Комментарии 15
Я буду с нетерпением ждать следующих выходных :)
А что-нибудь коробочное принципиально не использовали? Написать CNN на том же TensorFlow тоже довольно интересно, полная гибкость и контроль, Python дает полный доступ к возможностям библиотеки — сказка!
Отчасти принципиально не использовал. С коробочными решениями есть одна проблема — прежде чем их использовать, мне нужно сначала понимать, что я хочу с ними сделать. Не являясь ни специалистом в машинном обучении, ни математиком, давно хотелось взять что-то совсем элементарное и покрутить в руках, что выявить все недостатки моего наивного подхода. А тут как раз наткнулся на хабре на перевод SLY_G.
Если бы машинное обучение было бы моей работой, то я бы так не делал. Наверное.
Кстати, здесь есть хорошая статья по TensorFlow, оставлю ссылку здесь.
Еще PyTorch.
Да что там, можно ничего другого не подключать, даже в OpenCV есть реализация нейронных сетей и глубокого обучения.
Если бы машинное обучение было бы моей работой, то я бы так не делал. Наверное.
Кстати, здесь есть хорошая статья по TensorFlow, оставлю ссылку здесь.
Еще PyTorch.
Да что там, можно ничего другого не подключать, даже в OpenCV есть реализация нейронных сетей и глубокого обучения.
Дополнительные слои редко дают выигрыш. Каждый лишний слой это лишняя стадия в распространении ошибки при обратном проходе(back propagation).
Гораздо лучших результатов можно добиться нормализацией входных значений. Но тут нужно постараться не потерять важное при нормализации.
Но изображения лучше всего обрабатывать сверточными сетями с предварительной тренировкой (энкодер) входных слоёв.
>Дополнительные слои редко дают выигрыш.
Ну если не ошибаюсь, то больше слоев — больше «выразительность» сети, т.е. больше возможностей уменьшить ошибку на train set. Так что дают, но этим выигрышем надо еще воспользоваться.
> с предварительной тренировкой (энкодер) входных слоёв.
Вроде как совсем необязательно. А вот предобученную на ImageNet сеть и правда есть смысл использовать.
Ну если не ошибаюсь, то больше слоев — больше «выразительность» сети, т.е. больше возможностей уменьшить ошибку на train set. Так что дают, но этим выигрышем надо еще воспользоваться.
> с предварительной тренировкой (энкодер) входных слоёв.
Вроде как совсем необязательно. А вот предобученную на ImageNet сеть и правда есть смысл использовать.
Более того, году так в 85-90 была доказана теорема что для любой многослойной сети существует функционально аналогичная сеть с одним внутренним слоем.
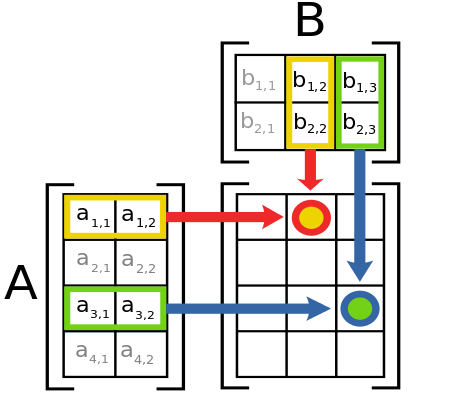
Эта теорема Хехт-Нильсена? По моему, она работает только для полносвязных сетей, где каждый нейрон скрытого слоя связан с каждым нейроном входного слоя, и также каждый с каждым между скрытым и выходным слоями. В рассматриваемой в статье сети это не так, потому что она использует матричное умножение, а в нем нейрон скрытого слоя связан лишь с одной строкой входной матрицы.
Схема умножения матриц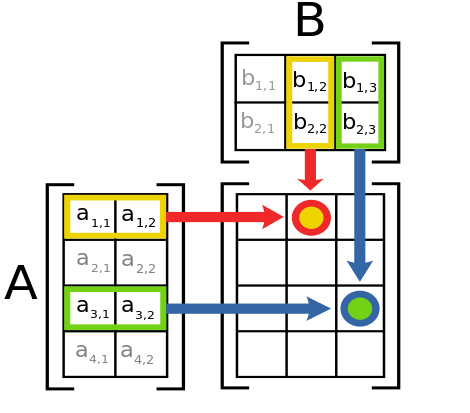
И да, размерность выхода вашей сети должна быт 1. Порог ,5 (но можно с ним поиграться). Оценка точности предсказания — просто по максимальным значениям. Ваш вариант с размерностью 4 просто размазывает результат на 4 значения, оценивать которые гораздо сложнее.
А если основное различие происходит на границах нарезанных кусочков матрицы, то получим неправильный результат?
НЛО прилетело и опубликовало эту надпись здесь
Спасибо за статью. Подскажите как исправить ошибку
ModuleNotFoundError: No module named 'meshandler'
meshandler — это модуль для вывода отладочных сообщений Qt. Его можно скачать, например, отсюда github.com/sshmakov/conopy/blob/master/conopy/meshandler.py
Или можно убрать строчку
Или можно убрать строчку
import meshandlerЗарегистрируйтесь на Хабре, чтобы оставить комментарий
Как отличать птиц от цветов. Или цветы от птиц