
Задачу обнаружения различных объектов сейчас модно решать на основе глубокого обучения. Но для этого нужно собрать и разметить датасет, сконструировать глубокую нейронную сеть, обучить ее и запустить “в продакшн”. И если раньше для всего этого приходилось самостоятельно писать код, то сейчас можно воспользоваться продвинутыми инструментами, призванными упростить процесс. Мы воспользуемся CVAT (Computer Vision Annotation Tool) для разметки датасета, OpenVINO Training Extensions для обучения модели и OpenVINO Object Detection Demo для ее запуска. При этом, мы не напишем ни одной строчки кода (команды консоли не в счет).
Поп-ит и симпл-димпл захватили умы молодежи, и я поддался тренду и тоже приобрел себе круглый цветастый поп-ит. Вдоволь наигравшись с антистресс-игрушкой по прямому назначению, я решил что она может послужить еще одной цели - развитию компетенций в компьютерном зрении.
Так родилась задача обнаружения самого поп-ита на изображениях и детектирования его выпуклых и вогнутых "пупырок". Также важным условием являлся выбор простых инструментов, чтобы не было необходимости разбираться в сложностях конструирования и обучения object detection моделей.
Разметка набора данных с помощью CVAT
Собрать и разметить набор данных для задачи object detection - не самая приятная задача для разработчиков. На помощь в этом деле приходит CVAT - инструмент для разметки изображений и видео. Он имеет много интересных возможностей:
Удобная работа с большими объемами данных - можно разбить разметку большого количества данных на подзадачи и выполнять их независимо, привлекая несколько исполнителей.
Автоматическая аннотация - можно прогнать ваши изображения через встроенные в CVAT модели глубокого обучения. С их помощью CVAT может сделать за вас часть работы по разметке, останется поправить классы (но с детектированием отдельных пупырок поп-ит такое не получится - в предобученных моделях нет такого класса или классов, на него похожих).
Для небольших проектов достаточно возможностей на сайте cvat.org. Если возникает необходимость использовать свои DL модели при автоматической разметке, или необходимость разметить очень большой датасет, то можно установить CVAT локально.
Для разметки я сделал 10 фотографий поп-ита в разных ракурсах и разных конфигурациях, упаковал их в zip архив.

Порядок действий при работе с платформой cvat.org:
Пройти регистрацию и выполнить вход на сайте cvat.org;
Создать новый проект, в поле настройки проекта создать три метки классов (popit, pressed, released);

Создаем новый проект, добавляем три класса объектов Открыть проект, в проекте создать новую задачу, в нижнее поле поместить архив с изображениями;
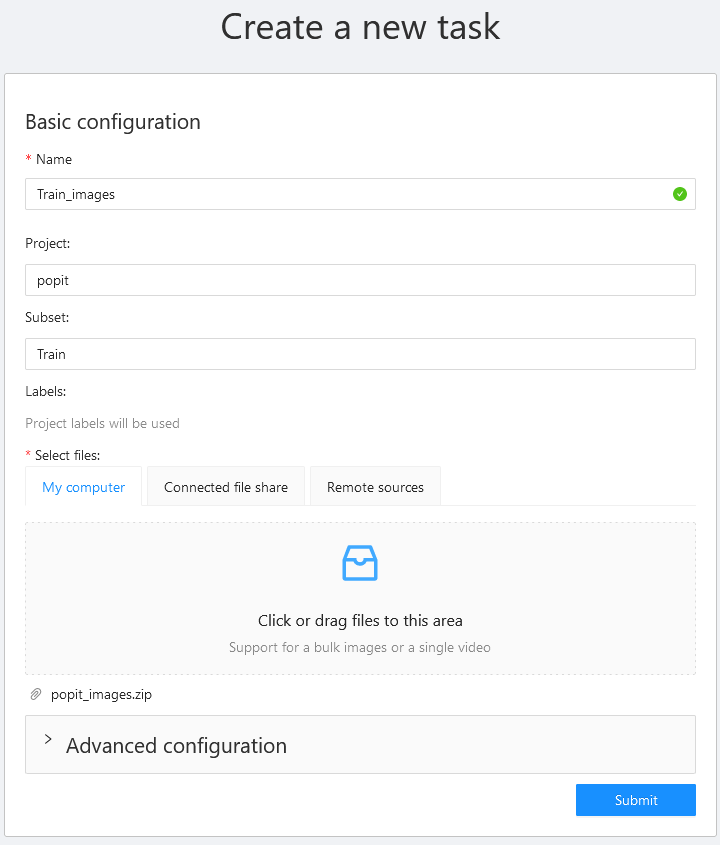
Открыть задачу и открыть одну гиперссылку в номере работы для доступа в интерфейс разметки;

Разметить изображения инструментом Rectangle;

Сохранить изменения и экспортировать разметку в формате MS COCO.






