
От переводчика
С того момента, как я начал заниматься мониторингом, прошло достаточно много времени, и если поначалу мониторинг представлял из себя специфичную техническую задачу, то со временем его значение, (по крайней мере, для меня лично) переместилось на много ступенек вверх и стоит теперь в одном ряду с основными инструментами для ведения бизнеса, такими, например, как корпоративная информационная система.
Начав выкладывать на хабре некоторые свои статьи и переводы, касающиеся тематики мониторинга ИТ-инфраструктуры, мне опять пришлось столкнуться с очень узким и техническим пониманием этой темы, которое у меня уже когда-то было и поэтому у меня однажды возникла идея изложить это системно. Я даже начал, не торопясь, писать статью на эту тему, но интуитивно понятные вещи не очень хорошо ложились на бумагу – за деревьями не получалось леса. Конечно, у нас у всех есть Google и возможность подсмотреть что пишут другие авторы, но не тут-то было. Бесчисленные статьи и заметки в блогах были посвящены техническим аспектам взгромождения очередной системы мониторинга на очередную версию операционной системы и связанное с этим героическое преодоление трудностей. Cтатей по методологии мониторинга, принципами выбора метрик, правильного построения процесса и увязывания его с бизнесом было очень мало и они также описывали некоторые частные случаи применения мониторинга для решения той или иной проблемы и не более того. А потом мне случайно попалась в руки совсем небольшая книга Дона Джонса «Создание унифицированной системы ИТ-мониторинга в вашем окружении (ENG)».
Это было то, что нужно – в ней было описана философия, изложен ряд концепций и перечислены некоторые направления, следуя которым, можно добиться чтобы система мониторинга работала на ИТ и организацию в целом, и из частностей наконец-то начала складываться общая картина. До каких-то идей я дошел самостоятельно, но был рад, что нашел много нового, что мне показалось интересным и достойным обсуждения в кругу специалистов. И что самое удивительное – эта книга была бесплатна.
Почему я её решил перевести? Я, конечно, не сомневаюсь, что на хабре 2/3 обитателей хорошо читают и говорят по-английски, но надо думать и о тех, кто этого делать не умеет или у него не хватит терпения осилить столько английских букв. Я сам лично предпочитаю читать по-русски, особенно когда это не касается терминологии, имеющей спорный перевод на русский язык (привет, PMBOK!), а связано с жизненными и достаточно эмоциональными темами. Перевод – моя личная инициатива, я не получаю от него никаких материальных выгод и вижу своей единственной задачей привнесение новых знаний для широкого круга читателей, надеясь, что кто-то, возможно, сумеет задуматься над своими ежедневными проблемами и увидеть, что их решение существует. Единственная моя заслуга заключается в пересказе русскими словами мыслей, изложенных автором. :)
Кроме того, мне бы очень хотелось обсудить содержащиеся здесь идеи и предложения. Не секрет, что разница в менталитете, жизненном укладе, правовой базе может порождать свои специфические проблемы, отличающиеся от описанных у автора, и наверняка есть уже опробованные способы борьбы с ними, просто широкая часть IT-народа об этом не в курсе.
Эта книга, в первую очередь, будет полезна руководителям ИТ – начальникам отделов и служб, руководителям проектов ИТ-мониторинга, главным и ведущим специалистам, системным администраторам, которые собираются когда-нибудь стать руководителями и пытаются понимать, что их деятельность значит для организации в целом.
P.S. Все выделения курсивом по тексту – авторские, если не оговорено иначе.
Содержание
Глава 1. Управление вашим IT окружением: четыре вещи, которые вы делаете неправильно
Глава 2. Устранение практики управления по отдельным участкам в IT-менеджменте
Глава 3. Соединяем всё в единый цикл управления ИТ
Глава 4. Мониторинг: взгляд за пределы ЦОД
Глава 5: Превращаем проблемы в решения
Глава 6: Унифицированное управление на примерах
От автора. Введение для Realtime Publishers
В течение семи лет, Realtime произвела десятки высококачественных книг, которым суждено было распространяться в электронном формате; причем, бесплатно для вас, читателей. Мы сумели сделать работоспособной эту издательскую модель посредством щедрой поддержки и сотрудничества с нашими спонсорами, которые согласились принять на себя бремя производства каждой книги для пользы наших читателей.
