
Всем привет! Меня зовут Сергей Костанбаев, на Бирже я занимаюсь разработкой ядра торговой системы.
Когда в голливудских фильмах показывают Нью-Йоркскую фондовую биржу, это всегда выглядит так: толпы людей, все что-то орут, машут бумажками, творится полный хаос. У нас на Московской бирже такого никогда не было, потому что торги почти с самого начала ведутся электронно и базируются на двух основных платформах — Spectra (срочный рынок) и ASTS (валютный, фондовый и денежный рынок). И сегодня хочу рассказать об эволюции архитектуры торгово-клиринговой системы ASTS, о различных решениях и находках. Рассказ будет длинный, так что пришлось разбить его на две части.
Мы одна из немногих бирж мира, на которых проводятся торги активами всех классов и предоставляется полный спектр биржевых услуг. К примеру, в прошлом году мы занимали второе место в мире по объёму торгов облигациями, 25 место среди всех фондовых бирж, 13 место по капитализации среди публичных бирж.
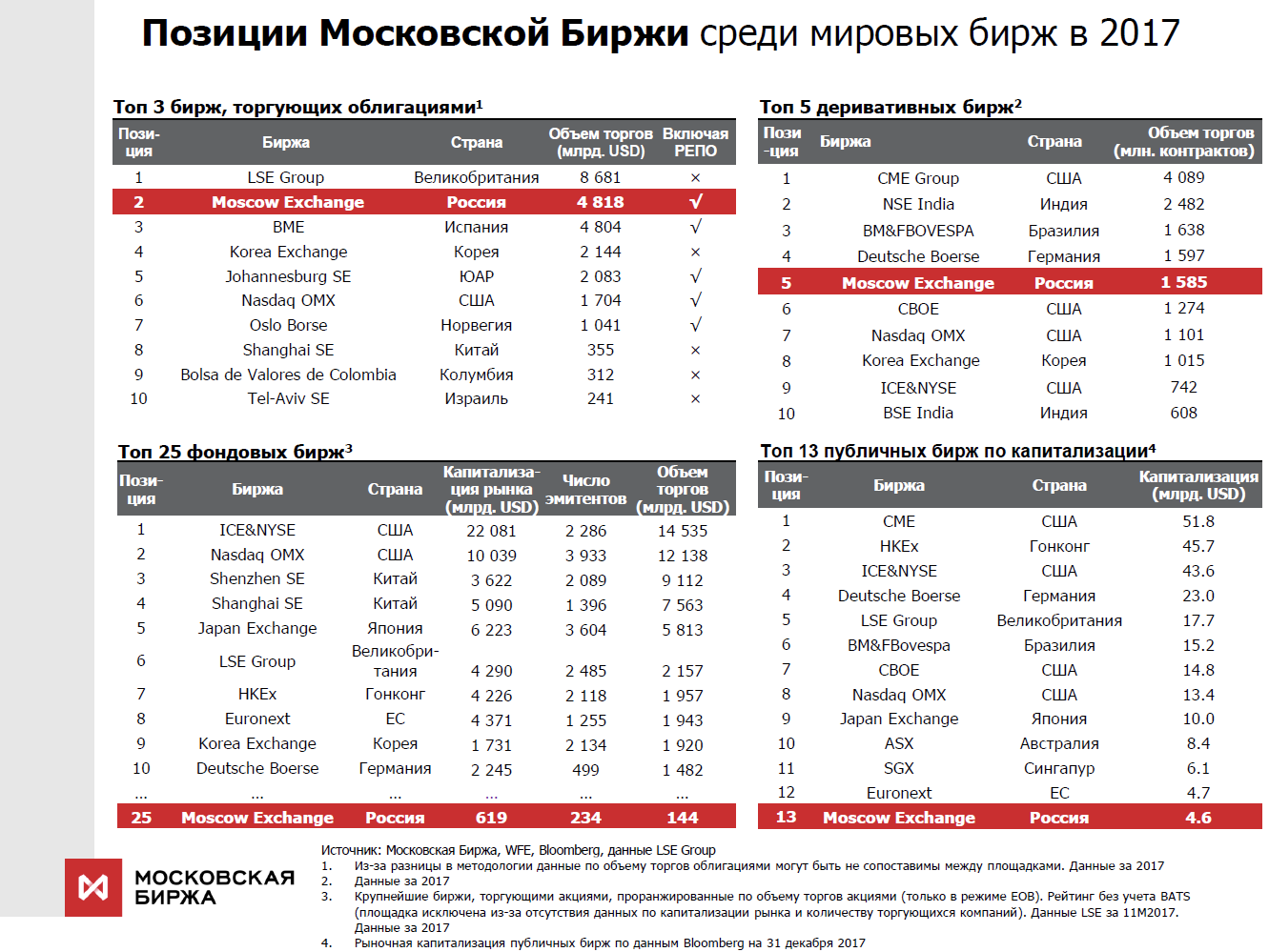
