В контексте всеобщего хайпа на Коронавирусе, я решил сделать хоть что-нибудь полезное (но не менее хайповое). В данной статье я расскажу о том, как за 2.5 часа (именно столько у меня ушло) создать и развернуть Telegram Бота с использованием Rule-Based NLP методов, отвечающего на FAQ-вопросы на примере с кейсом COVID-19.
В ходе работы, мы будем использовать старый добрый Python, Telegram API, пару стандартных NLP-библиотек, а также Docker.

В данной статье описан процесс создания простого Telegram Бота отвечающего на FAQ вопросы по COVID-19. Технология разработки крайне проста и универсальна, и может использоваться для любых других кейсов. Ещё раз подчеркну, что я не претендую на State of the Art, а лишь предлагаю простое и эффективное решение, которое можно переиспользовать.
Поскольку я полагаю, что читатель данной статьи уже имеет некоторый опыт работы с Python, будем считать, что у вас уже установлен Python 3.X и необходимые средства разработки (PyCharm, VS Code), вы умеете создавать Бота в Telegram через BotFather, а по сему, пропущу эти вещи.
Первое, что вам необходимо установить, это библиотеку-обёртку для Telegram API "python-telegram-bot". Стандартная команда для этого:
Далее, построим каркас нашей небольшой программы, определив «хэндлеры» для следующих событий Бота:
Сигнатура обработчиков будет выглядеть следующим образом:
Далее, по аналогии с примером из документации библиотеки, определим главную функцию, в которой назначим все эти обработчики и будем запускать бота:
Обращаю ваше внимание на том, что есть 2 механизма, как запустить бота:
Как вы уже заметили, для простоты мы используем стандартный Polling.
Начнём с простого, заполним обработчики start и help стандартными ответами, получается что-то вроде этого:
Теперь, при отправке пользователем команд /start или /help — им будет получен ответ, прописанный нами. Обращаю ваше внимание на том, что текст форматирован в Markdown
Далее, добавим в обработчик error логгирование ошибки:
Теперь, проверим, работает ли наш Бот. Скопируйте весь написанный код в один файл, например app.py. Добавьте необходимые import'ы.
Запускаем файл и переходим в Telegram (не забудьте вставить свой Token в код). Пишем команды /start и /help и радуемся:
Первое, что нам нужно для ответов на вопрос — это «База знаний». Самое простое, что можно сделать это создать простенький json-файл в виде Key-Value значений, где Key — это текст предполагаемого вопроса, а Value — ответ на вопрос. Пример базы знаний:
Алгоритм ответа на вопрос будет следующий:
Для реализации наших планов, нам понадобятся библиотеки: fuzzywuzzy (для нечеткого сравнения) и pymorphy2 (для лемматизации).
Создадим новый файл и имплиментируем озвученный алгоритм:
Прежде чем как писать обработчик message, напишем функцию, которая сохраняет историю переписки в tsv файл:
Теперь, используем написанный нами метод в обработчике текстового сообщения message:
Вуаля, теперь переходим в Telegram и радуемся написанному:
Как говорил классик: «Если исполнять, то исполнять красиво.», так вот, чтобы у нас всё было как у людей, настроим контейнеризацию с использованием Docker Compose.
Для этого нам нужно:
Итак, содержание Dockerfile:
Содержание docker-compose.yml:
Содержание boot.sh:
Итак, мы готовы, для того, чтобы всё это запустить необходимо выполнить следующие команды в папке проекта:
Всё, наш бот готов.
Как и полагается, весь код доступен в репозитории.
Данный подход, показанный мной, может быть применен в любом кейсе для ответов на FAQ вопросы, просто кастомизируйте базу знаний! Касаемо базы знаний, её тоже можно улучшить изменив структуру Key и Value на массивы, таким образом, каждая пара будет представлять собой массив потенциальных вопросов на одну тему и массив потенциальных ответов на них (для разнообразия ответы можно выбирать случайным образом). Естественно, Rule-Based подход не слишком гибок к масштабированию, однако я уверен, что этот подход выдержит базу знаний с порядка 500-ми вопросами.