Хотя мы и ранее всегда предлагали наши публикации вам совершенно бесплатно, но не сомневайтесь ни на минуту, что качество значит для нас меньше, чем наша основная цель. Цель моей работы – быть уверенным в том, что наши книги настолько же хороши, а в большинстве случаев даже лучше, чем любая печатная книга, которая обойдётся вам в $40 и более. Наша электронная издательская модель имеет ряд серьезных преимуществ перед печатными книгами: вы получаете главы буквально сразу после того как наши авторы их пишут (это аспект «реального времени», присутствующий в нашей модели), и мы можем в них вносить изменения, чтобы иметь возможность отражать новые веяния в технологиях. Я хотел бы также подчеркнуть, что наши книги – это не реклама и не white papers. Мы – независимая издательская компания, и важным аспектом моей работы является предоставление площадки для наших авторов, чтобы они имели возможность выражения своего экспертного мнения без всяких ограничений и оговорок. Мы соблюдаем полный редакционный контроль над нашими публикациями, и я горд, что мы сумели создать столько качественных книг за последние годы.
Я хотел вас бы пригласить посетить наш сайт nexus.realtimepublishers.com, особенно если вы получили данную книгу от своего друга или коллеги. У нас есть большое количество других книг на самые разные темы, и, несомненно, вы найдёте то, что вам может быть интересно – и это вам ничего не будет стоить. Мы надеемся, что вы продолжите посещать Realtime в образовательных целях и в будущем.
С удовольствием,
Дон Джонс, редактор серии.
Глава 1. Управление вашим IT окружением: Четыре вещи, которые вы делаете неправильно
В самом начале существования индустрии IT, понятие «мониторинг» означало человека, который бродил в поисках перегоревших электронных ламп среди шкафов, где располагался мэйнфрейм. Конечно, это был не совсем правильный путь выявления неисправных вакуумных приборов, работавших в немного более сложных условиях, чем они были для этого предназначены. Таким образом мониторинг, на тот момент, был исключительно реактивным способом реагирования на проблемы.
В те же самые времена, «хелп деск» представлял собой того же парня, отвечавшего на телефонные звонки, когда одному-другому десятку «компьютерных людей» нужна была помощь в заталкивании карт в считыватель, в отслеживании перегоревших ламп и так далее. Концепции тикетов, баз знаний, соглашений об уровне обслуживания (SLA) еще не были изобретены. Управление IT с того времени существенно улучшилось, но к несчастью, не до того уровня, каким оно могло или должно было быть. Определенно, наши рабочие инструменты стали существенно более сложными и зрелыми, но способ, которым мы используем эти инструменты – наши процессы управления IT, кое в чём, всё еще остаются на уровне реактивных способов замены радиоламп.
Некоторые из концепций, на которых базируются практики управления IT во многих организациях, на самом деле приносят им вред, хотя по логике вещей IT должно поддерживать их работу. Обсуждение в данной главе будет сконцентрировано около нескольких главных тем, которые плавно перейдут в последующие главы книги. Цель – изменить ваше мышление о том, как должно работать управление IT, а в особенности, мониторинг; какую ценность для организации должны приносить IT, и как вы должны сделать поворот к лучшему управлению вашим IT окружением.
IT-менеджмент: как мы до этого дошли, и почему у нас есть то, что есть
В начале существования IT, мы имели дело с относительно простыми системами, даже упрощенными, если рассматривать их через призму стандартов сегодняшнего дня. Команда IT специалистов часто состояла из людей, которые были в состоянии решить любую из возникших проблем, уже хотя бы потому, что в системах не было такого большого количества «движущихся деталей», если представлять IT в виде автомобиля. Машина была по своему сложной и умела делать самые различные вещи, но при этом она полностью понималась отдельно взятым человеком.
По мере того как IT-автомобиль начал превращаться в космический корабль, нам постепенно потребовалась специализация. Персональные системы стали настолько сложными, что нам требуются эксперты со специфическими знаниями, которые в состоянии мониторить, поддерживать и управлять каждой системой.
Системы передачи сообщений. Базы данных. Инфраструктурные компоненты. Службы каталогов.
Вендоры, создающие эти системы, совместно с третьими производителями, разработали инструментарий, помогающий нашим экспертам мониторить и управлять каждой системой. И именно там всё пошло не так, хотя в какой-то момент времени всё выглядело замечательно, и, в действительности, возможно, не было другого способа выполнять эти задачи, но именно это и привело к образованию своих собственных владений (domain-specific silos) – каждая со своими индивидуальными инструментами, процедурами и экспертизой – то, что стало проблемой «отдельных башен» внутри многих IT служб.
