

Это продолжение практикума по развертыванию Kubernetes-кластера на базе облака Mail.ru Cloud Solutions и созданию MVP для реального приложения, выполняющего транскрибацию видеофайлов из YouTube.
Я Василий Озеров, основатель агентства Fevlake и действующий DevOps-инженер (опыт в DevOps — 8 лет), покажу все этапы разработки Cloud-Native приложений на K8s: от запуска кластера до построения CI/CD и разработки собственного Helm-чарта.
Напомню, что в первой части статьи мы выбрали архитектуру приложения, написали API-сервер, запустили Kubernetes c балансировщиком и облачными базами, развернули кластер RabbitMQ через Helm в Kubernetes. Сейчас во второй части мы настроим и запустим приложение для преобразования аудио в текст, сохраним результат и настроим автомасштабирование нод в кластере.
Также запись практикума можно посмотреть: часть 1, часть 2, часть 3.
Кодирование обработчиков Worker на Python
Теперь нам необходимо написать код для конвертеров (Worker), которые будут получать сообщения из очереди RabbitMQ для последующей обработки. В их задачи будет входить загрузка видео, извлечение из него аудио, преобразование аудио в текст и сохранение полученной расшифровки в бакет S3. В качестве языка программирования будем использовать Python. Репозиторий с кодом доступен по ссылке.
Рассмотрим файл worker.py. Сначала импортируем стандартные системные модули os, sys, time, logging, а также модули для работы с JSON (json), HTTP (requests), RabbitMQ (pika) и Environment-переменными (Env). Чтобы не писать собственный парсер для загрузки видео с Youtube, будем использовать библиотеку youtube_dl. Для отправки файлов в S3 подключим модуль boto3:
# System modules
import json
import os
import sys
import time
import logging
import subprocess
# Third party modules
import pika
import requests
from environs import Env
import youtube_dl
import boto3
from urllib import parseДалее читаем переменные из конфигурационного файла .env, который будет размещаться в директории с нашим приложением. При этом подкладывать его туда в дальнейшем будет Kubernetes при помощи configMap — жестко прописывать файл в Docker-образе мы не будем:
## read config
env = Env()
env.read_env() # read .env file, if it exists
rabbitmq_host = env("RABBIT_HOST", 'localhost')
rabbitmq_port = env("RABBIT_PORT", 5672)
rabbitmq_user = env("RABBIT_USER")
rabbitmq_pass = env("RABBIT_PASS")
rabbitmq_queue = env("RABBIT_QUEUE", "AutoUrlTemplateQueue")
api_url = env("API_URL")
api_key = env("API_KEY")
s3_endpoint = env("S3_ENDPOINT")
s3_web = env("S3_WEB")
s3_access_key = env("S3_ACCESS_KEY")
s3_secret_key = env("S3_SECRET_KEY")
s3_bucket = env("S3_BUCKET")Пройдемся по переменным:
RABBIT_HOST, RABBIT_PORT, RABBIT_USER, RABBIT_PASS и RABBIT_QUEUE нужны для взаимодействия с RabbitMQ.
API_URL и API_KEY — для отправки статуса обработки видео на API-сервер.
S3_ENDPOINT — Endpoint для подключения к S3: переменную необходимо заполнить, если используется отличное от AWS хранилище.
S3_WEB описывает URL для загрузки итоговых текстовых файлов с расшифровкой видео.
S3_ACCESS_KEY, S3_SECRET_KEY и S3_BUCKET — это ключи доступа и ссылка на бакет S3, в котором будут храниться файлы.
Далее подключаемся к RabbitMQ и создаем клиента S3:
# Connecting to rabbitmq
credentials = pika.PlainCredentials(rabbitmq_user, rabbitmq_pass)
connection = pika.BlockingConnection(pika.ConnectionParameters(rabbitmq_host, rabbitmq_port, '/', credentials))
channel = connection.channel()
s3client = boto3.client('s3', endpoint_url=s3_endpoint, aws_access_key_id = s3_access_key, aws_secret_access_key = s3_secret_key)Настраиваем логирование для вывода сообщений в заданном формате:
# Setting logger
logging.basicConfig(
format='%(asctime)s | %(levelname)-7s | %(name)-12s | %(message)s',
datefmt='%d-%b-%y %H:%M:%S',
level=logging.INFO
)
logger = logging.getLogger(__name__)И после этого запускаем чтение сообщений из очереди, указывая process_event в качестве функции-обработчика и отключая Auto Acknowledgement (auto_ack=false). То есть мы не подтверждаем сообщение автоматически, а будем ждать логического завершения операции, чтобы в случае ошибок попробовать обработать сообщение повторно. При вызове channel.start_consuming приложение подключается к RabbitMQ и начинает ждать новых сообщений в очереди. В случае нажатия Ctrl+C выполнение прервется с кодом sys.exit(0):
# Starting consuming rabbitmq queue
logger.info('Waiting for messages. To exit press CTRL+C')
channel.basic_consume(queue=rabbitmq_queue, on_message_callback=process_event, auto_ack=False)
try:
channel.start_consuming()
except KeyboardInterrupt:
logger.info('Interrupted')
try:
sys.exit(0)
except SystemExit:
os._exit(0)Теперь рассмотрим логику основной функции process_event. Вначале мы логируем поступление нового сообщения из RabbitMQ и запускаем таймер для отсчета времени обработки. Далее получаем JSON из тела сообщения и парсим его, извлекая две переменные: уникальное название запроса (name) и ссылку на Youtube-видео, которое нам необходимо загрузить (video_url). Логируем результат парсинга:
# Processing event from rabbit and sending to internal queue
def process_event(ch, method, properties, body):
logger.info("Got new message from rabbitmq %r" % body)
t_start = time.time()
# Parsing data
event = json.loads(body)
name = event['name']
video_url = event['video_url']
logger.info("Got name: " + str(name) + ", video_url: " + str(video_url))Перед загрузкой удаляем ранее созданные временные файлы с расширением .wav:
# Removing audio.wav before downloading
os.chdir("/app")
filelist = [ f for f in os.listdir("/app") if f.endswith(".wav") ]
for f in filelist:
os.remove(os.path.join("/app", f))В следующем блоке загружаем видео с YouTube, используя YouTube Downloader (youtube_dl).
При загрузке будет использоваться набор опций ydl_opts. Так как нас интересует только аудио, отключаем сохранение видео (keepvideo: False). В блоке postprocessors выбираем FFmpeg, кодек wav и quality 192 для конвертации файла. В блоке postprocessor_args указываем rate, равный 16 кГц, и количество каналов аудио, равное 1.