Тех, кто дочитал до конца приглашаю опробовать моего Бота по ссылке.
В ходе работы, мы будем использовать старый добрый Python, Telegram API, пару стандартных NLP-библиотек, а также Docker.
Минутка заботы от НЛО
В мире официально объявлена пандемия COVID-19 — потенциально тяжёлой острой респираторной инфекции, вызываемой коронавирусом SARS-CoV-2 (2019-nCoV). На Хабре много информации по этой теме — всегда помните о том, что она может быть как достоверной/полезной, так и наоборот.
Мы призываем вас критично относиться к любой публикуемой информации
Официальные источники
- Cайт Министерства здравоохранения РФ
- Cайт Роспотребнадзора
- Сайт ВОЗ (англ)
- Сайт ВОЗ
- Сайты и официальные группы оперативных штабов в регионах
Если вы проживаете не в России, обратитесь к аналогичным сайтам вашей страны.
Мойте руки, берегите близких, по возможности оставайтесь дома и работайте удалённо.
Читать публикации про: коронавирус | удалённую работу
Краткое предисловие
В данной статье описан процесс создания простого Telegram Бота отвечающего на FAQ вопросы по COVID-19. Технология разработки крайне проста и универсальна, и может использоваться для любых других кейсов. Ещё раз подчеркну, что я не претендую на State of the Art, а лишь предлагаю простое и эффективное решение, которое можно переиспользовать.
Поскольку я полагаю, что читатель данной статьи уже имеет некоторый опыт работы с Python, будем считать, что у вас уже установлен Python 3.X и необходимые средства разработки (PyCharm, VS Code), вы умеете создавать Бота в Telegram через BotFather, а по сему, пропущу эти вещи.
1. Настраиваем API
Первое, что вам необходимо установить, это библиотеку-обёртку для Telegram API "python-telegram-bot". Стандартная команда для этого:
pip install python-telegram-bot --upgradeДалее, построим каркас нашей небольшой программы, определив «хэндлеры» для следующих событий Бота:
- start — команда запуска Бота;
- help — команда помощи (справка);
- message — обработка текстового сообщения;
- error — ошибка.
Сигнатура обработчиков будет выглядеть следующим образом:
def start(update, context):
#обработка команды запуска бота
pass
def help(update, context):
#обработка команды помощи
pass
def message(update, context):
#обработка текстового сообщения
pass
def error(update, context):
#обработка ошибки
passДалее, по аналогии с примером из документации библиотеки, определим главную функцию, в которой назначим все эти обработчики и будем запускать бота:
def get_answer():
"""Start the bot."""
# Create the Updater and pass it your bot's token.
# Make sure to set use_context=True to use the new context based callbacks
# Post version 12 this will no longer be necessary
updater = Updater("Token", use_context=True)
# Get the dispatcher to register handlers
dp = updater.dispatcher
# on different commands - answer in Telegram
dp.add_handler(CommandHandler("start", start))
dp.add_handler(CommandHandler("help", help))
# on noncommand i.e message - echo the message on Telegram
dp.add_handler(MessageHandler(Filters.text, message))
# log all errors
dp.add_error_handler(error)
# Start the Bot
updater.start_polling()
# Run the bot until you press Ctrl-C or the process receives SIGINT,
# SIGTERM or SIGABRT. This should be used most of the time, since
# start_polling() is non-blocking and will stop the bot gracefully.
updater.idle()
if __name__ == "__main__":
get_answer()Обращаю ваше внимание на том, что есть 2 механизма, как запустить бота:
- Стандартный Polling — периодический опрос Бота стандартными средствами Telegram API на наличие новых событий (
updater.start_polling()); - Webhook — запускаем свой сервер с endpoint'ом, на который приходят события из бота, требует HTTPS.
