Всем привет! Разбираясь со Spark Apache, столкнулся с тем, что после достаточно небольшого усложнения алгоритмов подготовки данных расчеты стали выполняться крайне медленно. Поэтому захотелось реализовать что-нибудь на C# и сравнить производительность с аналогичным по классу решением на стеке python (pandas-numpy-skilearn). Аналогичным, потому что они выполняются на локальной машине. Подготовка данных на C# осуществлялась встроенными средствами (linq), расчет линейной регрессии библиотекой extremeoptimization.
В качестве тестовой использовалась задача «B. Предсказание трат клиентов» с ноябрьского соревнования Sberbank Data Science Journey.
Сразу стоит подчеркнуть, что в данной статье описан исключительно аспект сравнения производительности платформ, а не качества модели и предсказаний.
Итак, сначала краткое описание последовательности действий реализованных на C# (куски кода будут ниже):
1. Загрузить данные из csv. Использовалась библиотека Fast Csv Reader.
2. Отфильтровать расходные операции и выполнить группировку по месяцам.
3. Добавить каждому клиенту те категории, по которым у него не было операций. Для того, чтобы избежать длительный перебор цикл-в-цикле использовал фильтр Блума. Реализацию на C# нашел тут.
4. Формирование массива Hashing trick. Так как готовой реализации под C# не удалось найти, пришлось реализовать самому. Для этого скачал и допилил реализацию хеширования murmurhash3
5. Собственно расчет регрессии.
Решение на Jupyter Notebook (далее JN) выглядит так (подключение библиотек опускаю, потому что это не входило в замеряемое время):
