 После анализа подобранных паролей к LinkedIn появилась идея создать генератор паролей, совмещенный с валидатором, не допускающим легко подбирающиеся пароли. Простейшего анализа на длину, наличие специальных символов здесь не достаточно — некоторые пароли можно легко собрать из очень вероятных «кусочков» и на их перебор уходит существенно меньшее время, нежели теоретически заявленное. И гарантий, что программа-генератор не выдаст вам подобный пароль нет — случайность, она на то и случайность. Мое творение не претендует на полное решение вопроса, скорее это повод для размышлений, но оно вполне работоспособно (исходники и небольшой разбор тоже присутствуют).
После анализа подобранных паролей к LinkedIn появилась идея создать генератор паролей, совмещенный с валидатором, не допускающим легко подбирающиеся пароли. Простейшего анализа на длину, наличие специальных символов здесь не достаточно — некоторые пароли можно легко собрать из очень вероятных «кусочков» и на их перебор уходит существенно меньшее время, нежели теоретически заявленное. И гарантий, что программа-генератор не выдаст вам подобный пароль нет — случайность, она на то и случайность. Мое творение не претендует на полное решение вопроса, скорее это повод для размышлений, но оно вполне работоспособно (исходники и небольшой разбор тоже присутствуют).Надежность vs доверие
Изначально хотел оформить идею как некий Веб-сервис, однако одумался; грамотный пользователь должен сперва задуматься, куда может попасть его возможный пароль, а для сетевых технологий — этот вопрос без очевидного ответа, и есть все поводы не доверять подобным сервисам вообще. Вы только закончили ввод пароля, а AJAX'ом он уже утянут и сохранен на сервере. Нет, уж, спасибо.
Неизвестное десктопное приложение в этом плане ничем не лучше, у него есть много возможностей незаметно отправить запрос в интернет. Именно из-за этого не пользуюсь программами-генераторами сам. И несмотря на огромные списки источников энтропии, нет гарантий, что твой пароль не окажется в чьей-то базе.
Поэтому сам предлагаю программу в исходных кодах (на C#, исходя из того, что на разработку не хотелось тратить больше пары часов) и настоятельно рекомендую собирать ее из исходников.
Генерация паролей
Самая простая и универсальная схема генерации — получить некоторую энтропию и преобразовать ее в строку целевой длины, с заданным набором символов.
Для преобразования есть довольно-таки стандартное решение, сводящееся к вызову хеш-функции, как эффективной свертки пула энтропии (то есть неких случайных значений):
string generatePassword(string charset, int length)
{
byte[] result;
SHA1 sha = new SHA1CryptoServiceProvider();
result = sha.ComputeHash(seed); // <--- текущий пул энтропии
// create password
StringBuilder output = new StringBuilder();
for (int i = 0; i < result.GetLength(0) && output.Length < length; i++)
output.Append(charset[result[i] % charset.Length]);
// update seed
for (int i = 0; i < result.GetLength(0); i++)
addToSeed(result[i]);
return output.ToString();
}
Сами случайные значения можно набирать разными способами:
- аппаратные решения,
- окружение системы (значения в памяти, свойства процессов),
- получение данных от интернет-сервисов,
- взаимодействие с пользователем.
Но первые три пункта я считаю совершенно избыточными в идеале, а в реальности еще и плохо прогнозируемыми. Нет никакой уверенности, что аппаратный датчик не сломается, и не будет выдавать «одно и то же», окружение системы может не быть достаточно динамичным, а интернет-сервис может специально вернуть (и сохранить) сгенерированные в корыстных целях данные. Это случайные числа, и даже имея возможность на них взглянуть, мы ничего не поймем.
Так что решено было использовать те данные, процесс получения которых зависит от пользователя, и одним из самых простых и удобных вариантов — сохранение перемещений мыши. Каждое перемещение характеризуется координатами и временем, что хоть и имеет предсказуемый в общем вид, но в конкретных числах — всегда различим и практически случаен, особенно если замерять время счетчиком с высоким разрешением (в тиках процессора).
void handleMouseData(int x, int y)
{
/* store information in seed array */
addToSeed(x);
addToSeed(y);
addToSeed(ticks());
}
Та небольшая часть кода, которая относится к формированию энтропии из окружения, содержится в этой простой функции:
int ticks()
{
long timer;
if (QueryPerformanceCounter(out timer) == false)
{
// high-performance counter not supported
throw new Win32Exception();
}
/* ignore significant bits due its stability - we prefer using fast-changing low bits only */
return (int)timer;
}
Счетчик QueryPerformanceCounter имеет разное разрешение в зависимости от системы, а его значение меняется в зависимости от текущей загрузки процессора, количества процессов, факта context switch. Одна величина, которая, хоть и имеет прогнозируемый рост, но в конкретных числах его выразить очень сложно.
