
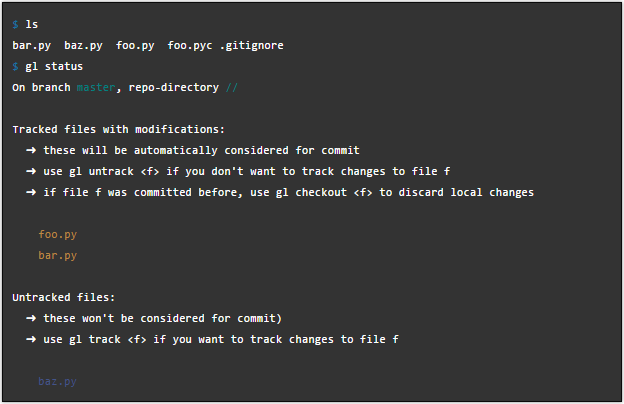
Все вы знаете систему Git. Хотя бы слышали — это наверняка. Разработчики, которые пользуются системой, ее или любят, или ругают за сложный интерфейс и баги. Система управления версиями Git де-факто является стандартом в индустрии. У разработчика могут быть мнения о преимуществах Mercurial, но чаще всего приходится мириться с требованием уметь пользоваться Git. Как у любой сложной системы, у нее множество полезных и необходимых функций. Однако, до гениальной простоты добираются не все, поэтому существующая реализация оставляла пространство для совершенствования.
Простыми словами — мудреным приложением было трудно пользоваться. Поэтому в лаборатории Массачусетского Технологического Института взялись за улучшения и отсекли все «проблемные элементы» (ведь то, что для одного проблема, для другого легко может быть преимуществом). Улучшенную и упрощенную версию назвали Gitless. Её разрабатывали с учетом 2400 вопросов, связанных с Git и взятых с сайта разработчиков StackOverflow.
Команда авторов вычленила самые проблемные места в Git, включая две концепции staging и stashing. Затем они предложили изменения, призванные решить известные проблемы.





 Я пообщался со спикером конференции
Я пообщался со спикером конференции 