А теперь быстро переместимся к настоящему, когда наши системы стали существенно более сложными, с огромным количеством связей и, при этом, они всё чаще расположены за пределами наших собственных ЦОД. Когда пользователь сталкивается с проблемой, совершенно очевидно, что они не могут нам сказать, в какой из наших сложных систем есть проблема. Они просто говорят нам, что они видят и как, по их мнению, эта проблема проявляется, что может быть совокупным результатом взаимодействия нескольких систем и их взаимозависимостей. Наши пользователи видят целостное окружение — «ИТ» вообще, что несколько не похоже, на то, что мы видим со стороны нашего бэк-енда: базы данных, сервера, каталоги, файлы, сети и много чего еще. В результате, мы часто тратим много времени на отслеживание истинной причины проблемы, и, что хуже, мы часто даже не видим надвигающийся инцидент, потому что проблема присутствует, только когда вы посмотрите на конечный результат работы всего окружения, а не какой-то его отдельной части. Пользователи чувствуют себя полностью оторванными от процесса, а кроме того, от ИТ их ещё отделяет «хелп-деск», который иногда полезен, а иногда — нет. Управление ИТ, при этом, переживает при этом сложные времена, полностью погрузившись в проблемы производительности, доступности и так далее, потому что они вынуждены использовать метрики, которые специфичны для каждой системы в сети, вместо того, чтобы рассматривать окружение в целом.
Путь, по которому мы выстроили наши ИТ-службы, привел нас к очень специфичным проблемам, находящимся на уровне бизнеса, и они стали общими предметами озабоченности и источниками жалоб по всему миру:
- У ИТ есть сложности в определении и соответствии SLA бизнес-уровня. «Почтовый сервер будет работать 99% времени» — это SLA не для бизнеса, это техническое соглашение. «Электронная почта будет беспрепятственно передаваться между внешними и внутренними пользователями почтовой системы 99% времени» — это SLA бизнес-уровня, но его достаточно сложно измерить, потому что это утверждение вовлекает в свое выполнение существенно больше систем, чем простой почтовый сервер (Вообще-то крайне неосмотрительно подписываться под ответственностью за системы, находящимися за пределами границ ответственности локальной службы ИТ. Будем надеяться, что автор не имел ввиду ничего другого — пр.перев).
- У ИТ есть трудности в проактивном предсказании сложных ситуаций на основе показателей общего «здоровья» ИТ систем, так что ИТ службы, по большей части, остаются реактивными в решении проблем.
- Когда проблема случается, ИТ часто тратит слишком много времени на детальное выяснение причины её возникновения.
- Используемые в ИТ концепции производительности и «системного здоровья» отталкиваются от систем – серверов баз данных, серверов служб каталогов, сетевых устройств и так далее – а не от того, как пользователи и организация в целом воспринимают сервисы , предоставляемые этими системами.
- ИТ-служба напряженно работает во время адаптации новых технологий, которые могут дать выигрыш для бизнеса. Звучит странно, но факт остаётся фактом – ИТ-служба часто является самой сопротивляющейся изменениям частью организации, потому что изменения обычно являются спусковым крючком многих неприятностей. Неисправные системы не помогают никому, но невозможность быстро внедрить изменения в структуру компании также может быть угрозой компетентности организации и её гибкости в ближайшем будущем.
- ИТ-служба очень напряженно работает, адаптируя новые технологии, которые существенно выходят за пределы опыта и компетенции команды или находятся за пределами физической доступности, особенно если это касается массы аутсорсных предложений, обычно объединяемых под понятием «облачные вычисления». Эти технологии и подходы настолько отличаются от того, что было раньше, что ИТ не чувствует себя уверенными в мониторинге и управлении новыми системами. Поэтому они сопротивляются реализации подобных решений, опасаясь, что их внедрение нанесёт вред организации.
- Даже при наличии современных систем самостоятельной помощи, стоящих на службе «хелп-деска», пользователи чувствуют себя невероятно беспомощными и оторванными от ситуации, когда дело касается ИТ.
Все эти камни преткновения, находящиеся на уровне бизнеса, являются прямым результатом того, как мы управляем ИТ. Наши процессы мониторинга и ИТ-менеджмента, как правило, имеют четыре главные проблемы. Конечно, не у каждой организации они присутствуют все сразу, большинство, по крайней мере, слышало о них и упорно работает над противодействием им. Однако, компаниям нужно четко понимать, что они имеют представление о всех четырёх проблемах, и если это выполняется, то практически сразу можно приступить к решению вопросов бизнеса, которые мы упоминали ранее.
Проблема 1: Вы управляете ИТ по отдельным участкам («башням»).
Рисунки 1.1, 1.2, и 1.3 иллюстрируют одну из фундаментальных проблем в IT мониторинге и управлении на сегодняшний день.

Рисунок 1.1: Измерение производительности ОС Windows в Windows Performance Monitor.