Как следствие, мы получаем хорошие пароли, не заставляя пользователя нажимать какие-то хитрые комбинации, часами ждать окончания генерации, мучиться со сложным интерфейсом программы. Я не претендую на аккуратность в дизайне интерфейсов (даже смешно стало, после осознания скриншота ниже), но предполагаю, что нет более удобного решения, чем ткнуть в ComboBox и выбрать из сгенеренных вариантов понравившийся.
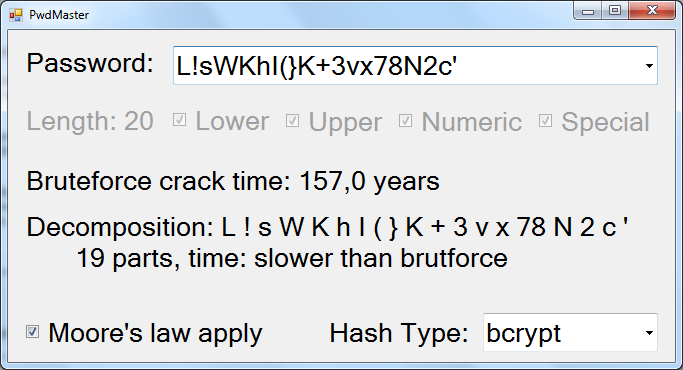
Оценка времени на взлом
Для прямого перебора итоговое время можно вычислить, исходя из следующих параметров:
- скорость функции проверки,
- мощность алфавита,
- количество символов.
Мощность алфавита — это минимальное (с разумным критерием описания) множество, содержащее символы конкретного пароля. Как правило это наборы вида:
- маленькие буквы,
- заглавные буквы,
- цифры,
- спецзнаки.
Поэтому для вычисления времени просто проверяем, символы из каких наборов содержит наш пароль, и включаем в мощность множества все символы набора:
double bruteforceCombinations = Math.Pow(26 * upper + 26 * lower + 10 * numeric + specials.Length * special, pwd.Length);
Скорость хеширования различается для разных алгоритмов, я предоставляю список с грубо оцененными значениями для популярных методов (но в реальности мы не знаем, какой используется на сервере, поэтому корректнее будет оставить только самый быстрый из популярных алгоритм, сейчас это MD5).
И не стоит забывать про закон Мура, отчего все вычисления утверждающие о «миллионах лет на взлом» кажутся очень наивными. Хотя динамику роста вычислительной мощности нельзя предсказать наверняка, но использовать текущий темп роста — лучше чем вообще ничего.
И теперь, собственно, главное — оценка времени атаки декомпозицией.
Это не так сложно, необходимо просто вычислить минимальное разбиение нашего пароля на слова некоторого словаря релевантных комбинаций (достаточно часто встречающиеся подстроки) == длина пароля. И вычислить «мощность» словаря == количество слов в нем. Итоговое количество комбинаций — все так же «мощность» в степени длины.
Если наш пароль вида «Good123Password» — то он раскладывается на «Good», «123», «Password», которые очень распространены по отдельности и время, необходимое для перебора всего лишь «совсем немного» в кубе.
Вопрос, конечно, заключается в качестве такого словаря, но опять же, любой вариант — лучше чем ничего. Я приложил к программе словарь, полученный после аудита на LinkedIn, составленный из самых частых комбинаций, встреченных в 2.5 миллионах найденных паролей. Сам словарь — всего 40 килобайт.
Результаты
Ссылка на программу и исходники: dl.dropbox.com/u/243445/md5h/pwdmaster.zip
Одним из приятных результатов является факт, что бо́льшая часть сгенерированных псевдослучайно паролей не раскладывается на вероятные комбинации. Если в других программах генераторах нет явных ошибок, или «лазеек», и по качеству генерации они не хуже моей — то «можно спать спокойно». Доля паролей для 14-символьных алфавитно-цифровых комбинаций, раскладывающихся по словарю (таким образом, что перебор по словарю быстрее прямого перебора) — менее одной тысячной процента.