Теперь подробнее о реализации C#. Опыты показали, что классы типа DataTable и прочие очень расточительны по отношению к памяти. Поэтому использовался простой список элементов класса Client:
Далее, чтение данных и группировка:
Затем добавляем отсутствующие типы операций, используя фильтр Блума. Можно было бы и без него, но тогда бы увеличилось время выполнения (полный перебор для каждого типа) или объем используемой памяти (если добавлять все типы подряд, а потом агрегировать).
Этап добавления операций за предыдущие месяцы:
Далее заполнение массива hashing trick и подготовка данных в формате понятном модели и собственно расчет
Ну и наконец реализация Hashing trick:
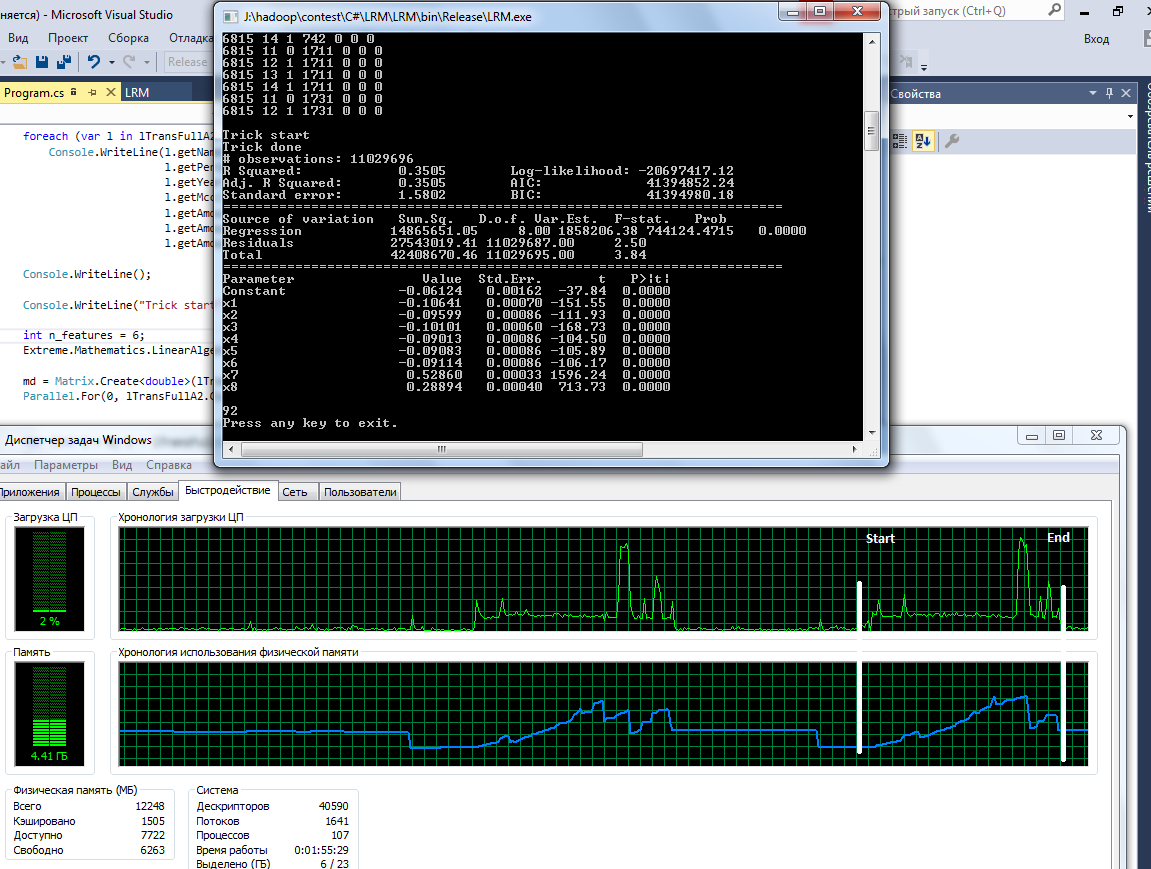
Результаты работы программ практически идентичны (RMSLE около 1.6). Вот как это выглядит:
Теперь переходим к самому интересному — результатам тестирования. Все тесты запускались на i7-2600 (8 потоков, но большую часть времени работало 1-2). Оперативной памяти 12 Гб, ОС Win7.
Для выяснения зависимости времени выполнения от объема данных расчеты запускались на 1.7, 3.4, 5,1 и 6.8 млн. исходных записей (содержимое файла transactions.csv). Но так как в ходе подготовки данных происходила фильтрация за 11-14 месяцы, на графике показано количество данных уже после фильтрации.
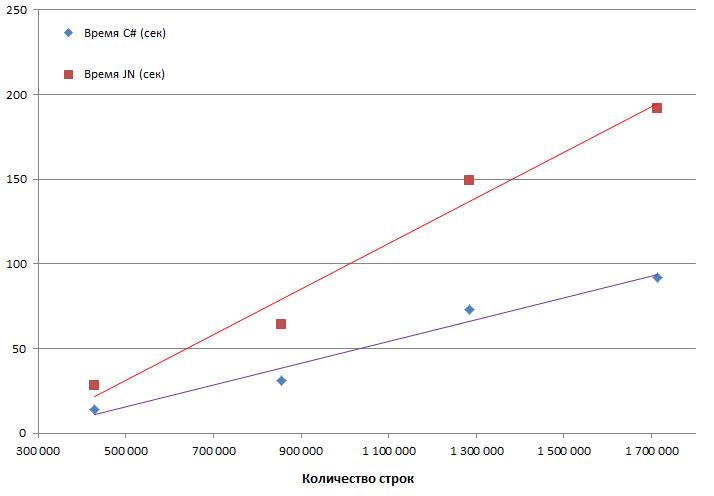
Как видно, версия на C# приблизительно в 2 раза быстрее. Похожая ситуация и с расходом памяти. Тут не учитывается память занимаемая Visual Studio (C# запускался в режиме отладки) и браузером (localhost:8888). Для оценки бралось пиковое значение:
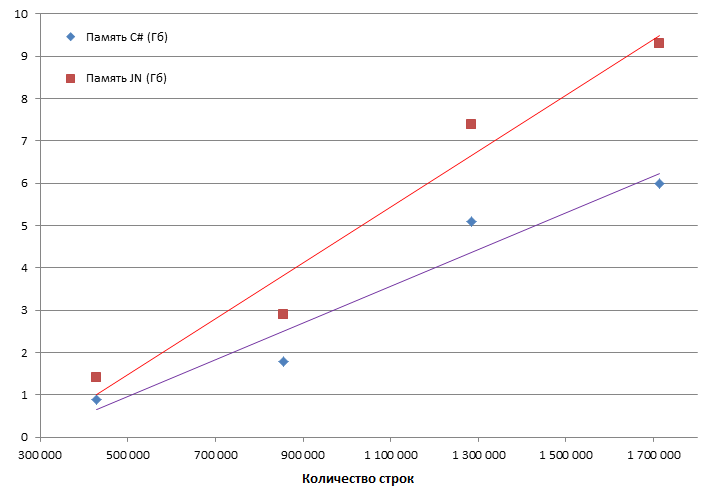
При дальнейшем увеличении выборки JN уже начинал использовать файл подкачки, в результате чего все резко замедлялось.