Рисунок 1.2: Измерение производительности сервера СУБД в SQL Server Performance.
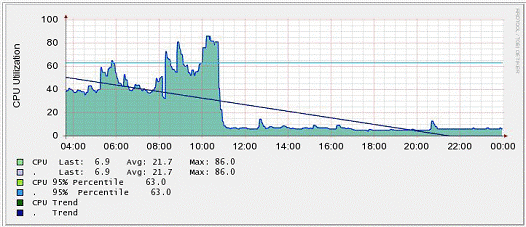
Рисунок 1.3: Измерение загрузки процессора на роутере
Числа отображают состояния производительности/загрузки различных компонентов ИТ системы. Каждое из этих изображений создано инструментом, который более или менее специализирован для отслеживания результатов выполнения определенной задачи. ПО, которое используется для отслеживания производительности роутера, например, не в состоянии воспроизвести аналогичную картинку для сервера баз данных или даже для роутера, который находится в другой сети.
Это настолько общая и фундаментальная проблема, что большинство ИТ экспертов даже не хотят признать, что это представляет проблему. Использование этих раздельных, строго специфичных инструментов, является настолько укоренившейся и естественной практикой в работе ИТ, что большинство из нас просто не могут о подумать о чём-то другом. И тем не менее, нам надо оставить в прошлом использование этих специализированных инструментов в качестве первой линии обороны, если дело касается мониторинга и устранения проблем.
Почему?
Одна из главных причин, заключается в том, что эти инструменты не дают нам оставаться на «одной странице». Когда вовлекается специфичный инструментарий, логичной и многопрофильной дискуссии у ИТ-экспертов не получается. «Я смотрю на сервер СУБД и его производительность больше чем 200 транзакций в минуту», говорит один эксперт. «Ну, это может быть проблемой, потому что роутер обрабатывает более чем 10000 пакетов в минуту». Два специалиста не имеют общего языка, на котором можно было бы продуктивно поговорить о производительности, потому что каждый из них заперт в собственной «башне» -глубоко технических аспектах технологий, с которыми они преимущественно работают.
Специфичный для конкретной области инструментарий также поощряет наихудшую практику во всех службах ИТ, а именно — рассмотрение систем в изоляции. Администратор СУБД не имеет ни малейшего представления как работают роутеры, что представляет собой хорошая или плохая производительность почтового сервера, или на что надо смотреть, чтобы удостовериться, что инфраструктура службы каталогов работает как положено. Поэтому администратор СУБД надевает на себя лошадиные шоры и смотрит только на сервера баз данных, но его сервера не работают в вакууме; на их работу оказывают влияние другие системы, равно как и они сами влияют на остальную инфраструктуру. Всё работает вместе, но мы не можем этого видеть, потому что используем слишком специализированные инструменты. В основном, это означает, что нам необходимы новые средства, которые позволят специализированному инструментарию, предназначенному для доступа к отдельным «башням», работать в единой команде, перемещая нужную всем информацию в общий контекст. Без всякого сомнения, специализированные инструменты всегда будут востребованы, но они не будут нашей первой линией доступа к информации.
Джерри работает в типовом ИТ департаменте в компании средней руки. Его специальность – администрирование серверов Windows. В его команде есть специалисты по Web-приложениям, MS SQL Server и Oracle, VMware vShpere, а также сетевой инфраструктуре. Некоторые корпоративные приложения выведены на аутсорсинг: CRM (управление отношений с клиентами) и почта.
Недавно произошел инцидент, из-за которого прекратилось отправление клиентам почтовых сообщений, содержащих электронное подтверждение заказа. Для решения проблемы поначалу привлекли Джерри, исходя из предположения, что причина могла быть в почтовой службе, выведенной на аутсорсинг. Однако, Джерри выяснил, что почта проходит нормально. Он передал проблему специалисту по web-решениям, который подтвердил, что сам веб-сайт работает нормально, но почта, которую он отправляет, где-то заворачивается. Джерри заполнил тикет в компании, которая занимается хостингом почты, на что та ответила, что их системы работают в порядке, и что неплохо было бы проверить пароли, которые используют web-серверы клиента.
Прошло больше дня переписки с хостинговой компанией и различными экспертами, и проблема наконец спустилась до корпоративного брэндмауэра. Не так давно было сделано обновление до новой версии, и она блокировала исходящий почтовый трафик с периметра корпоративной сети, как раз там, где находились web-серверы компании. Вызвали сетевого специалиста, он переконфигурировал брэндмауэр и проблема была решена.