На YouTube практически все видео stereo, но нам обязательно нужно mono, так как софт, который будет переводить речь в текст, работает только с mono-аудиофайлами. В поле outtmpl вводим шаблон для имени сохраняемого файла: <ID видео, которое мы передали>.<расширение (wav)>.
Загрузка запускается с помощью функции ydl.download с указанием video_url, который мы в самом начале получили из сообщения RabbitMQ. При любом сбое во время загрузки файла в лог запишется сообщение «Can’t download audio file», а в API отправится информация «Error downloading video». И при получении статуса обработки видео клиент увидит это сообщение:
# Downloading video
ydl_opts = {
'format': 'bestaudio/best',
'postprocessors': [{
'key': 'FFmpegExtractAudio',
'preferredcodec': 'wav',
'preferredquality': '192'
}],
'postprocessor_args': [
'-ar', '16000', '-ac', '1'
],
'prefer_ffmpeg': True,
'keepvideo': False,
'outtmpl': '%(id)s.%(ext)s'
}
try:
with youtube_dl.YoutubeDL(ydl_opts) as ydl:
ydl.download([video_url])
except:
logger.error("Can't download audio file, sending callback")
headers = {"X-API-KEY": api_key}
payload = {"processed": True, "text_url": "Error downloading video"}
r = requests.put(api_url + '/requests/' + name, data=json.dumps(payload), headers=headers)
logger.info("Callback sent, response code: " + str(r.status_code))
returnСледующий шаг – конвертация аудио в текст. Для этой цели будем использовать Leopard от компании Picovoice. Leopard читает wav-файл на английском языке и переводит его в текст. Он работает полностью локально без обращения к каким-то внешним API. Инструмент платный, но для домашнего использования есть 30-дневный триал. Для перевода текста в real-time режиме у этого же разработчика есть программа Cheetah.
Перед использованием Leopard необходимо скомпилировать. На странице в GitHub есть инструкция: предлагается использовать GNU C Compiler (GCC) и создать бинарник из исходника на C.
Мы запускаем Leopard, указывая в параметрах путь к библиотеке C, к акустическим моделям, к языковым моделям, а также лицензионный файл (его можно получить на официальном сайте Picovoice) и wav-файл. После этого в stdout получаем транскрипт аудио в текст. В случае сбоев в обработке, как и на предыдущем шаге, выполняем логирование и отправку соответствующего callback через API:
# Converting audio to text
logger.info("Converting audio to text")
try:
p = subprocess.Popen("/app/leopard/leopard_demo
leopard/lib/linux/x86_64/libpv_leopard.so
leopard/lib/common/acoustic_model.pv leopard/lib/common/language_model.pv license.lic *.wav", stdout=subprocess.PIPE, shell=True)
(output, err) = p.communicate()
p_status = p.wait()
logger.info("Command output : " + str(output))
logger.info("Command exit status/return code : " + str(p_status))
except:
logger.error("Can't convert audio to text, sending callback")
headers = {"X-API-KEY": api_key}
payload = {"processed": True, "text_url": "Error converting audio"}
r = requests.put(api_url + '/requests/' + name, data=json.dumps(payload), headers=headers)
logger.info("Callback sent, response code: " + str(r.status_code))
returnИ далее загружаем наш транскрипт, сохраненный в output, на S3. Название бакета берем из environment-переменной S3_BUCKET. Путь к файлу будет иметь следующий вид: <URL бакета из переменной S3_WEB>/converted/<name исходного запроса>.txt. В ACL необходимо обязательно установить public-read, чтобы все могли прочесть файл:
# Uploading file to s3
try:
s3client.put_object(Body=output, Bucket=s3_bucket, Key='converted/' + name + '.txt', ACL='public-read')
except:
logger.error("Can't upload text to s3, sending callback")
headers = {"X-API-KEY": api_key}
payload = {"processed": True, "text_url": "Error uploading to s3"}
r = requests.put(api_url + '/requests/' + name, data=json.dumps(payload), headers=headers)
logger.info("Callback sent, response code: " + str(r.status_code))
returnПосле этого мы отправляем информацию в API об успешной обработке файла, сообщая URL, по которому можно загрузить файл из S3:
# Sending callback to API
headers = {"X-API-KEY": api_key}
payload = {"processed": True, "text_url": s3_web + "/converted/" + name}
r = requests.put(api_url + '/requests/' + name, data=json.dumps(payload), headers=headers)
logger.info("Callback sent, response code: " + str(r.status_code))В конце выводим время обработки и отправляем подтверждение в очередь:
t_elapsed = time.time() - t_start
logger.info("Finished with " + video_url + " in " + str(t_elapsed) + " seconds")
ch.basic_ack(delivery_tag = method.delivery_tag)В завершение рассмотрим Dockerfile. Мы берем Python 3.9, создаем директорию «/app» и переходим в нее. Устанавливаем ffmpeg, который будет использоваться для конвертации файлов, загруженных с Youtube. Клонируем репозиторий с Leopard, переходим в папку с ним, компилируем и возвращаемся обратно. После этого копируем файл requirements.txt, описывающий зависимости в Python: soundfile, youtube_dl, pika, boto, numpy. Устанавливаем их. И далее копируем все остальные файлы:
FROM python:3.9
WORKDIR "/app"
RUN apt update && apt-get install -y ffmpeg
RUN git clone https://github.com/Picovoice/leopard && cd leopard && gcc -I include/ -O3 demo/c/leopard_demo.c -ldl -o leopard_demo && cd ..
COPY requirements.txt requirements.txt
RUN pip3 install -r requirements.txt
COPY . .Настройка переменных окружения и создание бакета S3
Далее необходимо прописать environment-переменные в .env файле:
API_URL = "http://video-api-svc.stage.svc:8080"
API_KEY = "804b95f13b714ee9912b19861faf3d25"
RABBIT_HOST = "rabbitmq.stage.svc"
RABBIT_USER = "user"
RABBIT_PASS = "6NvlZY77Fu"
RABBIT_QUEUE = "VideoParserWorkerQueue"
S3_ENDPOINT = "http://hb.bizmrg.com/"
S3_SECRET_KEY = "6qg2TaFo3tq9L93mNkd959Kw7YxPEp7iyybK4FsXw9T8"
S3_ACCESS_KEY = "fAFSLdYjNKVEdEh2Vs27vc"
S3_BUCKET = "converted"
S3_WEB = "http://converted.hb.bizmrg.com"Впоследствии все критичные переменные мы зашифруем и будем хранить в секретах. Пока остановимся на том, откуда для них брать значения.
API_KEY у нас был прописан в main.go, оставляем его. Для получения API_URL и RABBIT_HOST выведем сервисы в Kubernetes-кластере.
Команда kubectl –n stage get svc возвращает внутренние сервисы в Namespace stage:

Команда kubectl –n stage get ing позволяет посмотреть их внешние API:

Так как мы будем запускать конвертер внутри кластера, то нам достаточно внутренних адресов. Итоговое имя хоста формируется по маске <NAME из вывода первой команды>.<Namespace (в нашем случае stage)>.svc.
Далее в переменных RABBIT_USER, RABBIT_PASS, RABBIT_QUEUE указываются пользователь, пароль и название очереди в RabbitMQ.
Затем идут настройки для подключения к S3. На них остановимся подробнее. Вначале создадим бакет S3 в облаке MCS. Для этого выберем команду «Создать бакет» в пункте меню «Объектное хранилище». В качестве названия бакета укажем converted (скопировав его в переменную S3_BUCKET), а в качестве класса хранения — Hotbox. Для нашего приложения требуется хранение горячих данных. Использовать Icebox рекомендуется при редких обращениях к данным, например, несколько раз в месяц:
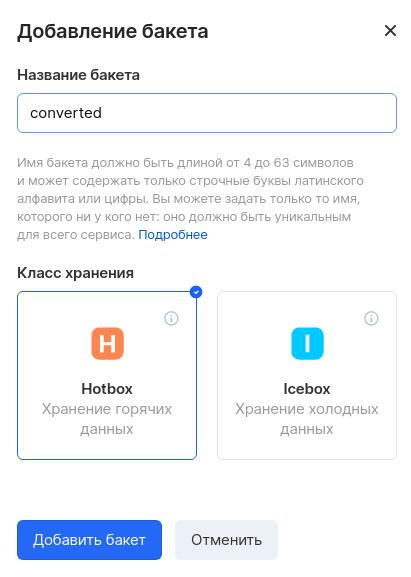
Стоит отметить, что MCS из коробки предлагает подключение CDN к вашим бакетам, а также привязку собственного домена. В нашем приложении мы это использовать не будем, но функции очень полезные.
Далее в пункте меню «Объектное хранилище» — «Аккаунты» создаем новый аккаунт worker для подключения к бакету:
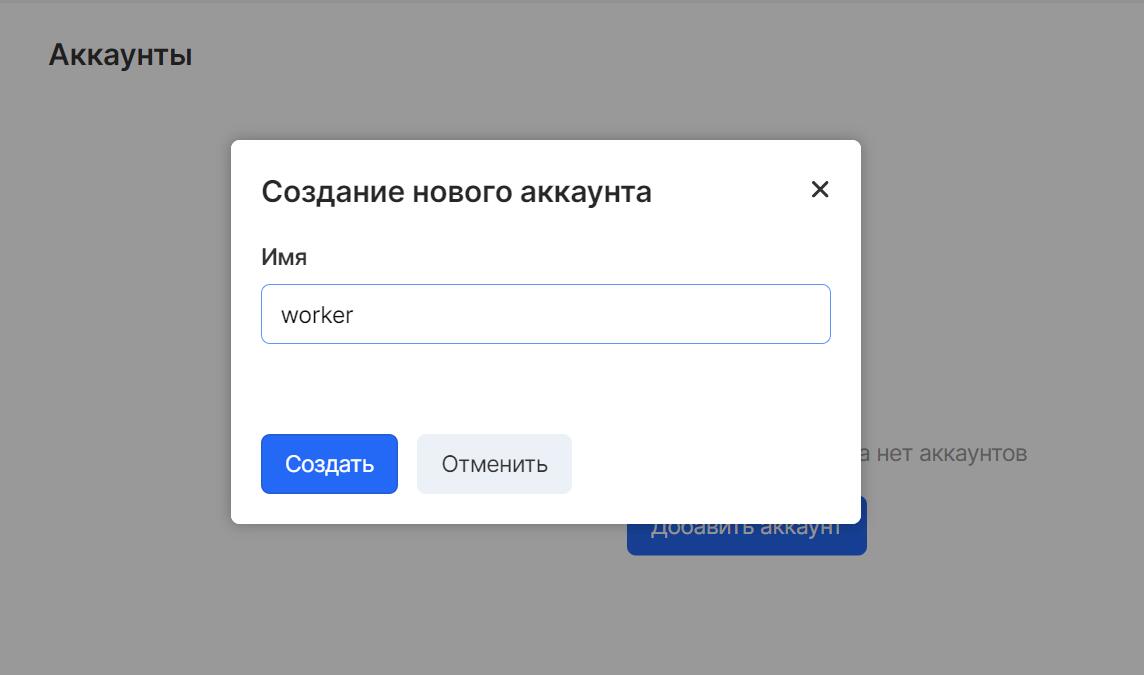
Затем копируем его токены Access Key Id и Secret Key в переменные S3_ACCESS_KEY и S3_SECRET_KEY, соответственно:

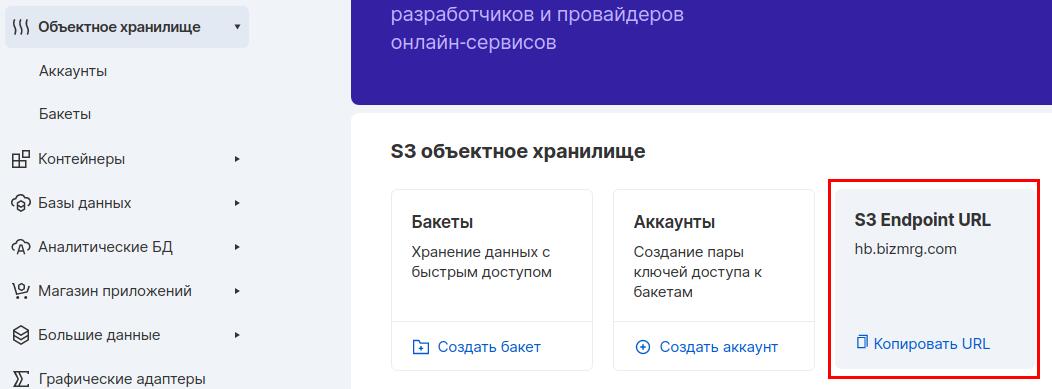
В пункте меню «Объектное хранилище» можно посмотреть S3 Endpoint URL. Именно это значение мы прописываем в переменной S3_ENDPOINT. Для доступа к конкретному бакету в начале этого URL дописывается название бакета: http://converted.hb.bizmrg.com. Это значение мы прописываем в переменной S3_WEB:
Развертывание и проверка обработчиков Worker в кластере Kubernetes
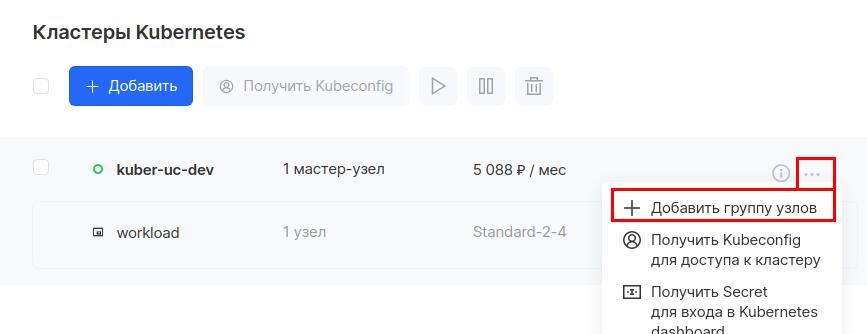
Так как конвертеру понадобится дополнительное количество CPU, мы не будем запускать его ни на Master-ноде, ни на рабочей ноде, на которой размещаются наши API и RabbitMQ. Поэтому в облаке MCS добавим новую группу узлов в наш кластер.
Для этого возвращаемся в раздел «Кластеры», напротив нашего кластера нажимаем на три точки и выбираем «Добавить группу узлов»:
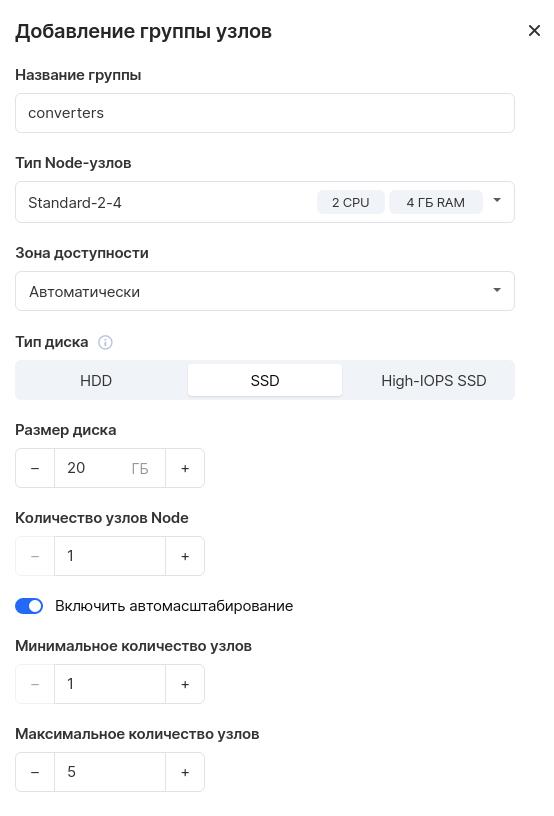
Назовем ее converters, пусть у нее будет 2 CPU и 4 ГБ памяти, SSD на 50 ГБ и один узел по умолчанию.
Важный момент: установим флажок «Включить автомасштабирование» и укажем минимальное количество узлов равным 1, а максимальное количество — равным 5. Это необходимо для работы автомасштабирования, которое мы позднее рассмотрим:
Проверяем, что у нас появилась нода с помощью команды kubectl get nodes:

При помощи команды get node можно вывести все параметры ноды в формате YAML:
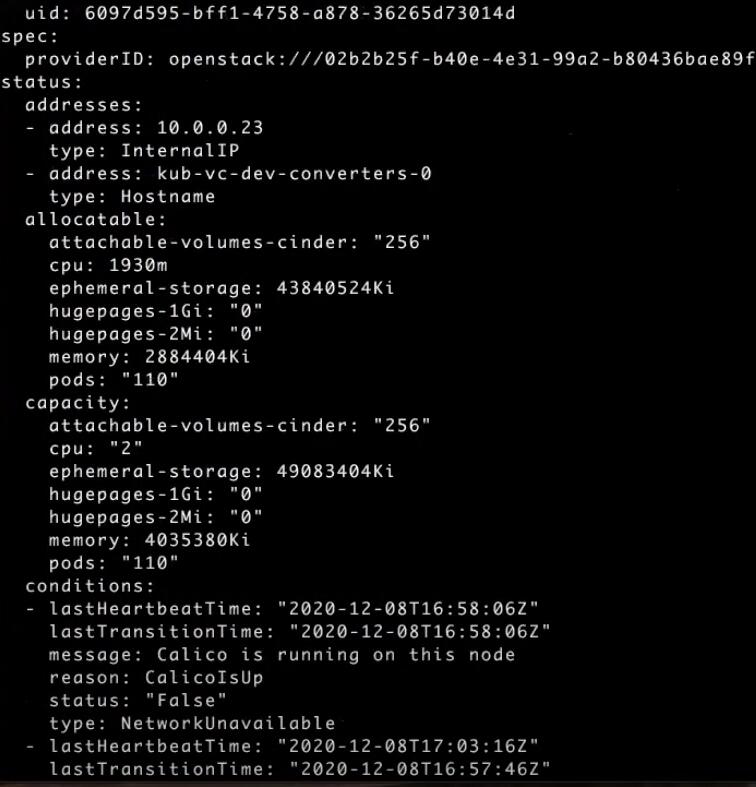
kubectl get node kub-vc-dev-converters-0 -o yamlОбратите внимание на секцию allocatable: здесь отображается, какие ресурсы и в каком объеме могут быть размещены на ноде. Например, в поле cpu видим, что на ноде можно разместить 1930 milicores, или миллиядер (в одном ядре 1000 миллиядер):
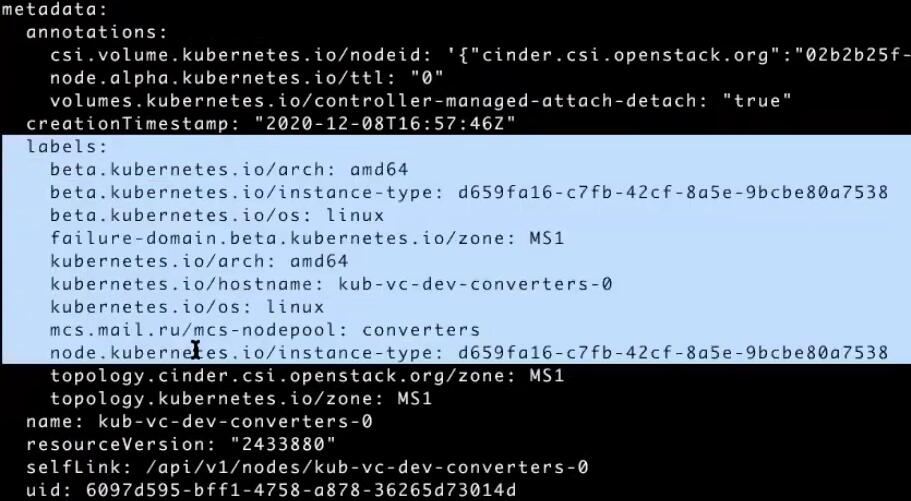
В секции labels отображаются все метки ноды. Нас интересует метка msc.mail.ru/mcs-nodepool: converters. Мы пропишем ее в deployment нашего конвертера для явного указания того, на каком node-пуле может запускаться приложение:
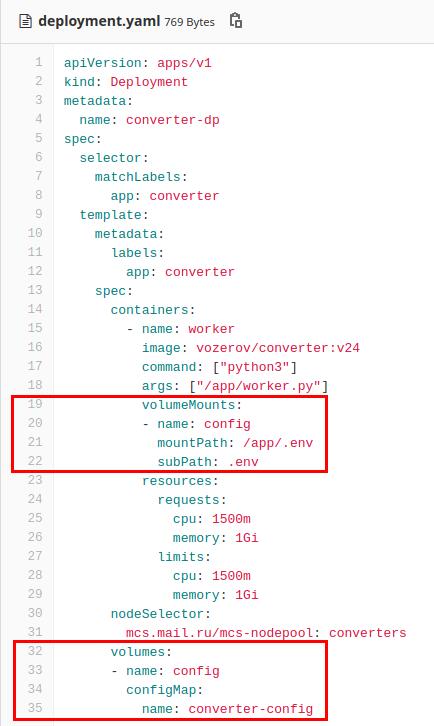
Для начала создадим deployment для нашего конвертера, назовем его converter-dp. В нем будет создаваться контейнер с названием worker с образом vozerov/converter:v24 (этот образ я также залил на hub.docker.com). Внутри будет запускаться python3 /app/worker.py. Далее в ресурсах указываем, что контейнер запрашивает 1,5 ядра CPU (1500 миллиядер) и 1 ГБ памяти, в лимитах укажем те же значения. И заполняем nodeSelector, сообщая Deployment, что поды можно запускать только на нодах, у которых есть label mcs.mail.ru/mcs-nodepool: converters:
apiVersion: apps/v1
kind: Deployment
metadata:
name: converter-dp
spec:
selector:
matchLabels:
app: converter
template:
metadata:
labels:
app: converter
spec:
containers:
- name: worker
image: vozerov/converter:v24
command: ["python3"]
args: ["/app/worker.py"]
volumeMounts:
- name: config
mountPath: /app/.env
subPath: .env
resources:
requests:
cpu: 1500m
memory: 1Gi
limits:
cpu: 1500m
memory: 1Gi
nodeSelector:
mcs.mail.ru/mcs-nodepool: converters
volumes:
- name: config
configMap:
name: converter-configТеперь по поводу конфигураций. Обычно в кластере множество нод, и вы не будете знать, на какой конкретно ноде запустится ваш под. Помещать в Docker-контейнер конфигурации всех сред было бы некорректно — они должны подключаться внутрь. Поэтому в Kubernetes есть важный ресурс — configMap. Вы создаете configMap и контейнер и говорите Kubernetes, что при запуске пода необходимо подгрузить определенную конфигурацию из configMap, после чего ваш контейнер сможет ее использовать.
Создадим новый configMap на основе файла .env. Назовем его converter-config:
kubectl -n stage create configmap converter-config --from-file=.envОткроем его в формате YAML:
kubectl -n stage get configmap/converter-config -o yamlИнформация в нем хранится в виде пар <ключ>|<значение>. В нашем случае ключ один — .env. Но их может быть несколько:

Возвращаемся к Deployment. У нас есть volume с именем config, который смотрит на созданный нами configMap с именем converter-config. И из этого configMap мы берем значение ключа .env, создаем файл и монтируем его в /app/.env:
Теперь можно создать конвертер, применив созданный deployment:
kubectl -n stage apply -f yaml/deployment.yamlПроверим, что появился новый под с помощью kubectl -n stage get pods:

Выводим логи пода kubectl -n stage logs -f converter-dp-68cdfdf9c8-ctbqc и видим, что конвертер находится в ожидании сообщений из RabbitMQ:

Давайте теперь отправим новый запрос в наше API. В качестве имени name укажем roger, а в video_url добавим адрес любого видео с YouTube на английском языке:
curl -X POST -d '{"name": "roger", "“video_url":
“https://www.youtube.com/watch?v=A72M2mZ2wHA"}' -s -H 'X-API-KEY: 804b95f13b714ee9912b19861faf3d25' http://api.stage.kis.im/requests | jq .Запрос принят:

Если теперь открыть логи пода cubectl -n stage logs -f converter-dp-68cdfdf9c8-ctbqc, то можно увидеть все этапы обработки нашего запроса в конвертере:
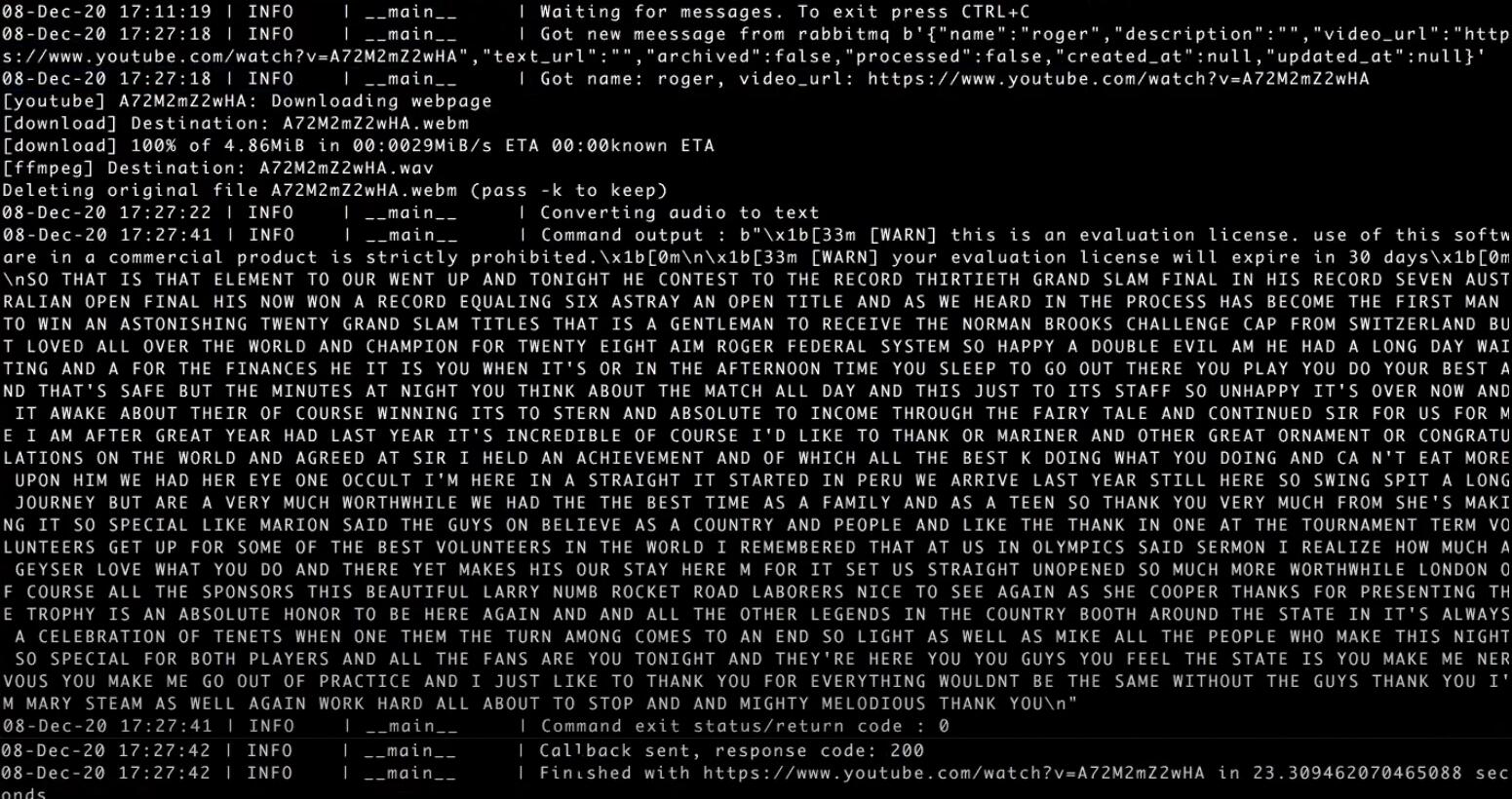
В конце выводится общее время выполнения — 23 секунды.
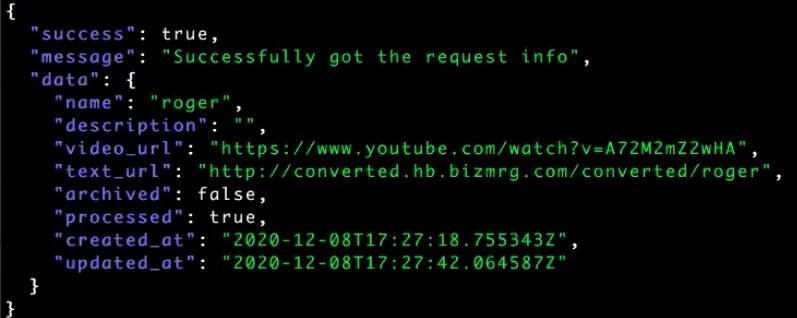
Давайте обратимся к нашему API и получим конкретный request по имени roger:
curl -X GET -s -H 'X-API-KEY: 804b95f13b714ee9912b19861faf3d25'
http://api.stage.kis.im/requests/roger | jq .Здесь в поле text_url выводится URL для загрузки сформированного для нас файла в S3. Программный код необходимо доработать, чтобы URL возвращался вместе с расширением .txt: сейчас сохраняется без расширения:
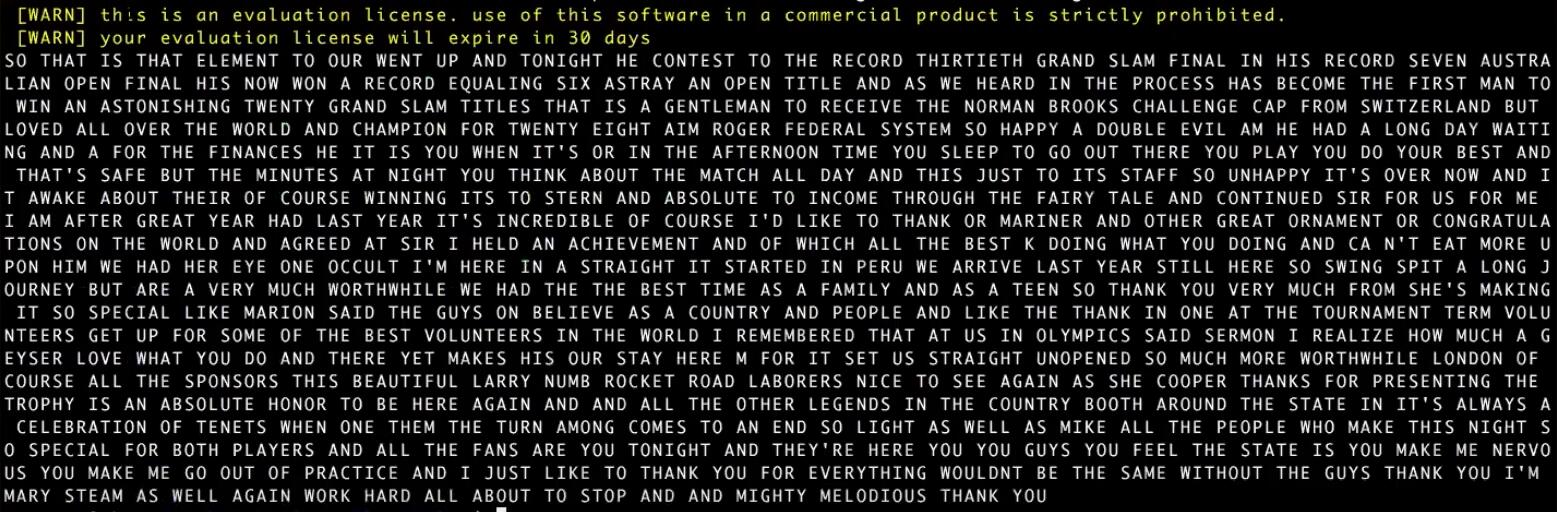
Можем вывести содержимое файла через CURL:
curl http://converted.hb.bizmrg.com/converted/roger.txtПолучим текстовую расшифровку переданного нами видео:
Если теперь зайти в облако MCS в созданный нами бакет converted, то в директории /converted будет размещаться итоговый файл:

Таким образом, проверка нашего MVP-решения успешно выполнена.
Автомасштабирование в Kubernetes
Далее было бы неплохо, чтобы наш сервис мог автоматически масштабироваться. Так как перевод аудио в текст занимает некоторое время, при поступлении большого количества ссылок на конвертацию один Worker может обрабатывать их очень долго. В таких случаях необходимо автоматически добавлять новые Worker, чтобы они быстро все обрабатывали, а при отсутствии задач отключались.