Команда разработки поддерживает документацию о работе с CVAT в актуальном состоянии.
Интерфейс CVAT для разметки очень лаконичен, и визуально напоминает Photoshop. Слева инструменты для разметки, сверху по центру элементы навигации, справа размеченные объекты. На 10 тренировочных изображениях я разметил 290 прямоугольников, с CVAT на это ушло чуть больше получаса. И тут меня настигли сомнения в успешности моей задумки — в некоторых ракурсах я сам не мог понять, выгнуты пупырки наружу или прожаты вниз. Собственно, именно в этот момент в датасеты закрадываются ошибки, их можно встретить в большинстве крупных датасетов, как например в ImageNet. Но желание экспериментов не позволило остановиться в начале пути.

На странице CVAT на GitHub есть раздел Screencasts, в нем представлены видео, которые показывают возможности инструмента при разметке изображений и видео.
Обучение модели с помощью Training Extensions
Для обучения модели мы воспользуемся Training Extensions - фреймворком для обучения глубоких моделей, с помощью которого обучаются некоторые модели из репозитория Open Model Zoo. Нас интересует Custom Object Detection; для этой задачи в Training Extensions используется модель mobilenet-v2-ssd, предобученная на датасете MS COCO.
Для некоторых моделей нежелательно, чтобы в данных для обучения рамки объектов пересекались. Это снова намекало на неудачный конец моих экспериментов, поскольку больше половины фотографий сделаны в таком ракурсе, что ограничивающие боксы пересекаются. Что ж, все равно продолжим и посмотрим что получится!
Первая стадия - сборка пакета Intel OpenVINO Training Extensions по инструкции из README.md, здесь менять ничего не требуется. Поскольку в Windows есть проблемы с выделением всей памяти фреймворку машинного обучения, придется воспользоваться Ubuntu 18.04 или 20.04. Также ограничение на момент июля 2021 - при обучении на GPU требуется CUDA 10.2 (это соответствует драйверу nvidia-440), c версией младше или старше пакет не соберется.
cd ~/
git clone https://github.com/openvinotoolkit/training_extensions.git
export OTE_DIR=`pwd`/training_extensions
git clone https://github.com/openvinotoolkit/open_model_zoo --branch develop
export OMZ_DIR=`pwd`/open_model_zoo
cd ~/training_extensions
sudo apt-get install python3-pip
python3 -m venv venv
source venv/bin/activate
pip3 install -e ote/После сборки пакета ote нужно подготовиться к обучению модели детектирования. Для этого модифицируем инструкцию из файла README.md по тренировке модели детектирования объектов под себя.
cd ~/training_extensions/models/object_detection
./init_venv.sh
source venv/bin/activateВ инструкции обучается модель с самым маленьким размером входного изображения, я беру версию с входным изображением 512*512, потому что в самой маленькой пупырки будут совсем маленькие по размерам.
export MODEL_TEMPLATE=`realpath ./model_templates/custom-object-detection/mobilenet_v2-2s_ssd-512x512/template.yaml`
export WORK_DIR=/tmp/my_model
python ../../tools/instantiate_template.py ${MODEL_TEMPLATE} ${WORK_DIR}Задаем пути к файлам созданного нами датасета в домашней директории и список классов для обучения (не забудьте проверить соответствие путей файлам датасета):
export OBJ_DET_DIR=`pwd`
export TRAIN_ANN_FILE="/home/eugene/popit-dataset/train.json"
export TRAIN_IMG_ROOT="/home/eugene/popit-dataset/train"
export VAL_ANN_FILE="/home/eugene/popit-dataset/val.json"
export VAL_IMG_ROOT="/home/eugene/popit-dataset/val"