Этот рассказ точно иллюстрирует суть проблемы: если мы управляем нашими командами ИТ специалистов как удельными княжествами, мы существенно препятствуем их возможностям работать вместе при решении проблем. То, что им для выполнения работы необходим специализированный инструмент, не должно быть препятствием в разрушении границ отдельных владений и более эффективной совместной работе. Это становится особенно важно, когда некоторые части инфраструктуры переводятся на аутсорсинг; хостинговые компании являются суверенными «государствами», потому что они не отвечают ни за какие другие системы, кроме тех, которые они предоставляют. Однако, зависимость наших систем и процессов от их систем означает, что наша собственная команда должна быть в состоянии осуществлять мониторинг и знать, что с ними делать в случае неполадок, как если бы эти системы стояли прямо в нашем центре обработки данных
Проблема 2: Между вашими пользователями, сервис-деском и ИТ-менеджментом нет связи.
Коммуникации – это ключевой компонент, который делает работоспособной любую команду; и в данном случае не является исключением «команда», представляющая собой вашу организацию. В случае ИТ, мы обычно используем системы для организаций хелп-деска, подразумевая, что это разумный способ осуществления коммуникаций, но этого не всегда бывает достаточно. Системы хелп-деска, как правило, строятся на концепции реагирования на проблему и последующем управлении реакцией, и по определению, они практически не проактивны.
Например, как вы сообщите вашим пользователям, что данная система будет иметь сниженную производительность или будет отключена в течение некоторого периода времени? Возможно по электронной почте, что создает еще пару проблем:
- Важное сообщение имеет тенденцию теряться в наплыве е-мейлов, который пользователь получает каждый день.
- Пользователи, не понявшие, либо не получившие сообщение, имеют привычку идти через хелп-деск, у которого нет способов вмешаться в мыслительные процессы и бесконтактным способом объяснить им, для чего планировалось мероприятие, которое пользователи считают «проблемой».
Большинство ИТ команд прекрасно представляют, что необходимо для успешных коммуникаций во всей организации, например:
- Соглашения об уровне обслуживания (SLA)
- Текущий статус SLA – насколько они выполняются.
- Планируемые отключения и снижения производительности
- Среднее время ответа отдельных сервисов
- Текущие проблемы, которые находятся в работе.
Проблема большинства ИТ команд заключается в обмене информацией по этим темам во всей организации целиком. Некоторые компании полагаются на электронную почту, которая, как я уже указывал ранее, может быть недостаточна и не вполне эффективна. Некоторые офисы используют внутренний веб-сайт, такой например как портал SharePoint, на котором публикуются заметки, но эти сайты не имеют прямой интеграции с хелп-деском, так что необходимо делать дополнительный шаг, связанный с синхронизацией информации в обеих системах, а от пользователей требуется помнить, что на портал надо периодически заходить.
Том работает в качестве менеджера по продажам в производственной компании среднего размера. Недавно, приложение, которым пользовался Том для отслеживания предполагаемых клиентов и создания новых счетов начало очень медленно отвечать и, к концу дня, полностью замерло. Первоначальной реакцией Тома было позвонить в хелп-деск ИТ службы компании. Технический специалист хелп-деска усталым голосом сказал Тому: «Мы в курсе, мы над этим работаем», и повесил трубку. У Тома нет никакой информации о том, когда система заработает снова и он побоялся перезвонить в хелп-деск и узнать состояние дел более подробно.
На исходе дня, хелп-деск зарегистрировал звонки от практически каждого продавца, каждый из которых позвонил по собственной инициативе, желая понять, что же происходит. В конце концов, хелп деск прекратил регистрацию звонков, сообщая каждому звонившему, «тикет уже открыт» и вешая трубку. Наконец, кто-то из IT менеджеров наконец-то разослал e-mail, поясняющий, что вышел из строя сервер и приложение не будет работать до следующего утра. Том очень хотел бы знать это раньше; ведь он собирался звонить клиентам весь день, но если бы эта информация о том, что приложение не будет доступно столь долго, поступила своевременно, он бы занялся чем-нибудь другим, а то и вовсе взял отгул.
Управленческие коммуникации столь же важны, сколь и непросты. Обеспечение честных цифр в уровнях сервисного обслуживания, времени реакции, отсутствия сервисов и так далее – это всё крайне важно, если менеджменту необходимо принимать хорошо проработанные решения в плане ИТ, но достоверную информацию зачастую бывает получить совсем не просто.
Проблема 3: Вы измеряете не то и не там.
Эта проблема, пожалуй, находится в сердце любой IT службы – бездействие в подстраивании технологии под нужды бизнеса. В следующем примере демонстрируется как раз такой сценарий.