Для профессиональных участников торгов критичны такие параметры, как время отклика, стабильность распределения времён (джиттер) и надёжность всего комплекса. На текущий момент мы обрабатываем десятки миллионов транзакций в день. Обработка каждой транзакции ядром системы занимает десятки микросекунд. Конечно, у сотовых операторов под Новый год или у поисковиков нагруженность сама по себе выше нашей, но вот по нагруженности вкупе с вышеупомянутыми характеристиками с нами мало кто может сравниться, как мне кажется. При этом нам важно, чтобы система ни на секунду не подтормаживала, работала абсолютно стабильно, и все пользователи находились в равных условиях.
Немножко истории
В 1994 году на Московской межбанковской валютной бирже (ММВБ) была запущена австралийская система ASTS, и с этого момента можно отсчитывать российскую историю электронных торгов. В 1998 году архитектуру биржи модернизировали ради внедрения интернет-трейдинга. С тех пор скорость внедрения новых решений и архитектурных изменений во всех системах и подсистемах только набирает обороты.
В те годы биржевая система работала на hi-end железе — сверхнадёжных серверах HP Superdome 9000 (построенных на архитектуре PA-RISC), у которых дублировалось абсолютно всё: подсистемы ввода-вывода, сеть, оперативная память (фактически, был RAID-массив из