export CLASSES="popit,pressed,released"Для обучения модели нам нужно определить некоторые параметры - размер пачки, количество эпох, количество GPU (если их несколько). Если при старте обучения у вас программа упала с ошибкой о нехватке памяти, уменьшите размер пачки (16 -> 8 -> 4 -> 2 -> 1). Лучше, конечно, чтобы было хотя бы 8 гигабайт видеопамяти; я сам использовал GTX 1070 Ti, она справляется с размером пачки 16 и для средней модели, и для большой. Итераций можно поставить побольше, на своем датасете из 10 картинок я установил 50 итераций, чтобы обучение укладывалось в полчаса. Фреймворк генерирует код для старта обучения модели в папке ${WORK_DIR}, где мы потом сможем забрать результаты.
cd ${WORK_DIR}
python train.py --load-weights ${WORK_DIR}/snapshot.pth \
--train-ann-files ${TRAIN_ANN_FILE} \
--train-data-roots ${TRAIN_IMG_ROOT} \
--val-ann-files ${VAL_ANN_FILE} \
--val-data-roots ${VAL_IMG_ROOT} \
--save-checkpoints-to ${WORK_DIR}/outputs \
--classes ${CLASSES} \
--gpu-num 1 \
--epochs 50 \
--batch-size 16После обучения можно протестировать результаты на валидационной части датасета, и сохранить изображения с помощью параметра --save-output-to, например, на рабочий стол.
python eval.py --load-weights ${WORK_DIR}/outputs/latest.pth \
--test-ann-files ${VAL_ANN_FILE} --test-data-roots ${VAL_IMG_ROOT} \
--save-metrics-to ${WORK_DIR}/metrics.yaml \
--classes ${CLASSES} \
--save-output-to ${WORK_DIR}/output_imagesПосле обучения и валидации модели сконвертируем модель в формат OpenVINO. Модель состоит из двух файлов - .xml с архитектурой и параметрами сети и .bin с весами. Перед экспортом нужно активировать OpenVINO с помощью скрипта setupvars.sh:
source ~/intel/openvino_2021/bin/setupvars.sh
pip install -r ~/intel/openvino_2021/deployment_tools/model_optimizer/requirements_onnx.txt
python export.py --load-weights ${WORK_DIR}/outputs/latest.pth --save-model-to ${WORK_DIR}/exportВ папке ${WORK_DIR}/export будут храниться модели, в формате onnx и OpenVINO.
Запуск инференса с помощью OpenVINO
Запускать инференс модели будем с помощью OpenVINO Object Detection Demo из репозитория Open Model Zoo. В нем можно использовать для детектирования как одно изображение, так и папку с изображениями, а также можно подать на вход видео из файла или с веб-камеры. Чтобы использовать в демо камеру, запускайте с ключом -i 0 (номер камеры).
python "C:\Program Files (x86)\Intel\openvino_2021\deployment_tools\open_model_zoo\demos\object_detection_demo\python\object_detection_demo.py" \
-m export_512\model.xml -at ssd -i 0 -t 0.2
По результатам тестирования обученной модели видно, что у меня получилось научить модель детектировать сам поп-ит и отдельные пупырки, однако обучить разделять “лопнутые” и “нелопнутые” не удалось. Можно добавить классификационную модель, которая будет их классифицировать, но тогда все же придется программировать конвейер из двух моделей на C++ или Python.
В моем случае не удалось решить задачу на 100%, однако сам поп-ит и пупырки на нем успешно детектируются. Какие можно сделать выводы на будущее:
Можно решать задачи по обучению глубоких моделей не написав ни строчки кода (если не считать консоль);
Делать разметку современными инструментами очень удобно;
Датасет должен быть большой и разнообразный;
Есть в лопании пупырок что-то успокаивающее.
Вместо заключения
Мне очень нравится, что инструменты Intel идут в тренде снижения сложности входа в разработку приложений. Такие вещи помогут создавать приложения с применением глубокого обучения более широкому кругу школьников и студентов. Кстати, любую стадию экспериментов можно повторить самостоятельно - и изображения, и разметка, и модели доступны в репозитории.