Шелли работает в бухгалтерии. Недавно, при попытке закрытия главной книги, бухгалтерская программа начала работать крайне медленно. Она позвонила на хелп-деск IT, чтобы сообщить о проблеме. Технический специалист выслушал ее, а затем сказал: «Прямо сейчас на сервере всё в порядке. Я открою тикет и попрошу кого-нибудь посмотреть, что там делается, но так как параметры сервисного соглашения по времени ответа не нарушены, это будет тикет с низким приоритетом».
Шелли продолжила борьбу с медленно отвечающей программой. В конце концов, кто-то догадался прийти и посмотреть на её десктоп. Она продемонстрировала, что все остальные программы работали нормально. Она указала на то, что другие сотрудники в её департаменте испытывали с этим приложением схожие проблемы.
Технический специалист заставил ее закрыть все остальные приложения и затем перезапустил ее компьютер, но всё осталось по-старому. Он пожал плечами, сделал несколько заметок на своём смартфоне и вышел.
Следующим утром, время ответа приложения было лучше, но всё ещё далеко от нормального. Шелли продолжила звонить в хелп-деск, пытаясь узнать, что с её заявкой, но было похоже, что служба ИТ сдалась в попытках исправить проблему, и даже отказалась признавать, что здесь была проблема.
Такого рода ситуации, к несчастью, часто случаются во многих организациях. Этот пример точно иллюстрирует, что происходит, когда одновременно случается несколько проблем: ИТ работает не как команда, а как группа разрозненных специалистов, а в каждой из этих групп есть свое понимание слова «медленно». Главная причина заключалась в том, что каждый измерял не то и не там. На рис 1.4 показано как обычная ИТ служба видит многокомпонентное, распределенное приложение:

Рис 1.4 Взгляд ИТ службы на распределенное приложение.
Они видят составные части. Эксперты по каждому компоненту измеряют их производительность, используя технические метрики, такие как утилизация процессора, время ответа и т.д. Когда какой-то из компонентов выходит за допустимые значения, кто-нибудь из инженеров начинает его проверять. На рисунке 1.5 показано как пользователь видит тоже самое приложение.
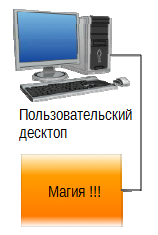
Рисунок 1.5 Взгляд пользователя на распределенное приложение.
Пользователь не видит (очень часто – не может видеть) внутреннюю структуру. Для него существует приложение, и либо оно отвечает ожидаемым образом, либо нет. Пользователю абсолютно без разницы, работает ли какой-то конкретный компонент с «приемлемым уровнем утилизации процессора» — он не знает, что это означает. Его волнует, работает ли приложение; что и создает большой разрыв между восприятиями пользователя и инженера ИТ, как это показано на рис. 1.6.
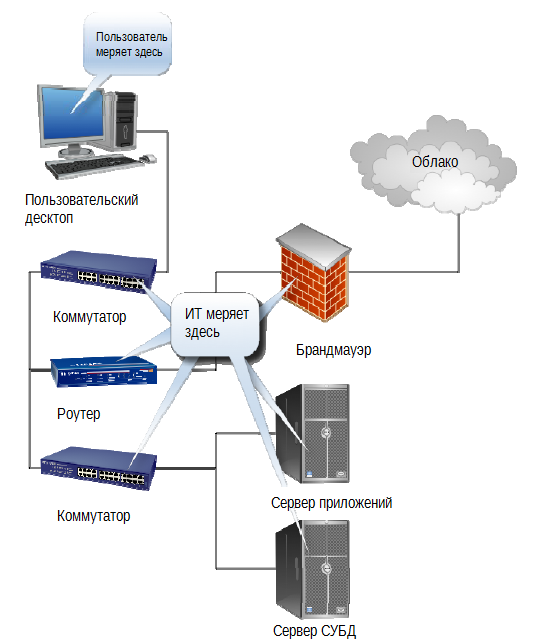
Рис. 1.6. Измерение производительности пользователем и инженером ИТ.
Пользователи и ИТ-служба измеряют разные вещи. В SLA, ориентированных на ИТ, может указываться конкретное время ответа на запросы, посылаемые на сервер СУБД, но это малополезно, если приложение, с точки зрения пользователя, работает «медленно». Что еще хуже, если мы начинаем мигрировать сервисы и компоненты в «облако», то мы теряем большую часть наших способностей определять производительность наших компонентов тем способом, которым мы привыкли это делать в наших ЦОД. Результат? Ни одну из сторон не устроят положения такого SLA.
