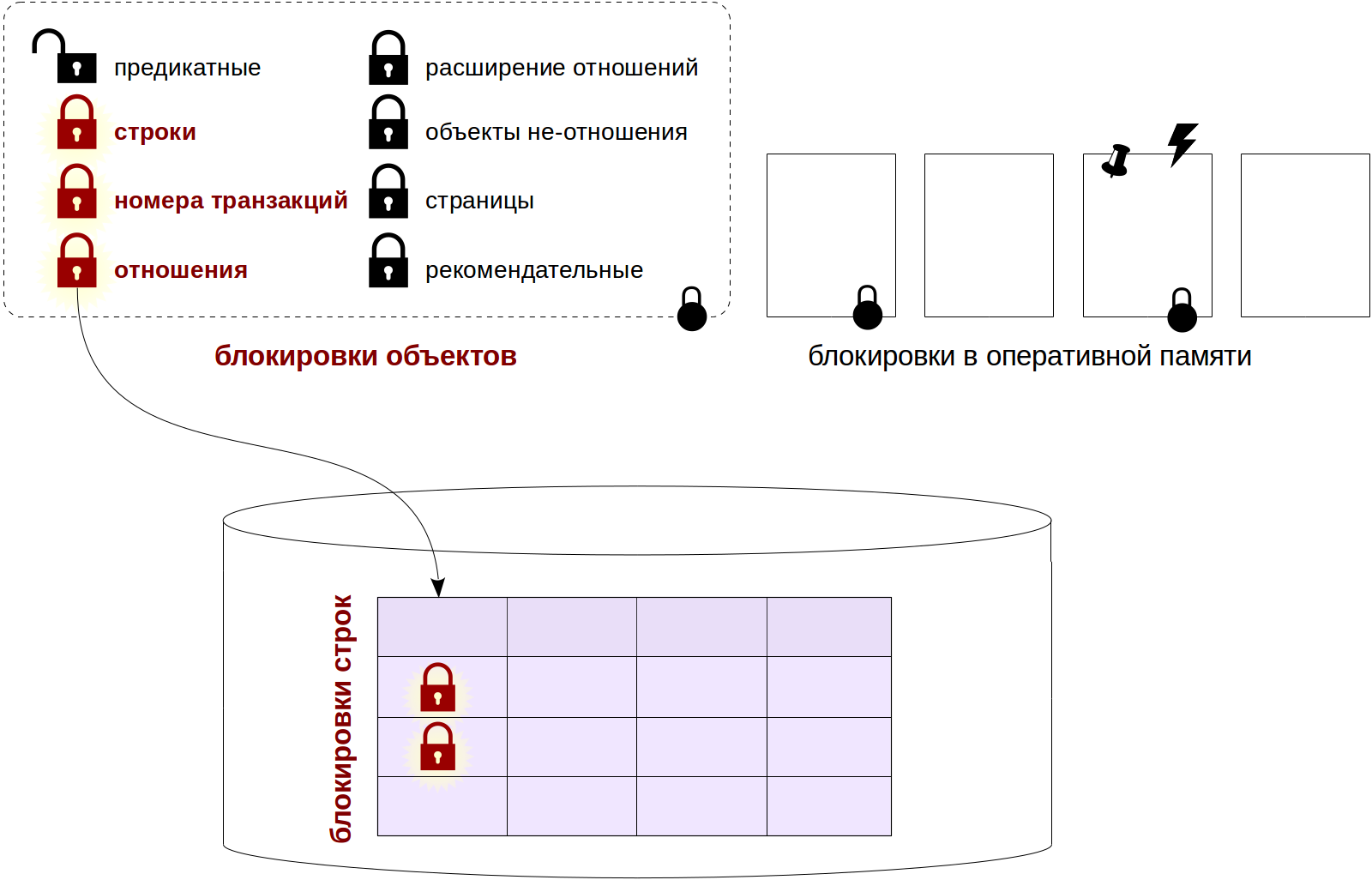
В прошлый раз мы говорили о блокировках на уровне объектов, в частности — о блокировках отношений. Сегодня посмотрим, как в PostgreSQL устроены блокировки строк и как они используются вместе с блокировками объектов, поговорим про очереди ожидания и про тех, кто лезет без очереди.
Напомню несколько важных выводов из прошлой статьи.
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.
Блокировки строк
Устройство
Напомню несколько важных выводов из прошлой статьи.
- Блокировка должна существовать где-то в разделяемой памяти сервера.
- Чем выше гранулярность блокировок, тем меньше конкуренция (contention) среди одновременно работающих процессов.
- С другой стороны, чем выше гранулярность, тем больше места в памяти занимают блокировки.
Нам безусловно хочется, чтобы изменение одной строки не приводило к блокировке других строк той же таблицы. Но и заводить на каждую строку по собственной блокировке мы не можем себе позволить.
Есть разные пути решения этой проблемы. В некоторых СУБД происходит повышение уровня блокировки: если блокировок уровня строк становится слишком много, они заменяются одной более общей блокировкой (например, уровня страницы или всей таблицы).
Как мы увидим позже, в PostgreSQL такой механизм тоже применяется, но только для предикатных блокировок. С блокировками строк дело обстоит иначе.