Мы удачно спроектировали структуру нашей PostgreSQL-базы для хранения переписки, прошел год, пользователи активно ее наполняют, вот в ней уже миллионы записей, и… что-то все начало подтормаживать.

Дело в том, что с ростом объема таблицы растет и «глубина» индексов — хоть и логарифмически. Но со временем это заставляет сервер для выполнения тех же задач чтения/записи обрабатывать в разы больше страниц данных, чем в начале.
Вот тут на помощь и приходит секционирование.
Замечу, что речь пойдет не о шардинге, то есть распределении данных между разными базами или серверами. Потому что, даже разделив данные на несколько серверов, вы никак не избавитесь от проблемы «распухания» индексов со временем. Понятно, что если вы можете позволить себе каждый день вводить в строй новый сервер, то ваши проблемы будут лежать уже совсем не плоскости конкретной БД.
Мы же рассмотрим не конкретные скрипты для реализации секционирования «в железе», а сам подход — что и как стоит «порезать на дольки», и к чему такое желание приводит.
Еще раз определим нашу цель: мы хотим сделать так, чтобы и сегодня, и завтра, и через год количество читаемых PostgreSQL данных при любой операции чтения/записи оставалось примерно одним и тем же.
Для любых хронологически накапливаемых данных (сообщения, документы, логи, архивы, ...) естественным выбором в качестве ключа секционирования является дата/время события. В нашем случае таким событием является момент отправки сообщения.
Заметим, что пользователи практически всегда работают только с «последними» такими данными — читают последние сообщения, анализируют последние логи,… Нет, конечно, они могут пролистать и дальше назад во времени, только делают это очень редко.
Из этих ограничений становится очевидно, что оптимальным решением для сообщений будут «посуточные» секции — ведь почти всегда наш пользователь будет читать то, что пришло ему «сегодня» или «вчера».
Если мы в течение дня пишем и читаем практически только в одну секцию, то это дает нам еще и более эффективное использование памяти и диска — поскольку все индексы секции легко умещаются в оперативку, в отличие от «больших и жирных» по всей таблице.
В общем, все сказанное выше звучит как один сплошной профит. И он достижим, но ради этого нам придется хорошо постараться — потому что решение секционировать одну из сущностей приводит к необходимости «распиливать» и связанные с ней.
Раз мы решили порезать сообщения по датам, то и зависимые от них сущности-свойства (приложенные файлы, список адресатов) разумно тоже делить, и тоже по дате сообщения.
Поскольку одной из типовых наших задач является как раз просмотр реестров сообщений (непрочитанные, входящие, все), то их тоже логично «втянуть» в секционирование по датам сообщений.
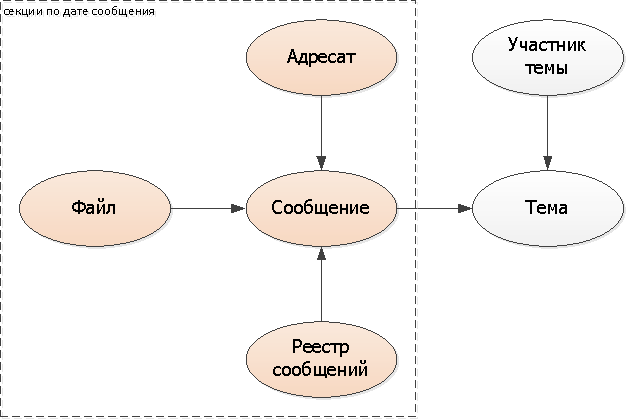
Поскольку тема одна на несколько сообщений, то ее «порезать» в той же модели уже никак не получится, надо опираться на что-то другое. В нашем случае идеально подходит дата первого сообщения в переписке — то есть момент создания, собственно, темы.