Всё это надо менять. Нам надо научиться измерять вещи с точки зрения пользователя. Производительность индивидуальных компонентов важна, но только в той степени, насколько это влияет на общую производительность, ощущаемую на конкретном рабочем месте. Нам необходимо прописывать такие SLA, в которых и пользователь и служба ИТ находятся «на одной странице», затем управлять выполнением этих SLA теми способами и инструментарием, которые позволяют это успешно делать. Некоторые организации сообщают, что они переходят, или уже перешли к работе ИТ на основе предоставления сервисов — это, в широком смысле слова, означает, что компания ищет способ реализовать работу ИТ службы в виде набора сервисов для различных департаментов организации и их пользователей. Однако, во многих случаях, эти «сервисно-ориентированные» организации всё еще сфокусированы на компонентах и устройствах, что, вообще говоря, совсем не является сервисно-ориентированным подходом. Когда падает ваша телефонная станция, вы же не звоните в телефонную компанию (возможно, с вашего мобильного) и не начинаете задавать вопросы про коммутаторы и транки – вы спрашиваете, когда в вашей трубке снова появится привычный зуммер. Внутренняя структура для пользователя не имеет никакого значения. Кредит вашего ожидания строится не на том, сколь долго офис отдельно взятой телефонной компании будет неработоспособен, вы спрашиваете себя, сколь долго вы можете себе позволить отсутствие исправной телефонной связи. Именно к такой модели следует двигаться службам информационных технологий.
Проблема 4: Вы теряете знание
Последняя проблемная практика, которую мы рассмотрим – это потеря изначальных знаний. Чисто человеческое слабое место, и честно говоря, его сложно куда-либо конкретно адресовать. Чтобы это понять, давайте рассмотрим обычный случай:
Аарон работает в ИТ департаменте своей организации. Он здесь уже три года и отвечает за ряд системных и инфраструктурных компонентов. В один из вторников, с Аароном связался специалист из хелп-деска их же компании:
«Мы передаем вам тикет связанный с системой Oracle», -сказали в трубке, — «Раз в два месяца он начинает себя непредсказуемо вести и надо, чтобы кто-нибудь с этим разобрался».
«Но я не специалист по Oracle», — ответил Аарон, «Системой Oracle у нас занимается Джил».
«Да, но Джил в отпуске еще две недели. Надо чтобы вы этим занялись».
«Но я понятия не имею, что надо делать!».
«Ну, что-нибудь придумайте… Исполнительный директор будет очень недоволен, если это затянется».
К несчастью, в головах отдельных людей скапливается слишком много знаний. На самом деле, еще более печальной истиной является способ, которым многие компании «справляются» с данной проблемой — отказывая некоторым специалистам ИТ в полноценных отпусках, не позволяя заниматься какой-либо другой деятельностью, выводящей их из поля зрения и досягаемости – такой, например, как обучение за пределами компании, поездки на конференции, как раз всё то, что продолжает их образование и позволяет приобретать новые навыки.
Можно пересчитать по пальцам компании, которые предприняли половинчатые попытки построения «баз знаний», в надежде, что базовые навыки можно перенести в электронные документы, сохранить и сделать более доступными. Проблема в том, что многие ИТ профессионалы совершенно необязательно являются хорошими писателями, так что сам процесс наполнения базы знаний для них будет весьма труден. Кроме того, это требует времени, которое организация крайне неохотно выделяет для этой цели, особенно перед лицом ежедневных неотложных задач и требований.
Как я говорил, такое положение вещей сложно исправить. ИТ служба понимает ситуацию, и как правило, согласна с тем, что надо что-то делать – но они не технописатели, и зачастую имеют к этому крайне ограниченные способности. Вы обычно можете создать некоторые управленческие требования, в которых будет отражено, что проблемы и их решения обязаны быть зарегистрированы в виде тикетов на хелп-деске, но поиск в такой системе часто может быть затруднён или требовать много времени – в точности также, как это происходит при поиске в Интернете; со всеми неверными результатами, которые необъятной массой вываливаются на экран при стандартной процедуре запроса.
Но мы обязаны найти способ решения этой проблемы. Знание о инфраструктуре компании – и о том, как решать проблемы должно быть аккумулировано и сохранено. Данное требование не только поможет быстрее решать возникающие вопросы в будущем, но также поможет предотвращать их появление, позволяя принимать более взвешенные решения в области ИТ.
Насколько точно унифицированное управление позволяет исправить проблемы?
Эта книга посвящена тому как исправить эти четыре досадных момента, и способы, которые я для этого предлагаю, могут быть собраны под зонтиком сводного понятия «унифицированное управление». По своей сути, унифицированное управление сводится к тому, чтобы собрать всё вместе в одном месте.