Таким образом, мы видим, что использование C# позволяет существенно быстрее обработать больший объем данных, чем JN, так как оперативная память выступает тут жестким ограничителем.
С другой стороны, средства визуализации matplotlib позволяют анализировать данные почти «на лету», да и кода C# требуется писать гораздо больше. Поэтому в случае нехватки памяти/скорости оптимальным вариантом видится использование стека JN для отладки модели на ограниченной выборке и финальная реализация уже на C#.
В качестве тестовой использовалась задача «B. Предсказание трат клиентов» с ноябрьского соревнования Sberbank Data Science Journey.
Сразу стоит подчеркнуть, что в данной статье описан исключительно аспект сравнения производительности платформ, а не качества модели и предсказаний.
Итак, сначала краткое описание последовательности действий реализованных на C# (куски кода будут ниже):
1. Загрузить данные из csv. Использовалась библиотека Fast Csv Reader.
2. Отфильтровать расходные операции и выполнить группировку по месяцам.
3. Добавить каждому клиенту те категории, по которым у него не было операций. Для того, чтобы избежать длительный перебор цикл-в-цикле использовал фильтр Блума. Реализацию на C# нашел тут.
4. Формирование массива Hashing trick. Так как готовой реализации под C# не удалось найти, пришлось реализовать самому. Для этого скачал и допилил реализацию хеширования murmurhash3
5. Собственно расчет регрессии.
Решение на Jupyter Notebook (далее JN) выглядит так (подключение библиотек опускаю, потому что это не входило в замеряемое время):
%%time
#Читаем файл с исходными данными по транзакциям
transactions = pd.read_csv('.//JN//SBSJ//transactions.csv')
all_cuses = transactions.customer_id.unique()
#Читаем файл с типами операций
mcc = pd.read_csv('.//JN//SBSJ//tr_mcc_codes.csv', sep=';')
all_mcc = mcc.mcc_code.unique()
#Фильтрация расходных транзакций
transactions = transactions[transactions.amount < 0].copy()
transactions['day'] = transactions.tr_day.apply(lambda dt: dt.split()[0]).astype(int)
transactions.day += 29 - transactions['day'].max()%30
#Преобразование дней в месяцы
transactions['month_num'] = (transactions.day) // 30
train_transactions = transactions[transactions.month_num < 15]
#Добавление отсутствующих типов операций и фильтрация нескольких последних месяцев (на полной выборке не хватало памяти)
grid = list(product(*[all_cuses, all_mcc, range(11, 15)]))
train_grid = pd.DataFrame(grid, columns = ['customer_id', 'mcc_code', 'month_num'])
train = pd.merge(train_grid,
train_transactions.groupby(['month_num', 'customer_id', 'mcc_code'])[['amount']].sum().reset_index(),
how='left').fillna(0)
#Добавление информации о расходах в предыдущих месяцах
for month_shift in range(1, 3):
train_shift = train.copy()
train_shift['month_num'] = train_shift['month_num'] + month_shift
train_shift = train_shift.rename(columns={"amount" : 'amount_{0}'.format(month_shift)})
train_shift = train_shift[['month_num', 'customer_id', 'mcc_code', 'amount_{0}'.format(month_shift)]]
train = pd.merge(train, train_shift, on=['month_num', 'customer_id', 'mcc_code'], how='left').fillna(0)
train['year_num'] = (train.month_num) // 12
#Создание массива hashier trick
hasher = FeatureHasher(n_features=6, input_type='string')
train_sparse = \
hasher.fit_transform(train[['year_num', 'month_num', 'customer_id', 'mcc_code']].astype(str).as_matrix())
train_sparse2 = sparse.hstack([train_sparse, np.log(np.abs(train[['amount_1', 'amount_2']]) + 1).as_matrix(),])
#Без этого хинта расчет регрессии не корректен
d = list(train_sparse2.toarray())
#Собственно расчет
clf = LinearRegression()
clf.fit(d, np.log(np.abs(train['amount']) + 1))
#Результаты
print('Coefficients: \n', clf.coef_)
print('Intercept: \n', clf.intercept_)
print("\nRMSLE: ")
np.sqrt(mse(np.log(np.abs(train['amount']) + 1),clf.predict(d)))Теперь подробнее о реализации C#. Опыты показали, что классы типа DataTable и прочие очень расточительны по отношению к памяти. Поэтому использовался простой список элементов класса Client:
[Serializable]
public class Client
{
private Int32 name;
private Int16 period;
private Int16 year;
private Int16 mcc;
private double amount;
private double amount1;
private double amount2;
// Методы get/set
...