Как вы уже заметили, для простоты мы используем стандартный Polling.
2. Наполняем стандартные обработчики логикой
Начнём с простого, заполним обработчики start и help стандартными ответами, получается что-то вроде этого:
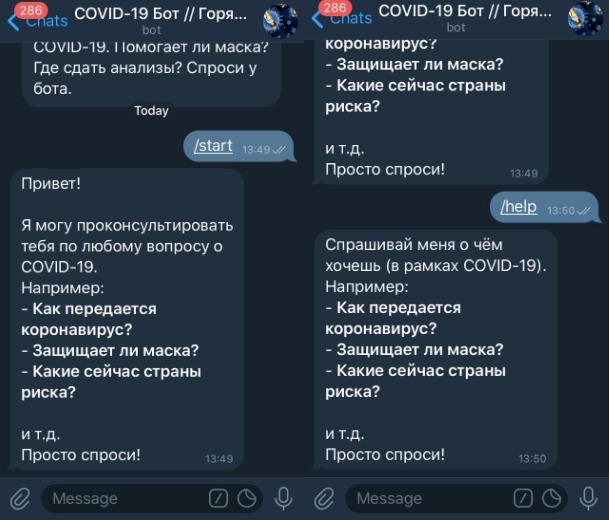
def start(update, context):
"""Send a message when the command /start is issued."""
update.message.reply_text("""
Привет!
Я могу проконсультировать тебя по любому вопросу о COVID-19.
Например:
- *Как передается коронавирус?*
- *Защищает ли маска?*
- *Какие сейчас страны риска?*
и т.д.
Просто спроси!
""", parse_mode=telegram.ParseMode.MARKDOWN)
def help(update, context):
"""Send a message when the command /help is issued."""
update.message.reply_text("""
Спрашивай меня о чём хочешь (в рамках COVID-19).
Например:
- *Как передается коронавирус?*
- *Защищает ли маска?*
- *Какие сейчас страны риска?*
и т.д.
Просто спроси!
""", parse_mode=telegram.ParseMode.MARKDOWN)Теперь, при отправке пользователем команд /start или /help — им будет получен ответ, прописанный нами. Обращаю ваше внимание на том, что текст форматирован в Markdown
parse_mode=telegram.ParseMode.MARKDOWNДалее, добавим в обработчик error логгирование ошибки:
def error(update, context):
"""Log Errors caused by Updates."""
logger.warning('Update "%s" caused error "%s"', update, context.error)Теперь, проверим, работает ли наш Бот. Скопируйте весь написанный код в один файл, например app.py. Добавьте необходимые import'ы.
Запускаем файл и переходим в Telegram (не забудьте вставить свой Token в код). Пишем команды /start и /help и радуемся:

3. Обрабатываем сообщение и генерируем ответ
Первое, что нам нужно для ответов на вопрос — это «База знаний». Самое простое, что можно сделать это создать простенький json-файл в виде Key-Value значений, где Key — это текст предполагаемого вопроса, а Value — ответ на вопрос. Пример базы знаний:
{
"Что такое коронавирус и как происходит заражение?": "Новый коронавирус — респираторный вирус. Он передается главным образом воздушно-капельным путем в результате вдыхания капель, выделяемых из дыхательных путей больного, например при кашле или чихании, а также капель слюны или выделений из носа. Также он может распространяться, когда больной касается любой загрязненной поверхности, например дверной ручки. В этом случае заражение происходит при касании рта, носа или глаз грязными руками.",
"Какие симптомы у коронавируса?": "Основные симптомы коронавируса:\n Повышенная температура\n Чихание\n Кашель\n Затрудненное дыхание\n\nВ подавляющем большинстве случаев данные симптомы связаны не с коронавирусом, а с обычной ОРВИ.",
"Как передается коронавирус?": "Пути передачи:\nВоздушно-капельный (выделение вируса происходит при кашле, чихании, разговоре)\nКонтактно-бытовой (через предметы обихода)",
}Алгоритм ответа на вопрос будет следующий:
- Получаем текст вопроса от пользователя;
- Лемматизируем все слова в тексте пользователя;
- Нечётко сравниваем полученный текст со всеми лемматизированными вопросами из базы знаний (расстояние Левенштейна);
- Выбираем наиболее «похожий» вопрос из базы знаний;
- Отправляем ответ на выбранный вопрос пользователю.