Но теперь у нас возникают сразу две проблемы:
Можно, конечно, продолжать искать по всем секциям, но это будет очень печально, и сведет на нет все наши выигрыши. Поэтому, чтобы знать, где конкретно искать, сделаем логические ссылки/указатели на секции:
Поскольку модификаций списка дат сообщений для каждой отдельно взятой переписки будет немного (ведь почти все сообщения попадают в 1-2 соседних дня), я остановлюсь именно на таком варианте.
Итого, структура нашей базы приняла следующий вид с учетом секционирования:
Ну, а если мы используем не классический вариант секционирования на основе распределения значений поля (через триггеры и наследование или PARTITION BY), а «вручную» на уровне приложения, то можно заметить, что значение ключа секционирования уже хранится в названии самой таблицы.
Поэтому если вы настолько сильно переживаете за объем хранимых данных, то от этих «лишних» полей можно и избавиться и обращаться адресно к конкретным таблицам. Правда, все выборки из нескольких секций в этом случае уже придется вынести на сторону приложения.
- Часть 1: проектируем каркас базы
- Часть 2: секционируем «наживую»

Дело в том, что с ростом объема таблицы растет и «глубина» индексов — хоть и логарифмически. Но со временем это заставляет сервер для выполнения тех же задач чтения/записи обрабатывать в разы больше страниц данных, чем в начале.
Вот тут на помощь и приходит секционирование.
Замечу, что речь пойдет не о шардинге, то есть распределении данных между разными базами или серверами. Потому что, даже разделив данные на несколько серверов, вы никак не избавитесь от проблемы «распухания» индексов со временем. Понятно, что если вы можете позволить себе каждый день вводить в строй новый сервер, то ваши проблемы будут лежать уже совсем не плоскости конкретной БД.
Мы же рассмотрим не конкретные скрипты для реализации секционирования «в железе», а сам подход — что и как стоит «порезать на дольки», и к чему такое желание приводит.
Концепт
Еще раз определим нашу цель: мы хотим сделать так, чтобы и сегодня, и завтра, и через год количество читаемых PostgreSQL данных при любой операции чтения/записи оставалось примерно одним и тем же.
Для любых хронологически накапливаемых данных (сообщения, документы, логи, архивы, ...) естественным выбором в качестве ключа секционирования является дата/время события. В нашем случае таким событием является момент отправки сообщения.
Заметим, что пользователи практически всегда работают только с «последними» такими данными — читают последние сообщения, анализируют последние логи,… Нет, конечно, они могут пролистать и дальше назад во времени, только делают это очень редко.
Из этих ограничений становится очевидно, что оптимальным решением для сообщений будут «посуточные» секции — ведь почти всегда наш пользователь будет читать то, что пришло ему «сегодня» или «вчера».
Если мы в течение дня пишем и читаем практически только в одну секцию, то это дает нам еще и более эффективное использование памяти и диска — поскольку все индексы секции легко умещаются в оперативку, в отличие от «больших и жирных» по всей таблице.
step-by-step
В общем, все сказанное выше звучит как один сплошной профит. И он достижим, но ради этого нам придется хорошо постараться — потому что решение секционировать одну из сущностей приводит к необходимости «распиливать» и связанные с ней.
Сообщение, его свойства и проекции
Раз мы решили порезать сообщения по датам, то и зависимые от них сущности-свойства (приложенные файлы, список адресатов) разумно тоже делить, и тоже по дате сообщения.
Поскольку одной из типовых наших задач является как раз просмотр реестров сообщений (непрочитанные, входящие, все), то их тоже логично «втянуть» в секционирование по датам сообщений.