Далее, чтение данных и группировка:
// Группируем расходные транзакции
List<Client> lTransGrouped = lClientsTrans.AsParallel()
.Where(row => row.getAmount() < 0)
.GroupBy(row => new
{
month = (row.getPeriod() + 29 - Convert.ToInt16(maxNumDay) % 30) / 30, // Преобразуем дни в месяцы
mcc = row.getMcc(),
cid = row.getName()
})
.Select(grp => new Client(
grp.Key.cid,
Convert.ToInt16(grp.Key.month),
grp.Key.mcc,
Math.Log(Math.Abs(grp.Sum(r => r.getAmount())) + 1))).ToList();
lClientsTrans = null;Затем добавляем отсутствующие типы операций, используя фильтр Блума. Можно было бы и без него, но тогда бы увеличилось время выполнения (полный перебор для каждого типа) или объем используемой памяти (если добавлять все типы подряд, а потом агрегировать).
public static List<Client> addPeriodMcc(List<Client> lTransGrouped, Int16 maxNumMon)
{
List<Client> lMcc = new List<Client>();
string fnameMcc = @"j:\hadoop\Contest\Contest\tr_mcc_codes.csv";
// Читаем mcc_code
CsvReader csvMccReader = new CsvReader(new StreamReader(fnameMcc), true, ';');
// Читаем типы операций
while (csvMccReader.ReadNextRecord())
{
Int16 mcc = Convert.ToInt16(csvMccReader[0]);
lMcc.Add(new Client(0, 0, mcc, 0));
}
// Готовим таблицу для массива mcc под все записи
List<Client> lNewMcc = new List<Client>();
// Для генерации отсутствующих записей нужно знать ID клиентов
var lTransCID = lTransGrouped.AsParallel().Select(a => a.getName()).Distinct();
Console.WriteLine("Unique CID: " + lTransCID.Count());
// Задаем мощность фильтра
int capacity = lTransGrouped.Count() * 6; // Чем больше множитель, тем меньше вероятность промахнуться
var filter = new Filter<string>(capacity); //Собственно сам фильтр
// Заполнение фильтра
foreach (var i in lTransGrouped)
filter.Add(i.getName().ToString() + i.getPeriod() + i.getMcc());
// Если записи у клиента нет операции в фильтре, то добавляем
foreach (var cid in lTransCID)
for (Int16 m = 0; m <= maxNumMon; m++)
foreach (var mcc in lMcc)
if (filter.Contains(cid.ToString() + m.ToString() + mcc.getMcc().ToString()) != true)
lNewMcc.Add(new Client(cid, m, mcc.getMcc(), 0));
lTransCID = lMcc = null;
Console.WriteLine("Count lNewMcc: " + lNewMcc.Count);
Console.WriteLine("Count lTransGrouped: " + lTransGrouped.Count);
// Объединение
List<Client> lTransFull = lNewMcc.Union(lTransGrouped).ToList();
Console.WriteLine("Count lTransFull: " + lTransFull.Count);
lTransGrouped = lNewMcc = null;
return lTransFull;
}Этап добавления операций за предыдущие месяцы:
public static List<Client> addAmounts(List<Client> lTransFull)
{
List<Client> lTransFullA2;
// Для корректного добавления значений предыдущих месяцев нужно отсортировать
lTransFullA2 = lTransFull.OrderBy(a => a.getName())
.ThenBy(a => a.getMcc())
.ThenBy(a => a.getYear())
.ThenBy(a => a.getPeriod()).ToList();
int name = 0;
int month = 0;
int year = 0;
int mcc = 0;
int i = 0;
foreach (var l in lTransFullA2)
{
name = l.getName();
mcc = l.getMcc();
year = l.getYear();
month = l.getPeriod();
// Предыдущий месяц
if (i > 0 && name == lTransFullA2[i - 1].getName() &&
mcc == lTransFullA2[i - 1].getMcc() &&
year == lTransFullA2[i - 1].getYear() &&
month == lTransFullA2[i - 1].getPeriod() + 1)
{
l.setAmount1(lTransFullA2[i - 1].getAmount());
}
// Позапрошлый месяц
if (i > 1 && name == lTransFullA2[i - 2].getName() &&
mcc == lTransFullA2[i - 2].getMcc() &&
year == lTransFullA2[i - 2].getYear() &&
month == lTransFullA2[i - 2].getPeriod() + 2)
{
l.setAmount2(lTransFullA2[i - 2].getAmount());
}
i++;
}
return lTransFullA2;