RAM), процессоры (поддерживалась горячая замена). Можно было поменять любой компонент сервера без остановки машины. Мы полагались на эти устройства, считали их фактически безотказными. В роли операционной системы выступала Unix-подобная система HP UX.
Но примерно с 2010 года возникло такое явление, как high-frequency trading (HFT), или высокочастотная торговля — попросту говоря, биржевые роботы. Всего за 2,5 года нагрузка на наши серверы увеличилась в 140 раз.
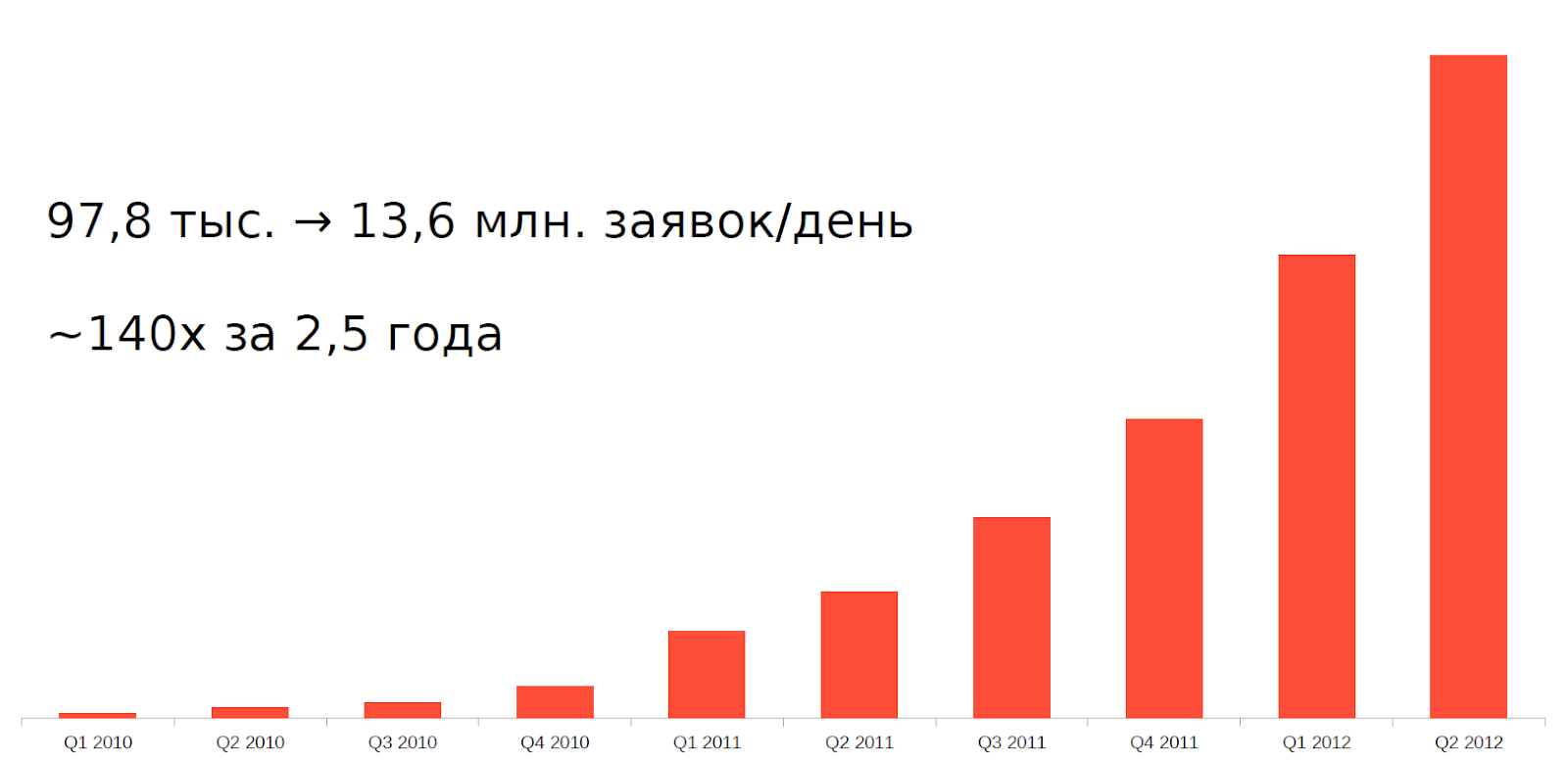
Выдерживать такую нагрузку со старой архитектурой и оборудованием было невозможно. Нужно было как-то адаптироваться.
Начало
Запросы к биржевой системе можно разделить на два типа:
- Транзакции. Если вы хотите купить доллары, акции или что-то ещё, то отправляете в торговую систему транзакцию и получаете ответ об успешности.
- Информационные запросы. Если вы хотите узнать текущую цену, посмотреть книгу заявок или индексы, то отправляете информационные запросы.
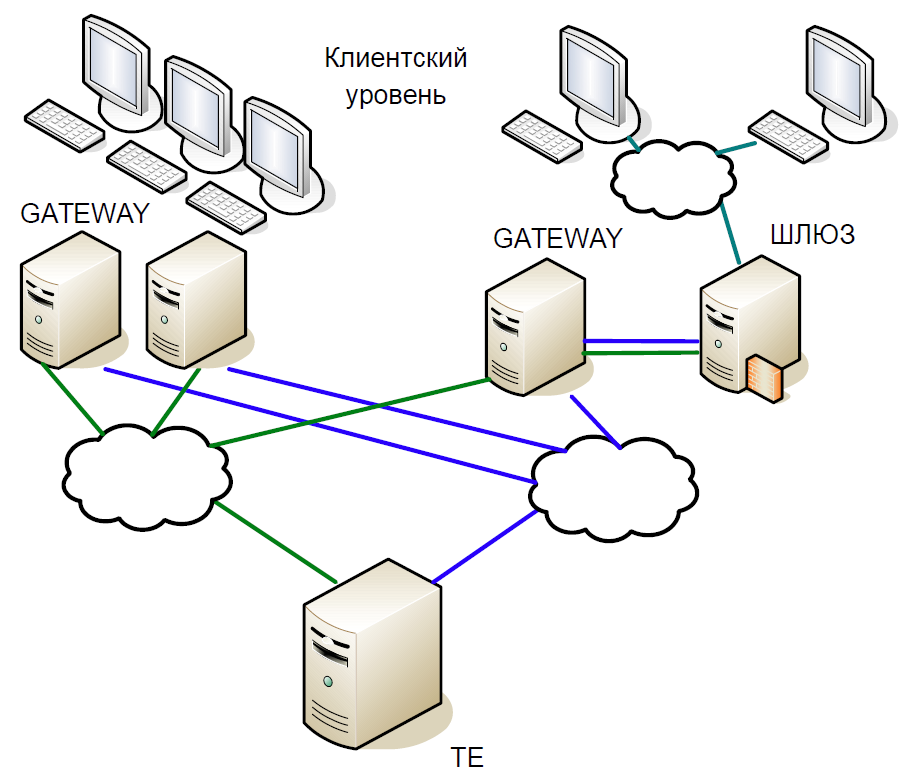
Схематично ядро системы можно разделить на три уровня:
- Клиентский уровень, на котором работают брокеры, клиенты. Все они взаимодействуют с серверами доступа.