В этом нам помогут Cluster Autoscaler и Horizontal Pod Autoscaler, доступные в Kubernetes. Первый отвечает за создание новых нод, второй — за увеличение числа подов. Кроме них есть еще Vertical Pod Autoscaler, изменяющий ресурсы для пода, но мы его рассматривать не будем.
Вернемся к deployment нашего конвертера. При создании нового пода необходимо определить, сколько ресурсов ему потребуется. Для этого предназначена секция resources, состоящая из двух разделов: requests и limits:
resources:
requests:
cpu: 1500m
memory: 1Gi
limits:
cpu: 1500m
memory: 1GiБлок requests анализируется планировщиком Kubernetes. Когда создается новый под, планировщик его берет и назначает на какую-то ноду, опираясь на большое количество критериев и правил. Могут учитываются Labels (как мы делали с Node Selector), Affinity, Anti-Affinity, Taints, Tolerations и так далее.
Нас сейчас интересуют именно ресурсы. Как мы видели ранее, у каждой ноды есть доступное количество ресурсов (allocatable). В нашем случае, например, 1930 миллиядер. Соответственно, один под, которому требуется 1,5 ядра, может быть размещен на данной ноде, а второму ресурсов уже не хватит. Поэтому планировщик разместит его на имеющуюся свободную ноду.
Второй блок в описании ресурсов limits — это уже жесткие лимиты, аналог Docker Limits. Мы ограничиваем наше приложение: использовать не более 1,5 ядер и 1 ГБ памяти.
От заполнения секции resources зависит очень важный момент. Если применить команду describe к нашему поду, можно получить его QoS (Quality of Service) Class. В нем возможны три значения: Best Effort, Burstable и Guaranteed. Guaranteed назначается тем подам, у которых все контейнеры имеют одинаковые limits и requests. Если requests либо limits заполнены частично либо не совпадают друг с другом (limits выше), мы получаем класс Burstable. Если же resources не заполнены или вовсе убраны, то это класс Best Effort. Соответственно, если Kubernetes обнаружит проблему с нодой, он в первую очередь будет убивать класс Best Effort, затем Burstable и только потом Guaranteed. Поэтому всегда заполняйте секцию resources:

Если применить kubectl describe node kub-vc-dev-converters-0 к ноде, то можно увидеть все требования к ресурсам для сервисов, запущенных на ноде:
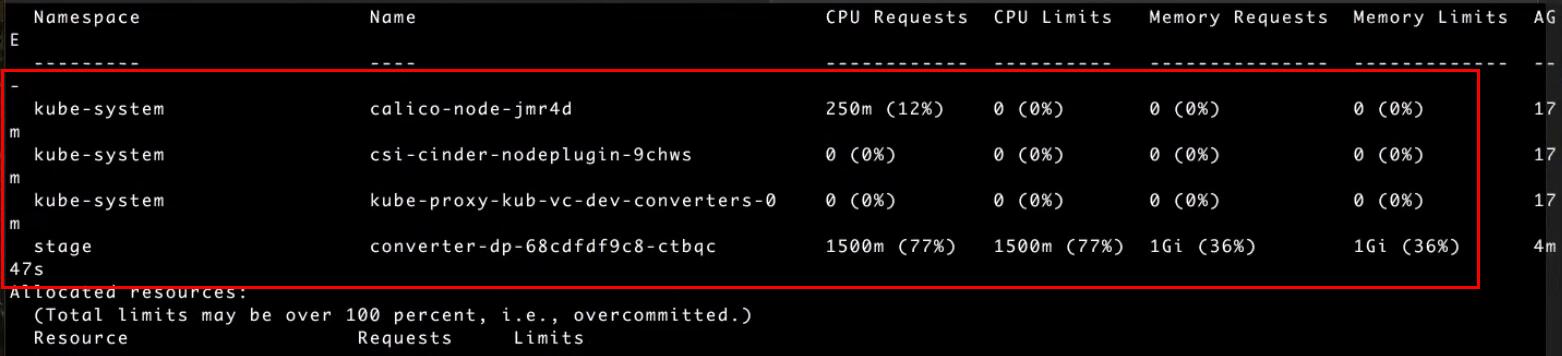
Теперь переходим непосредственно к автоскейлингу. Давайте увеличим вручную число подов под наш конвертер до двух, и выведем список подов:
kubectl -n stage scale deploy converter-dp --replicas=2
kubectl -n stage get podsНовый под пока отображается в статусе Pending:

Применим к нему kubectl -n stage describe pod converter-dp-68cdfdf9c8-6tfvr и посмотрим секцию Events:

Из трех нод доступно ноль. Одна нода не попадает по Node Selector, который мы указали, а у двух нод недостаточно CPU. И после этого в дело включается Cluster Autoscaler. Он видит, что новый под запуститься не может: на ноде доступно 1930 миллиядер, а для двух подов требуется 3000. Поэтому группа узлов, для которой мы предварительно указали опцию «Включить автомасштабирование», начинает самостоятельно расширяться до двух нод. Если зайти в консоль управления облаком MCS, то можно увидеть статус кластера «Производится масштабирование кластера»:
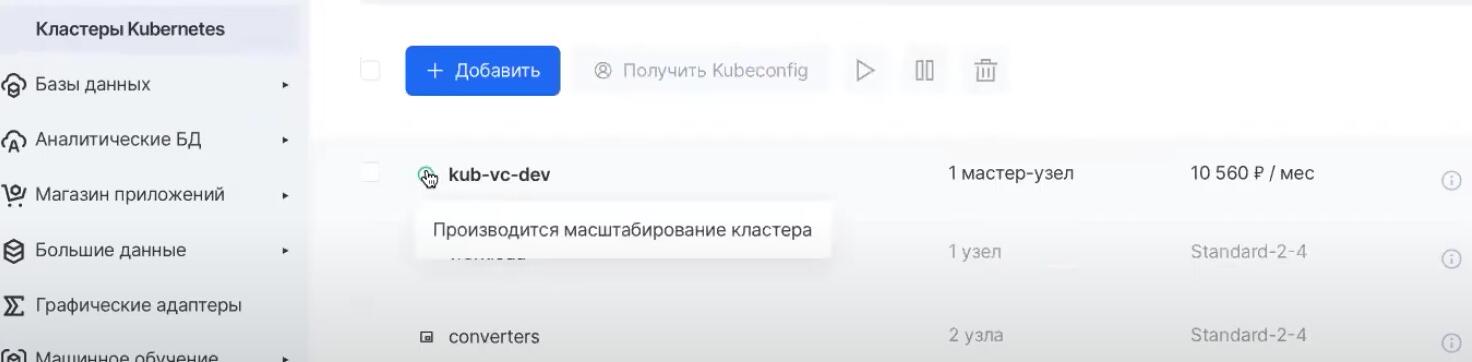
В этом преимущество автоскейлинга в облаках: от нас ничего не требуется. Будет автоматически создана новая нода с тем же Node Selector, и новый под запустится на ней. Подождем некоторое время и проверим поды:
kubectl -n stage get podsОба контейнера запустились:

Теперь проверим ноды:
kubectl get nodesПоявилась новая нода:

Давайте теперь уменьшим число реплик обратно до одной:
kubectl -n stage scale deploy converter-dp --replicas=1Проверим, что запустилось уничтожение нового пода с помощью kubectl -n stage get pods:

Через некоторое время Cluster Autoscaler увидит, что новая нода никак не используется, и уничтожит и ее — и у нас опять останется ровно одна нода в группе узлов.
Таким образом, мы рассмотрели, как при ручном увеличении числа подов Cluster Autoscaler добавляет новую ноду в группу узлов. Осталось научиться выполнять автомасштабирование подов при увеличении нагрузки на них. Для этого в Kubernetes существует ресурс HPA (Horizontal Pod Autoscaler).
Создадим hpa.yaml под нашу задачу. Заполняем имя — converter_hpa. В scaleTragetRef указываем deployment, к которому будет применяться масштабирование — converter-dp. В minReplicas и maxReplicas вводим минимальное и максимальное число подов — 1 и 5. В секции resource выбираем в качестве отслеживаемой метрики CPU и указываем его допустимое значение, при превышении которого запускать увеличение подов — 50%. Мы намеренно указываем низкое значение, чтобы продемонстрировать работу HPA:
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: converter-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: converter-dp
minReplicas: 1
maxReplicas: 5
metrics:
- type: Resource
resource:
name: cpu
targetAverageUtilization: 50Применяем hpa.yaml к Namespace stage:
kubectl -n stage apply -f hpa.yamlЕсли выполнить команду kubectl -n stage top pods, можно увидеть, сколько ресурсов потребляют поды:

При вызове get hpa видим превышение потребления CPU на 15%:

Применим kubectl -n stage describe hpa converter-hpa к нашему converter-hpa и посмотрим, что происходит. В секции Events можно увидеть увеличение числа подов до двух: «New size: 2». Horizontal Pod Autoscaler увеличил число подов:
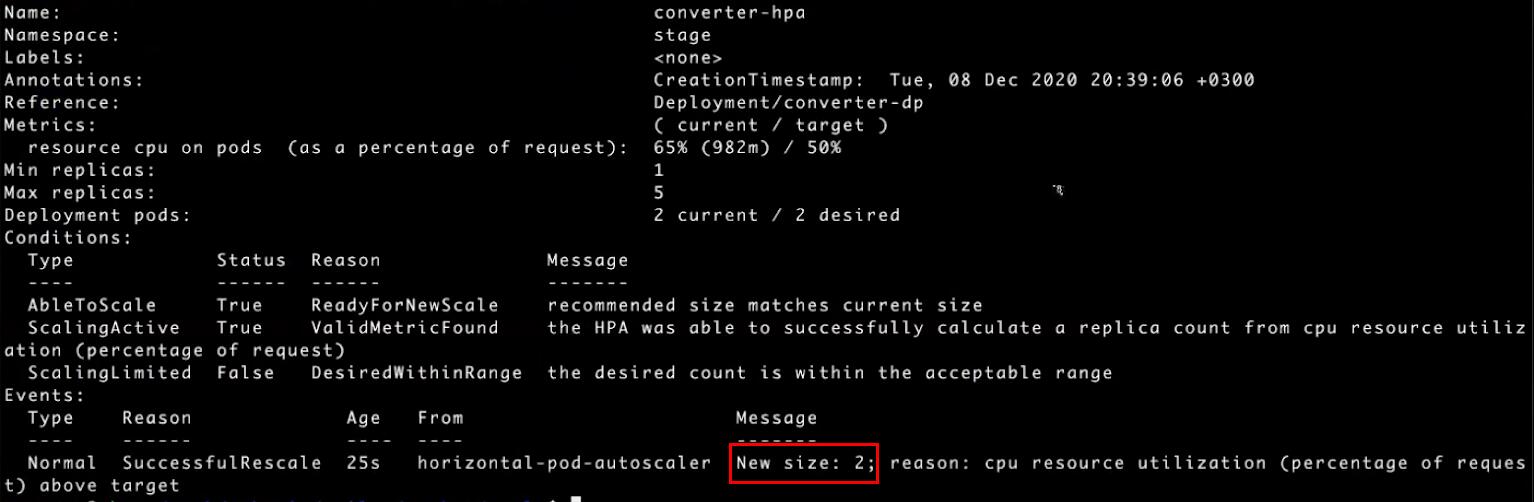
В общем списке под также появился, в статусе Pending, смотрим с помощью kubectl -n stage get pods:

А если к новому поду применить команду describe, то в секции Events увидим, как к скейлингу подключился Cluster Autoscaler. Horizontal Pod Autoscaler увеличил количество подов, но подам не хватает ресурсов — и Cloud Autoscaler добавляет ноды:

Однако схема с отслеживанием CPU не самая подходящая для нашего приложения. Предположим, у нас в очереди одно сообщение. Worker берет его в обработку и загружает весь CPU. В ответ на это HPA создает новый под, а Cluster Scaler — новую ноду. Но новых сообщений в очереди еще нет, и поду нечего обрабатывать — в итоге дополнительно оплачиваемая нода будет простаивать.
Очевидно, что в качестве метрики нас интересует не CPU, а количество сообщений в очереди. Нам нужно настроить HPA таким образом, чтобы количество сообщений в очереди было не больше одного. Если их больше — можно увеличивать количество подов.
В Kubernetes api-resources есть встроенные метрики. Они находятся в группе metrics.k8s.io. За них отвечает сервис kube-system/metrics-server. Metrics-server следит за подами, нодами и создает соответствующие ресурсы PodMetrics и NodeMetrics, которые используются в Horizontal Pod Autoscaler для принятия решения об изменении количества подов.
Применив команду kubectl -n stage get podmetrics, можно посмотреть на PodMetrics наших сервисов:
Вызвав ту же команду kubectl -n stage get pods podmetrics rabbitmq-0 -o yaml для конкретной метрики rabbitmq-0, увидим, что RabbitMQ, например, у нас использует 121 миллиядро и 119 МБ памяти:
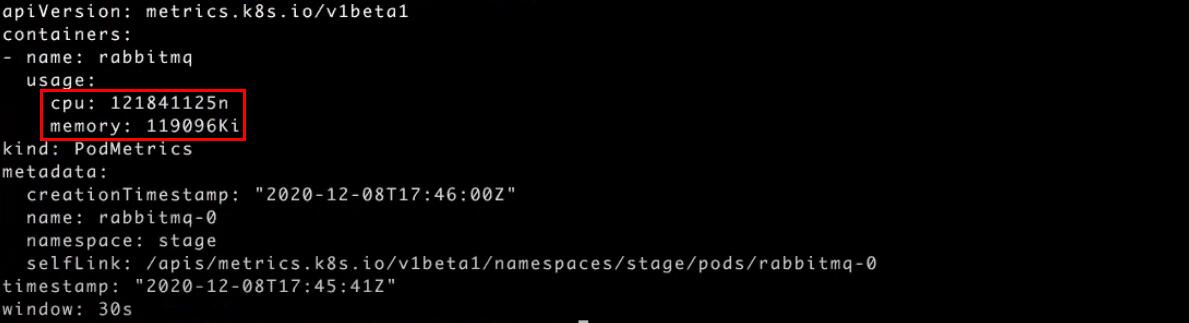
Наша следующая задача — добавление кастомных метрик для RabbitMQ с возможностью их использования в HPA.
В третьей части мы организуем мониторинг с помощью Prometheus, построим CI/CD и даже разработаем собственный Helm-чарт.
Новым пользователям платформы Mail.ru Cloud Solutions доступны 3000 бонусов после полной верификации аккаунта. Вы сможете повторить сценарий из статьи или попробовать другие облачные сервисы.
И обязательно вступайте в сообщество Rebrain в Telegram — там постоянно разбирают различные проблемы и задачи из сферы Devops, обсуждают вещи, которые пригодятся и на собеседованиях, и в работе.
Что еще почитать по теме:
