция и ее производная достаточно хорошо описывают детали исходного сигнала и его производной, соответственно (хотя и тут есть пространство для улучшения....).
Важно заметить, что полученный набор параметров является не единственным, который дает столь малую ошибку сигнала и его производной. Но это уже другая тема…
Необходимость 2
Допустим мы находимся на правой границе интервала и пытаем фиттингом найти «истинную» функцию. Если мы будем учитывать как изменялся не только сам экспериментальный сигнал (к примеру координату движения частицы), но и его производная (скорость или энергия), мы сможем лучше подобрать физически осмысленную функцию(и) и ее параметры для экстраполяции кривой за границу интервала, т.е. предсказать ее дальнейшую скорость и траекторию. Здесь, позвольте без доказательств и конкретных примеров. Уверен, что студент первого курса по естественным наукам поймет о чем речь.
Необходимость №1.
Если ограничиться лишь условием минимизации ошибки между экспериментальным и расчетными сигналами, то, в зависимости от выбранной(ых) функции(й) могут получиться ситуации (Рис 1), когда расчетный сигнал (Th1 или Th2), вроде, и дает маленькую и приемлемую по своей величине ошибку (тут тоже возможны варианты, к примеру, что какая-то Thi будет очень точно попадать в экспериментальные точки, но между ними будет вести себя совсем не так, как «истинная» кривая. Или вариант, когда она не совсем попадает в экспериментальные точки, но попадает довольно близко, так, что разница — delta будет в пределах допустимой экспериментальной ошибки), но огибает точки не так, как это бы делала «истинная» кривая, соответствующая модели, которая описывает данный эксперимент. При этом неизбежно будут возникать бессмысленные минимумы и максимумы (вы ведь не требовали минимизации ошибки производных экспериментального и расчетного сигналов).
У физиков, химиков и т.д. задачей, как раз и является нахождение «истинной» кривой, пусть даже она даст большее (иногда даже очень большое) значение ошибки, чем абстрактная Thi, но в ней будет смысл, стоящей за ней физической или химической модели.

Рис. 1. Абстрактный пример, когда значения расчетной функция Th1 или Th2 довольно близки к экспериментальным значениям, но для них нет требования к близости их производных к производной экспериментального сигнала.
Теперь зайдем с конца и рассмотрим готовый результат фиттинга реальных экспериментальных данных (Рис 2 ) тремя кривыми: F1, F2 и F3, суперпозиция которых (F1+F2+F3) не только довольно близко подходит к экспериментальным точкам (абсолютная ошибка мала), но и весьма неплохо повторяет профиль экспериментальной кривой. Если бы вместо, полученной результате фиттинга кривой F1+F2+F3 у нас была бы кривая, типа Thi, полученная по алгоритму из Рис. 1, то было бы невозможно из Thi получить отдельные (главное осмысленные, т.е. отражающие реально происходящие физические процессы) F1, F2 и F3 кривые. У нас было бы много бессмысленных максимумов и минимумов, и совсем не факт, что хотя бы один из них, давал полезную информацию, как F1, F2 и F3.

Рис. 2. Пример фиттинга экспериментальных данных (синяя кривая) расчетной кривой (красный пунктир), которая является суперпозицией (суммой) трех функций (F1, F2 и F3). Каждая из которых имеет свой физический смысл и проявляется в ходе эксперимента.
Наложив условие ( и совсем не факт, что это есть достаточное условие) минимизации производных, мы сильно сузили выбор самих функций для фиттинга и довольно просто получили значения параметров каждой из их, Рис. 3.

Рис. 3. Пример фиттинга экспериментальной кривой тремя функциями. Расчетная функция и ее производная достаточно хорошо описывают детали исходного сигнала и его производной, соответственно (хотя и тут есть пространство для улучшения....).
Важно заметить, что полученный набор параметров является не единственным, который дает столь малую ошибку сигнала и его производной. Но это уже другая тема…
Необходимость 2
Допустим мы находимся на правой границе интервала и пытаем фиттингом найти «истинную» функцию. Если мы будем учитывать как изменялся не только сам экспериментальный сигнал (к примеру координату движения частицы), но и его производная (скорость или энергия), мы сможем лучше подобрать физически осмысленную функцию(и) и ее параметры для экстраполяции кривой за границу интервала, т.е. предсказать ее дальнейшую скорость и траекторию. Здесь, позвольте без доказательств и конкретных примеров. Уверен, что студент первого курса по естественным наукам поймет о чем речь.
Вы бы не могли добавить к вашему проекту на github.com эту экспериментальную кривую, а то мне что-то захотелось сравнить качество вашего фиттинга с классическим. Ну или показать ваши результаты для какой-нибудь имеющейся там кривой?
Если не ошибаюсь, был взят Пример4 от туда. Завтра проверю.
Нет, это файл Import_Exp_6
А, вы там минутами пользуетесь. Ну, я бы постеснялся пользоваться внесистемными единицами, но ладно, пренебрежем.
А теперь по делу. Увы, я в вашем комментарии не увидел ни одного ответа на мои вопросы, заданные 2-го декабря. Поэтому я начну с моего предсказания:
Таки да, написанная за час на коленке
за несколько секунд находит решение для вашей кривой со среднеквадратичной ошибкой в два раза меньше, чем ваше решение с«учетом производной»:
Тут ошибка вычислялась по вашей (все равно неправильной формуле — сумму квадратов отклонений надо делить на число измерений минус число оцениваемых параметров), но не умножалась на тысячу, как зачем-то сделано в вашем коде. Не надо говорить о неправильном физическом смысле моего решения — все три ваших процесса описываются одинаковыми параметрическими кривыми… Ну и я сильно сомневаюсь, что работа какого-то устройства типа катализатора описывается вашими «сигмоидами». Там надо решать офигительные системы нелинейных уравненией в частных производных… Газодинамика, хим.реакции в объеме и на поверхности катализатора, диффузия через пористые керамически стенки, тепловые задачи…
Если поиграть с начальным приближением (подвигать центры кривых влево-вправо и ампитуды поизменять), то можно найти еще 3-4 локальных минимума, каждый из которых будет лучше вашего «решения». Один, кстати, недалеко от вашего — (если параметры кривых срисововать с вашей картинки и использовать в качестве начального приближения). И, да, качество этого решения снова будет лучше вашего (Error = 0.003528680528112783).
Очевидно, никаких осцилляций автоматически найденных с помощью классического алгоритма кривых не будет, поскольку каждая из теор.кривых достаточно гладкая. Ну и имея 15 оптимизационных параметров, можно что-угодно воспроизвести. Т.е. такие проблемы могут возникнуть только если функциональный базис выбран неудачно. Но тут уж каждый ССЗБ.
Итого — при фиттинге обсуждаемой кривой никакие танцы с бубном не нужны. Классические методы работают отлично. Нет улучшений, значит, и «мировой эфир» не нужен.
При одном условии — если скорость частицы измеряется независимо. Численное дифференцирование измеряемой координаты и включение ее в оптимизацию ничего не даст. Это просто не добавляет новой информации.
А вот это снова ненаучный подход. Вы утверждаете, вы и доказываете. А я пока продолжу считать вашу гипотезу как минимум не доказанной. А в одном случае — см.выше — просто неверной — см. мои результаты фиттинга вашей кривой.
А теперь по делу. Увы, я в вашем комментарии не увидел ни одного ответа на мои вопросы, заданные 2-го декабря. Поэтому я начну с моего предсказания:
А я пока предскажу, что сумма квадратов отклонений экспериментальных данных от предсказания у Вас будет больше по сравнению с классическим нелинейным методом наименьших квадратов.
Таки да, написанная за час на коленке
простейшая программа нелинейной оптимизации
import csv
import datetime
from typing import Tuple
import numpy
import matplotlib.pyplot as plt
import scipy.optimize
def get_data(file_name: str) -> Tuple[numpy.ndarray, numpy.ndarray]:
with open(file_name) as csvfile:
rdr = csv.reader(csvfile, delimiter=';')
next(rdr)
tt, yy = [], []
for row in rdr:
tt.append(datetime.datetime.strptime(row[0], '%d.%m.%Y %H:%M:%S'))
yy.append(float(row[1]))
return numpy.array([(dt-tt[0]).total_seconds() for dt in tt])/60, numpy.array(yy)
class Residuals:
def __init__(self, ttt: numpy.array, yyy: numpy.array):
self._ttt = ttt
self._yyy = yyy
def _sigmoid(self, args: numpy.ndarray) -> numpy.ndarray:
xc, a, w1, w2, w3 = args
return a*(1-1/(1+numpy.exp(-(self._ttt-xc-0.5*w1)/w3)))/(1+numpy.exp(-(self._ttt-xc+0.5*w1)/w2))
def _prediction(self, args):
return self._sigmoid(args[0:5])+self._sigmoid(args[5:10])+self._sigmoid(args[10:15])
def __call__(self, args: numpy.ndarray) -> numpy.ndarray:
return self._yyy-self._prediction(args)
def plot_curves(self, args: numpy.array) -> None:
err = numpy.sqrt(numpy.sum(self(args)**2/(len(self._ttt)*(len(self._ttt)-1))))
print()
fmt = 'xc = {:11.8F} a = {:11.8F} w1 = {:11.8F} w2 = {:11.8F} w3 = {:11.8F}'
print(fmt.format(*args[0:5]))
print(fmt.format(*args[5:10]))
print(fmt.format(*args[10:15]))
print()
print('Error =', err)
print()
plt.plot(self._ttt, self._yyy)
plt.plot(self._ttt, self._prediction(args))
plt.plot(self._ttt, self._sigmoid(args[0:5]))
plt.plot(self._ttt, self._sigmoid(args[5:10]))
plt.plot(self._ttt, self._sigmoid(args[10:15]))
plt.grid()
plt.xlim(right=15.0)
plt.show()
def main() -> None:
ttt, yyy = get_data('Import_Exp_6.csv')
res = Residuals(ttt, yyy)
x0 = numpy.array([2, 10, 1, 1, 1,
4, 10, 1, 1, 1,
6, 10, 1, 1, 1])
scale = numpy.array([1, 1, 1, 1, 1,
1, 1, 1, 1, 1,
1, 1, 1, 1, 1])
bounds = numpy.array([[1, 1, 0, 0, 0, 1, 1, 0, 0, 0, 1, 1, 0, 0, 0],
[100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100, 100]])
# noinspection PyTypeChecker
x: scipy.optimize.OptimizeResult = scipy.optimize.least_squares(res, x0, jac='3-point', diff_step=1e-8*scale,
x_scale=scale, bounds=bounds, xtol=1e-14,
ftol=3e-16, gtol=1e-14, max_nfev=1000, verbose=1)
res.plot_curves(x.x)
if __name__ == '__main__':
main()
за несколько секунд находит решение для вашей кривой со среднеквадратичной ошибкой в два раза меньше, чем ваше решение с«учетом производной»:
xc = 7.94800396 a = 14.63107180 w1 = 5.29503234 w2 = 0.60003813 w3 = 0.27181285
xc = 3.57356967 a = 11.17972998 w1 = 3.39283920 w2 = 0.16275070 w3 = 0.46028389
xc = 6.11336115 a = 5.88055569 w1 = 7.34512284 w2 = 0.28137491 w3 = 0.54191075
Error = 0.0032602356426855014
Тут ошибка вычислялась по вашей (все равно неправильной формуле — сумму квадратов отклонений надо делить на число измерений минус число оцениваемых параметров), но не умножалась на тысячу, как зачем-то сделано в вашем коде. Не надо говорить о неправильном физическом смысле моего решения — все три ваших процесса описываются одинаковыми параметрическими кривыми… Ну и я сильно сомневаюсь, что работа какого-то устройства типа катализатора описывается вашими «сигмоидами». Там надо решать офигительные системы нелинейных уравненией в частных производных… Газодинамика, хим.реакции в объеме и на поверхности катализатора, диффузия через пористые керамически стенки, тепловые задачи…
Если поиграть с начальным приближением (подвигать центры кривых влево-вправо и ампитуды поизменять), то можно найти еще 3-4 локальных минимума, каждый из которых будет лучше вашего «решения». Один, кстати, недалеко от вашего — (если параметры кривых срисововать с вашей картинки и использовать в качестве начального приближения). И, да, качество этого решения снова будет лучше вашего (Error = 0.003528680528112783).
Очевидно, никаких осцилляций автоматически найденных с помощью классического алгоритма кривых не будет, поскольку каждая из теор.кривых достаточно гладкая. Ну и имея 15 оптимизационных параметров, можно что-угодно воспроизвести. Т.е. такие проблемы могут возникнуть только если функциональный базис выбран неудачно. Но тут уж каждый ССЗБ.
Итого — при фиттинге обсуждаемой кривой никакие танцы с бубном не нужны. Классические методы работают отлично. Нет улучшений, значит, и «мировой эфир» не нужен.
Необходимость 2
Допустим мы находимся на правой границе интервала и пытаем фиттингом найти «истинную» функцию. Если мы будем учитывать как изменялся не только сам экспериментальный сигнал (к примеру координату движения частицы), но и его производная (скорость или энергия), мы сможем лучше подобрать физически осмысленную функцию(и) и ее параметры для экстраполяции кривой за границу интервала,
При одном условии — если скорость частицы измеряется независимо. Численное дифференцирование измеряемой координаты и включение ее в оптимизацию ничего не даст. Это просто не добавляет новой информации.
т.е. предсказать ее дальнейшую скорость и траекторию. Здесь, позвольте без доказательств и конкретных примеров. Уверен, что студент первого курса по естественным наукам поймет о чем речь.
А вот это снова ненаучный подход. Вы утверждаете, вы и доказываете. А я пока продолжу считать вашу гипотезу как минимум не доказанной. А в одном случае — см.выше — просто неверной — см. мои результаты фиттинга вашей кривой.
Спасибо за комментарий.
Только смысл в нем какой, показать, что «автомобиль» (МНК, который применили на всем готовом, т.е. дали ему подходящие аналитические функции)) быстрее «пешехода» — ручного подбора параметров (и всего в 2 раза).
Без условно, польза от «автомобиля» есть он быстрый, т.е. может подобрать точные параметры быстрее (когда ему дали «автобан»), чем это делает человек руками (а «пешеход» ногами).
Про учет производной сигнала при ручном подборе параметров я уже писал, повторять смысла не вижу.
За пример кода тоже спасибо, думаю вставить в программу эту возможность.
Только смысл в нем какой, показать, что «автомобиль» (МНК, который применили на всем готовом, т.е. дали ему подходящие аналитические функции)) быстрее «пешехода» — ручного подбора параметров (и всего в 2 раза).
Без условно, польза от «автомобиля» есть он быстрый, т.е. может подобрать точные параметры быстрее (когда ему дали «автобан»), чем это делает человек руками (а «пешеход» ногами).
Про учет производной сигнала при ручном подборе параметров я уже писал, повторять смысла не вижу.
За пример кода тоже спасибо, думаю вставить в программу эту возможность.
Только смысл в нем какой, показать, что «автомобиль» (МНК, который применили на всем готовом, т.е. дали ему подходящие аналитические функции)) быстрее «пешехода» — ручного подбора параметров (и всего в 2 раза).
Кроме уменьшения суммы квадратов отклонений (на не сглаженных данных!), есть еще уменьшение ошибки определения величины оцениваемых параметров. Вот тут алгоритм поиска локального минимума дает некоторые гарантии на эти ошибки, а ваше «решение» — вообще на склоне.
Про учет производной сигнала при ручном подборе параметров я уже писал,
Ах, уже при именно ручном подборе? Да еще и неформализованный? А то вы в статье про свою цель написали несколько более глобальное:
В процессе самого фиттинга хотелось иметь возможность самому контролировать процесс подбора параметров,
Контроль — это, например, задание алгоритму, программе (минимизирующей сумму квадратов отклонений — хотя тот же scipy.optimize.least_squares умеет использовать и другие функции — более устойчивые к тем же выбросам.) ограничений на вариацию параметров, вплоть до их фиксации, а ручной подбор — это когда алгоритма просто нет. Вместо с точностью и повторяемостью.
а не доверять в слепую алгоритмам оптимизации,
Алгоритму доверять не нужно. Можно посмотреть на его исходные коды, протестировать, почитать документацию, попросить объяснений у авторов… Так же и вашим «учетом производной». Но теоретического математико-статистического обоснования нет, имплементации нет, автор ничего не объясняет (так, чтобы можно было воспроизвести) его результаты.
в первую очередь из-за того, что они не учитывают совпадение производных экспериментального и расчетного сигналов
А они должны? Докажите!
Ну и наконец, неужели вы не понимаете, что по производной можно востановить функцию с точностью до константы?
Последний гвоздь — почитайте про принцип Парето. Но его в физике не применяют.
Весьма интересно, спасибо за статью и код. Потребность в таком интрументе регулярно возникает. Но очень интересно посмотреть на реализацию, сам пишу иногда на питоне скрипты как для расчетов, так и обработки эксперимента.
Вставлю свои пять копеек.
OriginPro умеет делать фитинг комплексной функции. Можно попробовать переобозначить вашу функцию таким образом, чтобы производная от нее была комплексной частью и воспользоваться данной процедурой.
В случае если пик находится на крыле, то можно воспользоваться функцией Peak Fitting with Baseline.
Но вы все-таки правы. Бываю случаи когда универсальный и громоздкий OriginLab просто выносит мозг, и не может нормально аппроксимировать данные. В последний раз у меня такое было, с данными, которые по сути представляли произведение близких несимметричных Лоренцевских контуров. Мне решить проблему помог Fityk. И он позволяет один набор данных аппроксимровать несколькими разными функциями, не только Лоренцом и Гауссом, но любой из достаточно большого списка. Настоятельно рекомендую попробовать, к тому же он с открытым кодом.
OriginPro умеет делать фитинг комплексной функции. Можно попробовать переобозначить вашу функцию таким образом, чтобы производная от нее была комплексной частью и воспользоваться данной процедурой.
В случае если пик находится на крыле, то можно воспользоваться функцией Peak Fitting with Baseline.
Но вы все-таки правы. Бываю случаи когда универсальный и громоздкий OriginLab просто выносит мозг, и не может нормально аппроксимировать данные. В последний раз у меня такое было, с данными, которые по сути представляли произведение близких несимметричных Лоренцевских контуров. Мне решить проблему помог Fityk. И он позволяет один набор данных аппроксимровать несколькими разными функциями, не только Лоренцом и Гауссом, но любой из достаточно большого списка. Настоятельно рекомендую попробовать, к тому же он с открытым кодом.
В ЯМР-спектрах Mestrenova точно умеет разворачивать весь спектр в сумму лоренцианов, иногда вытаскивает почти неразрешенные сигналы, особенно в алифатической области. На рисунке, кстати, еще вполне неплохой случай — все пики видны, КССВ (расстояния между ними) можно померить.
Прежде всего хочу сказать, что это отличная работа. И чем больше будет таких инструментов, тем лучше. Сам я занимаюсь спектроскопией комбинационного рассеяния света и уже отчаялся найти идеальную программу для фита спектров :)
Несколько комментариев:
1.
В OriginPro много встроенных функций (около двух десятков, вот полный список) для фита в режиме Peak Analyzer. Другое дело, что для фита спектральных кривых не все из них подходят. Но можно добавить свою функцию. Я так в своё время определенный участок спектра аппроксимировал функцией связанных гармонических осцилляторов. Но конечно делать всё это в Origin так себе, долго и неэффективно.
2. Выше уже рекомендовали Fityk, это лучшая из программ для фита, которую я видел. Очень удобный графический интерфейс, легко задать первое приближение. Хотя сами алгоритмы оптимизации, мне кажется, работаю несколько хуже чем в Origin, часто не сходятся и приходится всё полностью подгонять руками. У Fityk есть одна «киллер фича», за которую я его особенно люблю, в моей работе часто приходится фитовать набор похожих спектров (например, температурную зависимость спектров для образца) и в Fityk можно взять результат фита для одного спектра и использовать его как начального приближение для фита другого спектра, это очень ускоряет работу и повышает качество фита большого массива данных.
3. Я так понял, что алгоритмы сглаживания и подгонки Вы писали сами?
Посмотрите на питоновскую библиотеку LMFIT, она хорошо реализует фит и имеет основные необходимые модели (Гаусс, Лоренц, различные осциляторы).
Для сглаживания можно использовать Savitzky-Golay filter, он есть в scipy библиотеке.
Я пробовал использовать для фита эти библиотеки, работал в jupyter notebook, там же можно и графики строить вполне себе такого же качества и сложности как в Origin.
Единственное, что неудобно в таком подходе — это задавать начальное приближение, даже при 10 линиях в спектре уже нужно записывать вручную минимум 30 параметров…
Мне кажется есть написать адекватный GUI к LMFIT, это будет самый удобный инструмент для фита.
Несколько комментариев:
1.
В замечательной программе OriginPro 8 мультифиттинг ограничен функциями Лоренца и Гаусса, что уже не плохо, но не достаточно.
В OriginPro много встроенных функций (около двух десятков, вот полный список) для фита в режиме Peak Analyzer. Другое дело, что для фита спектральных кривых не все из них подходят. Но можно добавить свою функцию. Я так в своё время определенный участок спектра аппроксимировал функцией связанных гармонических осцилляторов. Но конечно делать всё это в Origin так себе, долго и неэффективно.
2. Выше уже рекомендовали Fityk, это лучшая из программ для фита, которую я видел. Очень удобный графический интерфейс, легко задать первое приближение. Хотя сами алгоритмы оптимизации, мне кажется, работаю несколько хуже чем в Origin, часто не сходятся и приходится всё полностью подгонять руками. У Fityk есть одна «киллер фича», за которую я его особенно люблю, в моей работе часто приходится фитовать набор похожих спектров (например, температурную зависимость спектров для образца) и в Fityk можно взять результат фита для одного спектра и использовать его как начального приближение для фита другого спектра, это очень ускоряет работу и повышает качество фита большого массива данных.
3. Я так понял, что алгоритмы сглаживания и подгонки Вы писали сами?
Посмотрите на питоновскую библиотеку LMFIT, она хорошо реализует фит и имеет основные необходимые модели (Гаусс, Лоренц, различные осциляторы).
Для сглаживания можно использовать Savitzky-Golay filter, он есть в scipy библиотеке.
Я пробовал использовать для фита эти библиотеки, работал в jupyter notebook, там же можно и графики строить вполне себе такого же качества и сложности как в Origin.
Единственное, что неудобно в таком подходе — это задавать начальное приближение, даже при 10 линиях в спектре уже нужно записывать вручную минимум 30 параметров…
Мне кажется есть написать адекватный GUI к LMFIT, это будет самый удобный инструмент для фита.
Для сглаживания можно использовать Savitzky-Golay filter, он есть в scipy библиотеке.
Его настроить — замучаешься. Кроме того, пропусков данных быть не должно и шкала по оси Х равномерная нужна.
У Fityk есть одна «киллер фича», за которую я его особенно люблю, в моей работе часто приходится фитовать набор похожих спектров (например, температурную зависимость спектров для образца) и в Fityk можно взять результат фита для одного спектра и использовать его как начального приближение для фита другого спектра, это очень ускоряет работу и повышает качество фита большого массива данных.
В Ориджине аналогично.

Для фиттинга мне нравится TableCurve:
www.sigmaplot.co.uk/products/tablecurve2d/tablecurve2d.php
вдруг кто не знает.
Несколько тысяч вариантов аппроксимации сходу и возможность задавать свои функции.
www.sigmaplot.co.uk/products/tablecurve2d/tablecurve2d.php
вдруг кто не знает.
Несколько тысяч вариантов аппроксимации сходу и возможность задавать свои функции.
Мимо
Зарегистрируйтесь на Хабре, чтобы оставить комментарий
Мультифункциональный фиттинг экспериментальных данных