- Серверы доступа (Gateway) — это кэширующие серверы, которые локально обрабатывают все информационные запросы. Хотите узнать, по какой цене сейчас торгуются акции «Сбербанка»? Запрос уходит на сервер доступа.
- Но если вы хотите купить акции, то запрос идёт уже на центральный сервер (Trade Engine). Таких серверов по одному на каждый вид рынка, они играют важнейшую роль, именно ради них мы и создавали данную систему.
Ядро торговой системы представляет собой хитрую in-memory базу данных, в которой все транзакции — это биржевые транзакции. База была написана на С, из внешних зависимостей имелась только библиотека libc и полностью отсутствовало динамическое выделение памяти. Чтобы уменьшить время обработки, система запускается со статическим набором массивов и со статической релокацией данных: сначала все данные на текущий день загружаются в память, и дальше обращений к диску не выполняется, вся работа ведётся только в памяти. При запуске системы все справочные данные уже отсортированы, поэтому поиск работает очень эффективно и занимают мало времени в runtime. Все таблицы сделаны с интрузивными списками и деревьями для динамических структур данных, чтобы они не требовали выделения памяти в runtime.
Давайте вкратце пробежимся по истории развития нашей торгово-клиринговой системы.
Первая версия архитектуры торгово-клиринговой системы была построена на так называемом Unix-взаимодействии: применялись разделяемая память, семафоры и очереди, а каждый процесс состоял из одного потока. Этот подход был широко распространён в начале 1990-х.
Первая версия системы содержала два уровня Gateway и центральный сервер торговой системы. Схема работы была такая:
- Клиент отправляет запрос, который попадает на Gateway. Тот проверяет валидность формата (но не самих данных) и отвергает неправильные транзакции.
- Если был отправлен информационный запрос, то он исполняется локально; если речь идёт о транзакции, то она перенаправляется на центральный сервер.
- Затем торговый движок обрабатывает транзакцию, изменяет локальную память и отправляет ответ на транзакцию, а её саму — на репликацию с помощью отдельного механизма репликации.
- Gateway получает от центрального узла ответ и перенаправляет его клиенту.
- Через некоторое время Gateway получает транзакцию по репликационному механизму, и в этот раз он исполняет её локально, изменяя свои структуры данных, чтобы следующие информационные запросы отображали актуальные данные.
Фактически, здесь описана репликационная модель, в которой Gateway полностью повторял действия, выполняемые в торговой системе. Отдельный канал репликации обеспечивал один и тот же порядок исполнения транзакций на множестве узлов доступа.
Поскольку код был однопоточным, для обслуживания множества клиентов использовалась классическая схема с fork-ами процессов. Однако делать fork для всей базы данных было очень накладно, поэтому применялись легковесные процессы-сервисы, которые собирали пакеты из TCP-сессий и перекладывали их в одну очередь (SystemV Message Queue). Gateway и Trade Engine работали только с этой очередью, забирая оттуда транзакции на исполнение. Отправить в неё ответ уже было нельзя, потому что непонятно, какой сервис-процесс должен его прочитать. Так что мы прибегли к уловке: каждый fork-нутый процесс создавал для себя очередь ответов, и когда во входящую очередь приходил запрос, к нему сразу добавлялся тег для очереди ответов.
Постоянное копирование из очереди в очередь больших объёмов данных создавало проблемы, особенно характерные для информационных запросов. Поэтому мы воспользовались ещё одним трюком: кроме очереди ответов каждый процесс создавал также и общую память (SystemV Shared Memory). В неё помещались сами пакеты, а в очереди сохранялся только тег, позволяющий найти исходный пакет. Это помогло сохранять данные в кэш-памяти процессора.
SystemV IPC включает в себя утилиты для просмотра состояния объектов очередей, памяти и семафоров. Мы активно этим пользовались, чтобы понимать, что происходит в системе в конкретный момент, где скапливаются пакеты, что находится в блокировке и т. П.
Первые модернизации
В первую очередь мы избавились от однопроцессового Gateway. Его существенным недостатком было то, что он мог обрабатывать либо одну репликационную транзакцию, либо один информационный запрос от клиента. И с ростом нагрузки Gateway будет всё дольше обрабатывать запросы и не сможет обрабатывать репликационный поток. К тому же, если клиент отправил транзакцию, то нужно только проверить её валидность и переадресовать дальше. Поэтому мы заменили один процесс Gateway на множество компонентов, которые могут работать параллельно: многопоточные информационные и транзакционные процессы, работающие независимо друг от друга с общей областью памяти с применением RW-блокировки. И заодно внедрили процессы диспетчеризации и репликации.
Влияние высокочастотной торговли
Вышеописанная версия архитектуры просуществовала вплоть до 2010 года. Тем временем нас уже перестала удовлетворять производительность серверов HP Superdome. К тому же архитектура PA-RISC фактически умерла, вендор не предлагал никаких существенных обновлений. В результате мы стали переходить с HP UX/PA RISC на Linux/x86. Переход начался с адаптации серверов доступа.
Почему нам снова пришлось менять архитектуру? Дело в том, что высокочастотная торговля значительно изменила профиль нагрузки на ядро системы.
Допустим, у нас есть небольшая транзакция, которая вызвала значительное изменение цены — кто-то купил полмиллиарда долларов. Спустя пару миллисекунд все участники рынка это замечают и начинают давать коррекцию. Естественно, запросы выстраиваются в огромную очередь, которую система будет долго разгребать.

На этом интервале в 50 мс средняя скорость составляет около 16 тыс. транзакций в секунду. Если уменьшить окно до 20 мс, то получим среднюю скорость уже 90 тыс. транзакций в секунду, причём на пике будет 200 тыс. транзакций. Иными словами, нагрузка непостоянная, с резкими всплесками. А очередь запросов нужно всегда обрабатывать быстро.
Но почему вообще возникает очередь? Итак, в нашем примере множество пользователей заметили изменение цены и отправляют соответствующие транзакции. Те приходят в Gateway, он их сериализует, задаёт некий порядок и отправляет в сеть. Маршрутизаторы перемешивают пакеты и отправляют их дальше. Чей пакет пришёл раньше, та транзакция и «выиграла». В результате клиенты биржи стали замечать, что если одну и ту же транзакцию отправлять с нескольких Gateway, то шансы на её быструю обработку возрастают. Вскоре биржевые роботы начали забрасывать Gateway запросами, и возникла лавина транзакций.

Новый виток эволюции
После длительного тестирования и исследований мы перешли на real-time ядро операционной системы. Для этого выбрали RedHat Enterprise MRG Linux, где MRG расшифровывается как messaging real-time grid. Преимущество real-time-патчей в том, что они оптимизируют систему под максимально быстрое исполнение: все процессы выстраиваются в FIFO-очередь, можно изолировать ядра, никаких выбрасываний, все транзакции обрабатываются в строгой последовательности.
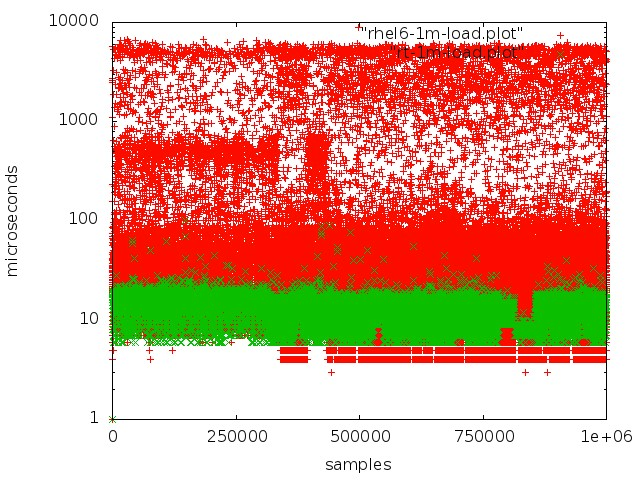
Красный — работа с очередью в обычном ядре, зеленый — работа в real-time ядре.