Мы снесём границы «удельных княжеств» между отдельными дисциплинами IT, поместим всё, что нам нужно на одну консоль, заставим работать каждого специалиста над одним общим набором данных и вынудим всех вместе работать над проблемой. Мы сделаем это таким способом, который объединит пользователей, ИТ и управленцев в единое окно ИТ сервисов и производительности. Мы придадим больше прозрачности таким вещам, как уровни обслуживания, позволив пользователям видеть, что происходит в их окружении и быть более информированными.
Мы будем предоставлять нашим пользователям сведения, которые им будут понятны, вместо того, чтобы использовать неясные, чисто технические метрики, которыми мы пользуемся в нашем бэк-енде. Мы перестроим всю концепцию SLA, в нечто, что имеет смысл в первую очередь для пользователей и их руководства, что позволит нам выстоять при переходе к «гибридному ИТ», где неизбежно возникновение сложностей при аутсорсинге некоторых ИТ-сервисов в «облако».
В итоге, мы найдём способ собирать информацию о нашем окружении, включая способы разрешения инцидентов, которые позволят нам в будущем сэкономить время, если подобные вопросы у нас возникнут ещё раз. В дополнение к этому, данная информация позволит руководству принимать более грамотные решения в отношении выбора будущих технологий и инвестиций.
Мы постараемся сделать это таким образом, чтобы не заставить организацию продать на органы часть своих сотрудников, а также не потребует половины жизни на реализацию. Конечно, это потребует некоторой креативности, включая поиск аутсорсных решений. Идея аутсорсного мониторинга для внутренних систем является относительно новой, и мы посмотрим, насколько она применима.
Я должен подчеркнуть, что большинство из того, что мы рассмотрим, поможет справиться с поддержкой тех управленческих фреймворков, которые многие организации внедряют уже сегодня, включая ITIL, ставший популярным за последние годы. Вам не нужно быть экспертом в ITIL, чтобы воспользоваться преимуществом предлагаемых мною новых процессов и приемов – вам даже вообще не надо думать о внедрении ITIL (или любого другого фреймворка), за исключением случая, если ваша организация уже этим занимается. Но если у вас уже используется набор организационных процедур, вам будет приятно узнать, что всё, что предлагается в этой книге, в них прекрасно впишется.
Заключение
В данной главе перечисляются четыре основные темы, которым будут посвящены оставшиеся главы этой книги. И их основу составляет то, что многие эксперты считают самыми серьезными и фундаментальными проблемами, с которыми ИТ приходится сталкиваться сегодня, а также содержится ряд вещей, на способах исправления которых, мы сконцентрируемся в оставшейся части. Мы уделим внимание смене философии управления и используемых практик, не только посредством выбора новых инструментов, хотя новые инструменты могут быть как раз той основой, которую вы выберете для реализации этих новых решений.
Глава 2 будет посвящена первой проблемной практике, заключающейся в управлении ИТ инфраструктурой по отдельным участкам. Мы рассмотрим технологические причины, из-за которых организации более или менее вынуждены следовать по этому пути, и исследуем направления, с которых вы можете начать, чтобы изменить сложившуюся практику.
В Главе 3 будут рассмотрены связанные между собой люди: руководители IT, ваши пользователи, ваш сервис-деск и так далее. Только общее вовлечение всех сотрудников в процесс может позволить ИТ лучше подстроиться под нужды организации.
Наша третья проблемная практика будет предметом обсуждения для Главы 4, где мы погрузимся в поиски внешнего датацентра для мониторинга. Итоговой целью будет решение проблем, которые мы будем обсуждать в данной главе, фокусируясь в дальнейшем на ценности, создаваемой ИТ для своей организации.
В Главе 5 будут рассматриваться способы превращения проблем в решения. Хотя современные организации полностью осведомлены о необходимости отслеживания информации, проходящей через хелп-деск, и построения системы знаний, те способы, как эти процессы управляются, будучи частью общей системы управления ИТ, могут представлять собой большую разницу, по сравнению с изначально запланированной добавленной ценностью.
Заключительные выводы будут сделаны в главе 6, где мы сделаем попытку визуального представления ИТ окружения, в котором используются новые, унифицированные практики управления. Я также приведу ряд историй, которые помогут вам увидеть, как эти обновлённые практики работают в реальной жизни.
Только зарегистрированные пользователи могут участвовать в опросе. Войдите, пожалуйста.
Хотите знать больше?
96.86% Да308
4.4% Нет14
Проголосовали 318 пользователей. Воздержались 22 пользователя.









