Канбан — методология управления, которая используется примерно в 10 раз реже, чем Scrum, но от этого не становится менее интересной. В ее основе лежит представление процесса всей организации, как набора взаимосвязанных сервисов, которые в конечном итоге являются сервисом для конечного потребителя.
Канбан особенно легко внедряется начиная с топ-менеджмента и прекрасно комбинируется с теорией ограничений, изложенной в книге «Цель» Элияху Голдрата. Канбан выбирают для себя отделы техподдержки, системные администраторы, и даже менеджеры по персоналу и бухгалтеры, тесно работающие с IT.
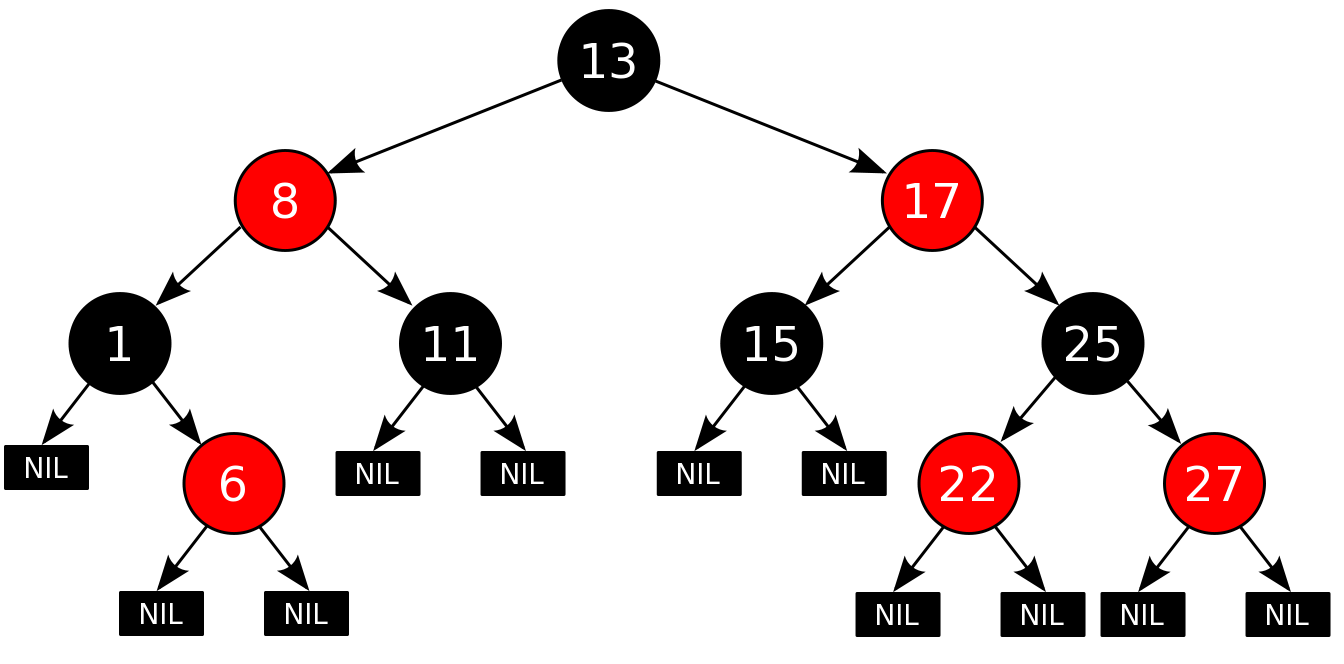
Одной из основных отличительных черт являются принципы внедрения Канбана: «Начните с того, что имеете, визуализируйте процесс, договоритесь об эволюционном изменении процессов».
Заметьте, что речь идет не о том, чтобы громогласно объявить о внедрении Канбана, а лишь о том, чтобы эволюционно менять процессы в сторону улучшения. Наверное, вы подумали: «Звучит не страшно. Кто же от такого откажется?». И тем не менее, добиться заметных результатов с точки зрения бизнеса без серьезных изменений не выйдет.
Следом за невинной фразой «давайте договоримся об эволюционном изменении процессов» может поступить много разных предложений. И если внедряющий Канбан достаточно опытен, это все пройдет весьма аккуратно. Ниже описаны выгоды, ради которых стоит внедрять канбан, и практики, которые можно использовать для улучшения процессов.
Никто не научит программистов программировать быстрее с помощью этих методов, естественно. Но большую часть времени задачи скорее лежат в очереди или блокируются по тем или иным причинам, а иногда просто оказываются забытыми в гуще недоделанных дел. С наведением порядка в задачах канбан справиться вполне может.
Выгоды внедрения
В наше время, когда интерес к слову Agile, мягко говоря, перегрет, ее может и не предполагаться изначально. Но все-таки, даже если это было затеяно с целью выполнить поручения, из внедрения все еще можно извлечь пользу.