Но достичь низкого уровня задержки на обычных серверах не так просто:
- Сильно мешает режим SMI, который в архитектуре x86 лежит в основе работы с важной периферией. Обработка всевозможных аппаратных событий и управление компонентами и устройствами выполняется прошивкой в так называемом прозрачном SMI-режиме, при котором операционная система вообще не видит, что делает прошивка. Как правило, все крупные вендоры предлагают специальные расширения для firmware-серверов, позволяющие уменьшить объём SMI-обработки.
- Не должно быть динамического управления частотой процессора, это приводит к дополнительному простою.
- Когда сбрасывается журнал файловой системы, в ядре возникают некие процессы, которые приводят к непредсказуемым задержкам.
- Нужно обращать внимание на такие вещи, как CPU Affinity, Interrupt affinity, NUMA.
Надо сказать, тема настройки железа и ядра Linux под realtime-обработку заслуживает отдельной статьи. Мы много времени потратили на эксперименты и исследования, прежде чем достигли хорошего результата.
При переходе с PA-RISC-серверов на x86 нам практически не пришлось сильно изменять код системы, мы лишь адаптировали и перенастроили её. Заодно поправили несколько багов. Например, быстро всплыли последствия того, что PA RISC являлась Big endian-системой, а x86 — Little endian: например, неправильно считывались данные. Более хитрый баг заключался в том, что PA RISC использует последовательно консистентный (Sequential consistent) доступ к памяти, тогда как x86 может переупорядочивать операции на чтение, поэтому код, абсолютно валидный на одной платформе, стал нерабочим на другой.
После перехода на х86 производительность выросла почти в три раза, средняя длительность обработки транзакции снизилась до 60 мкс.
Давайте теперь подробнее рассмотрим, какие ключевые изменения были внесены в архитектуру системы.
Эпопея с горячим резервированием
Переходя на commodity-серверы мы отдавали себе отчёт, что они менее надёжны. Поэтому при создании новой архитектуры мы априори предполагали возможность выхода из строя одного или нескольких узлов. Поэтому нужна была система горячего резервирования, способная очень быстро переключиться на резервные машины.
Кроме того, были и другие требования:
- Нельзя ни в коем случае терять обработанные транзакции.
- Система должна быть абсолютно прозрачной для нашей инфраструктуры.
- Клиенты не должны видеть разрывы соединений.
- Резервирование не должно вносить существенную задержку, потому что это критический фактор для биржи.
При создании системы горячего резервирования мы не рассматривали такие сценарии, как двойные отказы (например, перестала работать сеть на одном сервере и завис основной сервер); не рассматривали возможность ошибок в ПО, потому что они выявляются в ходе тестирования; и не рассматривали неправильную работу железа.
В результате мы пришли к следующей схеме:
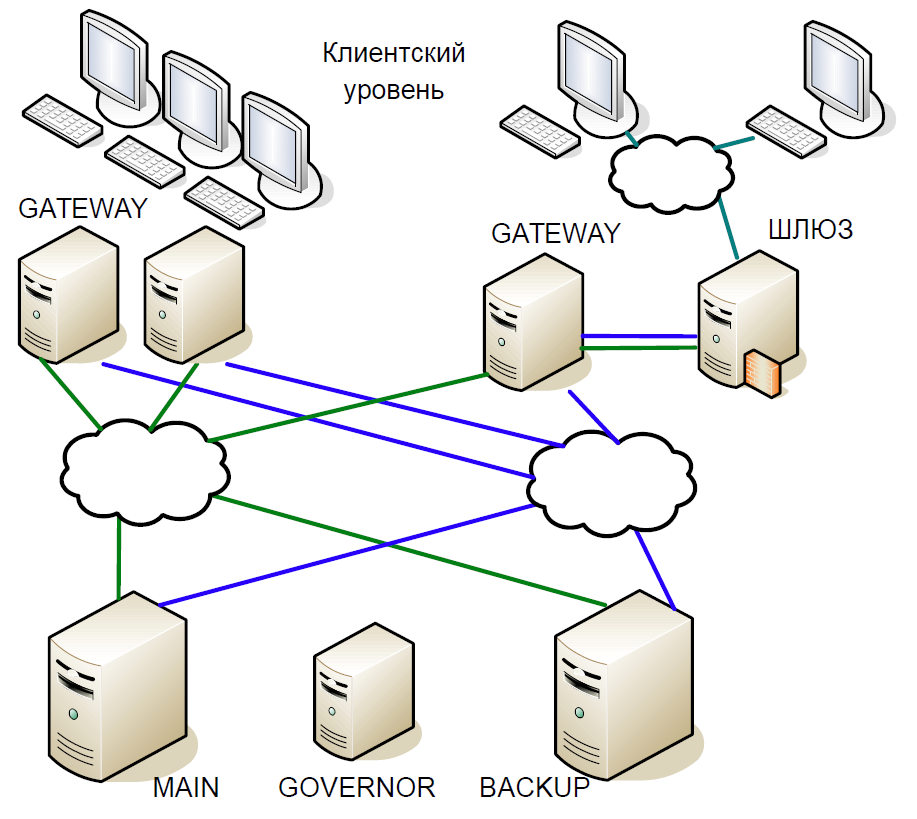
- Главный сервер непосредственно взаимодействовал с серверами Gateway.
- Все транзакции, поступавшие на главный сервер, моментально реплицировались на резервный сервер по отдельному каналу. Арбитр (Governor) координировал переключение при возникновении каких-либо проблем.
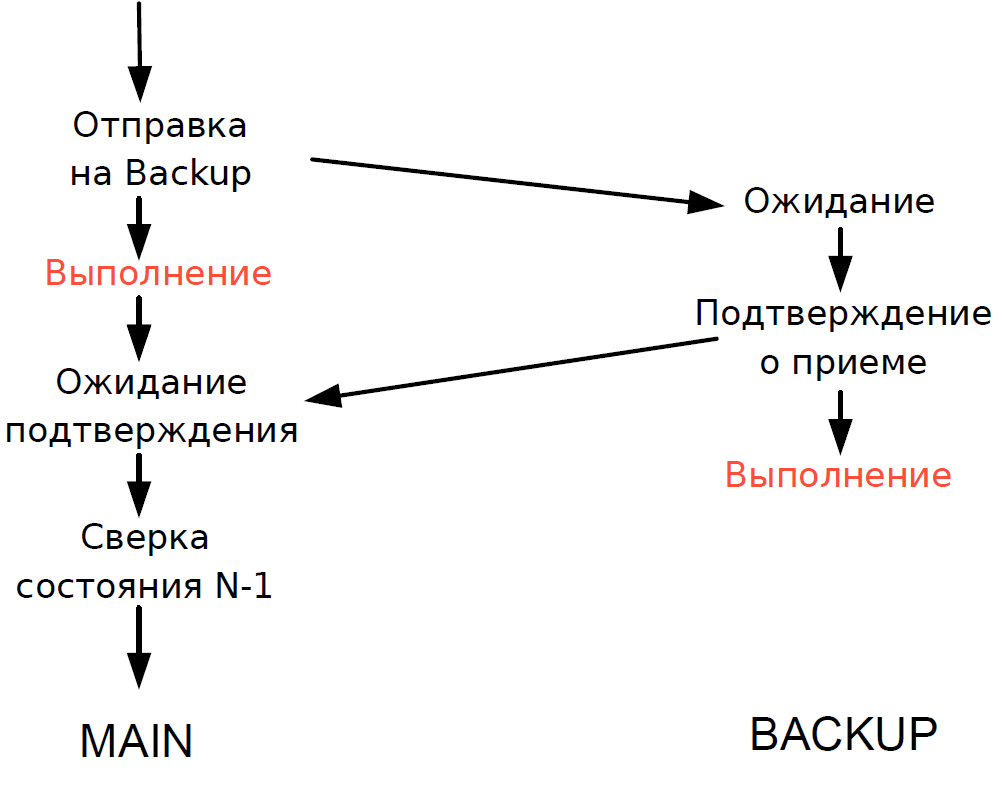
- Главный сервер обрабатывал каждую транзакцию и ожидал подтверждения от резервного сервера. Чтобы задержка была минимальной, мы отказались от ожидания выполнения транзакции на резервном сервере. Поскольку длительность перемещения транзакции по сети была сравнима с длительностью выполнения, дополнительной задержки не прибавлялось.
- Сверять состояние обработки главным и резервным сервером мы могли только для предыдущей транзакции, а статус обработки текущей транзакции был неизвестен. Поскольку здесь всё ещё использовались однопоточные процессы, ожидание ответа от Backup затормозило бы весь поток обработки, и поэтому мы пошли на разумный компромисс: сверяли результат предыдущей транзакции.
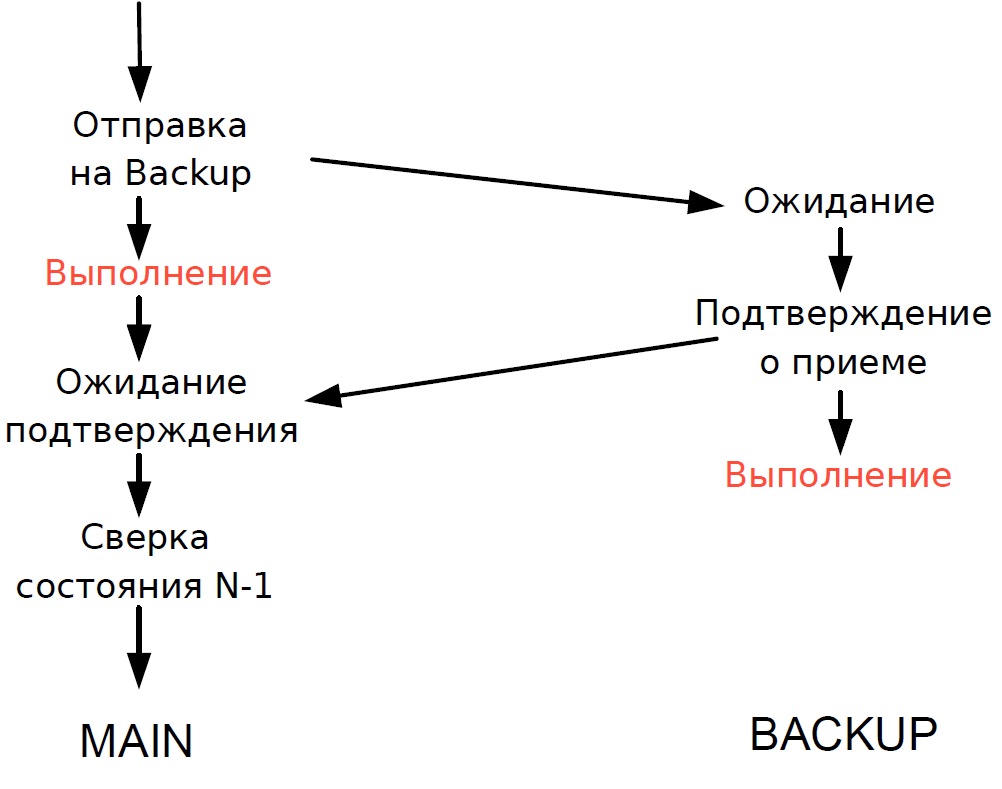

Схема работала следующим образом.
Допустим, главный сервер перестал отвечать, но Gateway продолжают взаимодействовать. На резервном сервере срабатывает таймаут, он обращается к Governor, а тот назначает ему роль главного сервера, и все Gateway переключаются на новый главный сервер.
Если главный сервер снова входит в строй, на нём тоже срабатывает внутренний таймаут, потому что в течение определённого времени к серверу не было обращений от Gateway. Тогда он тоже обращается к Governor, и тот исключает его из схемы. В результате биржа до конца торгового периода работает с одним сервером. Поскольку вероятность выхода сервера из строя достаточно низкая, такая схема считалась вполне приемлемой, она не содержала сложной логики и легко тестировалась.
Продолжение следует.