}Далее заполнение массива hashing trick и подготовка данных в формате понятном модели и собственно расчет
int n_features = 6;
// Вектор зависимых переменных
Extreme.Mathematics.LinearAlgebra.SparseVector<double> v = Vector.CreateSparse<double>(lTransFullA2.Count);
// Массив независимых (hash + расходы предыдущих месяцев)
md = Matrix.Create<double>(lTransFullA2.Count, n_features + 2);
// Формирование Hashing trick
Parallel.For(0, lTransFullA2.Count(), i => hashing_vectorizer(lTransFullA2[i], i, n_features));
for (int i = 0; i < lTransFullA2.Count; i++)
{
md[i, n_features] = lTransFullA2[i].getAmount1();
md[i, n_features + 1] = lTransFullA2[i].getAmount2();
v.AddAt(i, lTransFullA2[i].getAmount());
}
lTransFullA2 = null;
GC.Collect(2, GCCollectionMode.Forced);
var model = new LinearRegressionModel(v, md); // Формирование модели
model.MaxDegreeOfParallelism = 8;
model.Compute(); // Расчет
Console.WriteLine(model.Summarize()); // Вывод рассчитанных значений
GC.Collect(2, GCCollectionMode.Forced);
Ну и наконец реализация Hashing trick:
public static void hashing_vectorizer(Client f, int i, int n)
{
int[] x = new int[n];
string s = f.getYear().ToString(); //
int idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i,idx] = x[idx];
s = f.getPeriod().ToString();
idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i, idx] = x[idx];
s = f.getName().ToString();
idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i, idx] = x[idx];
s = f.getMcc().ToString();
idx = getIndx(s, n);
x[idx] += calcBit(s);
md[i, idx] = x[idx];
}
// Хэширование для выяснения знака
public static int calcBit(string s)
{
byte b = 0;
b = Convert.ToByte(s[0]);
for (int i = 1; i < s.Count(); i++)
b ^= Convert.ToByte(s[0]);
bool result = true;
while (b >= 1)
{
result ^= (b & 0x01) != 0;
b = Convert.ToByte(b >> 1);
}
if (result)
return -1;
else
return 1;
}
public static int getIndx(string str, int n)
{
Encoding encoding = new UTF8Encoding();
byte[] input = encoding.GetBytes(str);
uint h = MurMurHash3.Hash(input);
return Convert.ToInt32(h % n);
}Результаты работы программ практически идентичны (RMSLE около 1.6). Вот как это выглядит:

Теперь переходим к самому интересному — результатам тестирования. Все тесты запускались на i7-2600 (8 потоков, но большую часть времени работало 1-2). Оперативной памяти 12 Гб, ОС Win7.
Для выяснения зависимости времени выполнения от объема данных расчеты запускались на 1.7, 3.4, 5,1 и 6.8 млн. исходных записей (содержимое файла transactions.csv). Но так как в ходе подготовки данных происходила фильтрация за 11-14 месяцы, на графике показано количество данных уже после фильтрации.

Как видно, версия на C# приблизительно в 2 раза быстрее. Похожая ситуация и с расходом памяти. Тут не учитывается память занимаемая Visual Studio (C# запускался в режиме отладки) и браузером (localhost:8888). Для оценки бралось пиковое значение:

При дальнейшем увеличении выборки JN уже начинал использовать файл подкачки, в результате чего все резко замедлялось.
Таким образом, мы видим, что использование C# позволяет существенно быстрее обработать больший объем данных, чем JN, так как оперативная память выступает тут жестким ограничителем.
С другой стороны, средства визуализации matplotlib позволяют анализировать данные почти «на лету», да и кода C# требуется писать гораздо больше. Поэтому в случае нехватки памяти/скорости оптимальным вариантом видится использование стека JN для отладки модели на ограниченной выборке и финальная реализация уже на C#.