Добавляем ключ секционирования (дату сообщения) во все таблицы: адресаты, файл, реестры. В само сообщение можно не добавлять, а использовать существующее ДатаВремя.
Темы
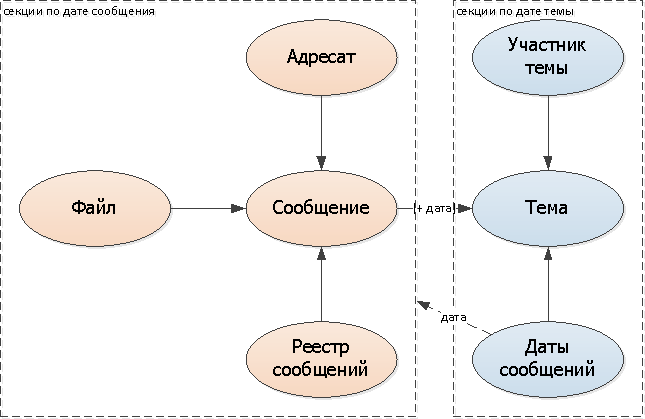
Поскольку тема одна на несколько сообщений, то ее «порезать» в той же модели уже никак не получится, надо опираться на что-то другое. В нашем случае идеально подходит дата первого сообщения в переписке — то есть момент создания, собственно, темы.

Добавляем ключ секционирования (дату темы) во все таблицы: тема, участник.
Но теперь у нас возникают сразу две проблемы:
- в какой секции искать сообщения по теме?
- в какой секции искать тему от сообщения?
Можно, конечно, продолжать искать по всем секциям, но это будет очень печально, и сведет на нет все наши выигрыши. Поэтому, чтобы знать, где конкретно искать, сделаем логические ссылки/указатели на секции:
- в сообщении добавим поле с датой темы
- к теме добавим набор дат сообщений этой переписки (можно отдельной таблицей, а можно и массивом дат)

Поскольку модификаций списка дат сообщений для каждой отдельно взятой переписки будет немного (ведь почти все сообщения попадают в 1-2 соседних дня), я остановлюсь именно на таком варианте.
Итого, структура нашей базы приняла следующий вид с учетом секционирования:
Таблицы : RU, при отвращении к кириллице в названиях таблиц/полей лучше не смотреть
-- секции по дате сообщения
CREATE TABLE "Сообщение_YYYYMMDD"(
"Сообщение"
uuid
PRIMARY KEY
, "Тема"
uuid
, "ДатаТемы"
date
, "Автор"
uuid
, "ДатаВремя" -- используем как дату
timestamp
, "Текст"
text
);
CREATE TABLE "Адресат_YYYYMMDD"(
"ДатаСообщения"
date
, "Сообщение"
uuid
, "Персона"
uuid
, PRIMARY KEY("Сообщение", "Персона")
);
CREATE TABLE "Файл_YYYYMMDD"(
"ДатаСообщения"
date
, "Файл"
uuid
PRIMARY KEY
, "Сообщение"
uuid
, "BLOB"
uuid
, "Имя"
text
);
CREATE TABLE "РеестрСообщений_YYYYMMDD"(
"ДатаСообщения"
date
, "Владелец"
uuid
, "ТипРеестра"
smallint
, "ДатаВремя"
timestamp
, "Сообщение"
uuid
, PRIMARY KEY("Владелец", "ТипРеестра", "Сообщение")
);
CREATE INDEX ON "РеестрСообщений_YYYYMMDD"("Владелец", "ТипРеестра", "ДатаВремя" DESC);
-- секции по дате темы
CREATE TABLE "Тема_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Документ"
uuid
, "Название"
text
);
CREATE TABLE "УчастникТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
, "Персона"
uuid
, PRIMARY KEY("Тема", "Персона")
);
CREATE TABLE "ДатыСообщенийТемы_YYYYMMDD"(
"ДатаТемы"
date
, "Тема"
uuid
PRIMARY KEY
, "Дата"
date
);
Экономим копеечку
Ну, а если мы используем не классический вариант секционирования на основе распределения значений поля (через триггеры и наследование или PARTITION BY), а «вручную» на уровне приложения, то можно заметить, что значение ключа секционирования уже хранится в названии самой таблицы.
Поэтому если вы настолько сильно переживаете за объем хранимых данных, то от этих «лишних» полей можно и избавиться и обращаться адресно к конкретным таблицам. Правда, все выборки из нескольких секций в этом случае уже придется вынести на сторону приложения.