Для реализации наших планов, нам понадобятся библиотеки: fuzzywuzzy (для нечеткого сравнения) и pymorphy2 (для лемматизации).
Создадим новый файл и имплиментируем озвученный алгоритм:
import json
from fuzzywuzzy import fuzz
import pymorphy2
#создание объекта морфологического анализатора
morph = pymorphy2.MorphAnalyzer()
#загрузка базы знаний
with open("faq.json") as json_file:
faq = json.load(json_file)
def classify_question(text):
#лемматизация текста юзера
text = ' '.join(morph.parse(word)[0].normal_form for word in text.split())
questions = list(faq.keys())
scores = list()
#цикл по всем вопросам из базы знаний
for question in questions:
#лемматизация вопроса из базы знаний
norm_question = ' '.join(morph.parse(word)[0].normal_form for word in question.split())
#сравнение вопроса юзера и вопроса из базы знаний
scores.append(fuzz.token_sort_ratio(norm_question.lower(), text.lower()))
#получение ответа
answer = faq[questions[scores.index(max(scores))]]
return answerПрежде чем как писать обработчик message, напишем функцию, которая сохраняет историю переписки в tsv файл:
def dump_data(user, question, answer):
username = user.username
full_name = user.full_name
id = user.id
str = """{username}\t{full_name}\t{id}\t{question}\t{answer}\n""".format(username=username,
full_name=full_name,
id=id,
question=question,
answer=answer)
with open("/data/dump.tsv", "a") as myfile:
myfile.write(str)Теперь, используем написанный нами метод в обработчике текстового сообщения message:
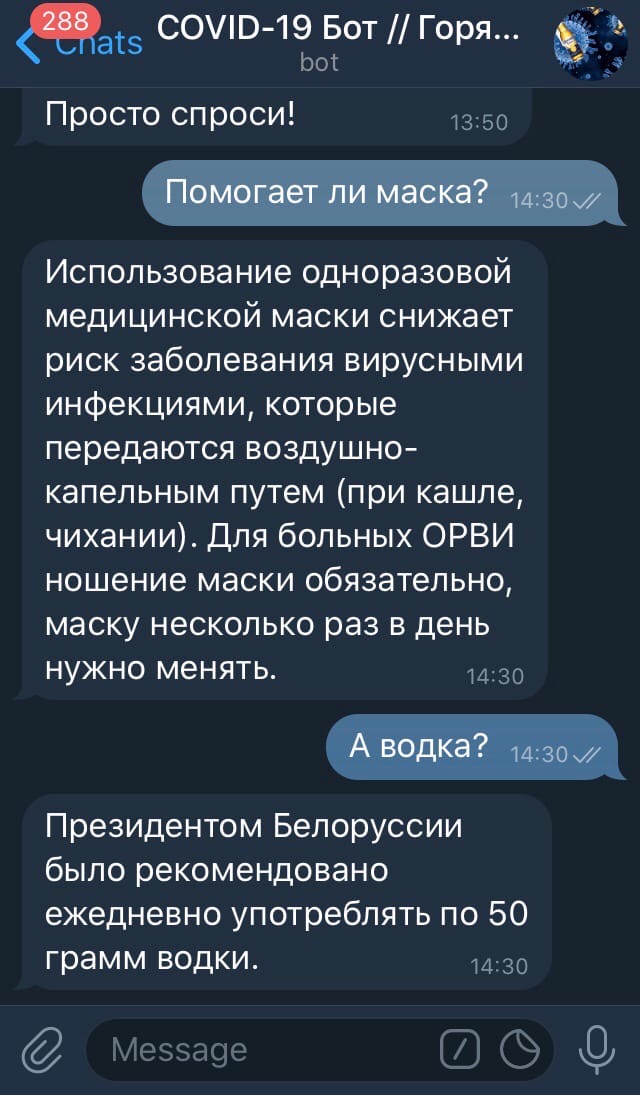
def message(update, context):
"""Answer the user message."""
#получение ответа
answer = classify_question(update.message.text)
#сохранение в файл
dump_data(update.message.from_user, update.message.text, answer)
#отправка сообщения
update.message.reply_text(answer)Вуаля, теперь переходим в Telegram и радуемся написанному:

4. Настраиваем Docker и разворачиваем приложение
Как говорил классик: «Если исполнять, то исполнять красиво.», так вот, чтобы у нас всё было как у людей, настроим контейнеризацию с использованием Docker Compose.
Для этого нам нужно:
- Создать Dockerfile — определяет образ контейнера и входную точку;
- Создать docker-compose.yml — запускает множество контейнеров используя единый Dockerfile (в нашем случае не нужно, но в случае, если у вас много сервисов, то будет полезно.)
- Создать boot.sh (скрипт отвечающий непосредственно за запуск).
Итак, содержание Dockerfile:
#образ
FROM python:3.6.6-slim
#название рабочей директории
WORKDIR /home/alex/covid-bot
#копируем файл requirements.txt
COPY requirements.txt ./
# Install required libs
RUN pip install --upgrade pip -r requirements.txt; exit 0
#копируем папку в которой будут наши данные
COPY data data
# Копирование файлов проекта
COPY app.py faq.json reply_generator.py boot.sh ./
# На всякий пожарный
RUN apt-get clean && rm -rf /var/lib/apt/lists/* /tmp/* /var/tmp/*
#раздаём права
RUN chmod +x boot.sh
#указываем входную точку
ENTRYPOINT ["./boot.sh"]Содержание docker-compose.yml:
#версия docker-compose
version: '2'
#список запускаемых сервисов
services:
bot:
restart: unless-stopped
image: covid19_rus_bot:latest
container_name: covid19_rus_bot
#задаём переменную среды для boot.sh
environment:
- SERVICE_TYPE=covid19_rus_bot
#пробрасываем volume для доступа к папке с данными
volumes:
- ./data:/data
Содержание boot.sh:
#!/bin/bash
if [ -n $SERVICE_TYPE ]
then
if [ $SERVICE_TYPE == "covid19_rus_bot" ]
then
exec python app.py
exit
fi
else
echo -e "SERVICE_TYPE not set\n"
fiИтак, мы готовы, для того, чтобы всё это запустить необходимо выполнить следующие команды в папке проекта:
sudo docker build -t covid19_rus_bot:latest .
sudo docker-compose upВсё, наш бот готов.
Вместо заключения
Как и полагается, весь код доступен в репозитории.
Данный подход, показанный мной, может быть применен в любом кейсе для ответов на FAQ вопросы, просто кастомизируйте базу знаний! Касаемо базы знаний, её тоже можно улучшить изменив структуру Key и Value на массивы, таким образом, каждая пара будет представлять собой массив потенциальных вопросов на одну тему и массив потенциальных ответов на них (для разнообразия ответы можно выбирать случайным образом). Естественно, Rule-Based подход не слишком гибок к масштабированию, однако я уверен, что этот подход выдержит базу знаний с порядка 500-ми вопросами.
Тех, кто дочитал до конца приглашаю опробовать моего Бота по ссылке.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Надоел ли уже контент связанный с COVID-19?
57.5% Да23
12.5% Нет5
30% Да, но статья была полезной!12
Проголосовали 40 пользователей. Воздержались 5 пользователей.














