
Привет, читатели хабра! Темой этой статьи будет реализация средств катастрофоустойчивости в системах хранения AERODISK Engine. Изначально мы хотели написать в одной статье про оба средства: репликацию и метрокластер, но, к сожалению, статья получилась слишком большой, поэтому мы разбили статью на две части. Пойдем от простого к сложному. В этой статье мы настроим и протестируем синхронную репликацию – уроним один ЦОД, а также оборвем канал связи между ЦОД-ами и посмотрим, что из этого получится.
Наши заказчики нам часто задают разные вопросы о репликации, поэтому, прежде чем переходить к настройке и тестированию реализации реплик, мы немного расскажем, что такое репликация в СХД.
Немного теории
Репликация в СХД – это постоянный процесс обеспечения идентичности данных одновременно на нескольких СХД. Технически репликация выполняется двумя методами.
Синхронная репликация – это копирование данных с основной СХД на резервную с последующим обязательным подтверждением обеих СХД, что данные записаны и подтверждены. Именно после подтверждения с двух сторон (с обеих СХД) данные считаются записанными, и с ними можно работать. Тем самым обеспечивается гарантированная идентичность данных на всех СХД, участвующих в реплике.
Плюсы такого метода:
- Данные всегда идентичны на всех СХД
Минусы:
- Высокая стоимость решения (быстрые каналы связи, дорогое оптоволокно, длинноволновые трансиверы и т.п.)
- Ограничения по расстоянию (в пределах нескольких десятков километров)
- Нет защиты от логической порчи данных (если данные испортят (сознательно или случайно) на основной СХД, то они автоматом и моментально станут испорчены на резервной, так как данные всегда идентичны (вот такой парадокс)
Асинхронная репликация – это тоже копирование данных с основной СХД на резервную, но с определённой задержкой и без необходимости подтверждения записи на другой стороне. Работать с данными можно сразу после записи на основную СХД, а на резервной СХД данные будут доступны через некоторое время. Идентичность данных в этом случае, понятно, не обеспечивается совсем. Данные на резервной СХД всегда находятся немного «в прошлом».
Плюсы асинхронной репликации:
- Невысокая стоимость решения (любые каналы связи, оптика опциональна)
- Нет ограничений по расстоянию
- На резервной СХД данные не портятся в случае их порчи на основной (как минимум, некоторое время), если данные стали испорчены, всегда можно остановить реплику, чтобы не допустить порчу данных на резервной СХД
Минусы:
- Данные в разных ЦОДах всегда неидентичны
Таким образом, выбор режима репликации зависит от задач бизнеса. Если вам критично, чтобы в резервном ЦОДе были абсолютно те же данные что и в основном (т.е. требование бизнеса по RPO=0), то придется раскошелиться и мириться с ограничениями синхронной реплики. А если задержка состояния данных допустима или просто нет денег, то, однозначно, надо использовать асинхронный метод.
Еще отдельно выделим такой режим (точнее, уже топологию) как метрокластер. В режиме метрокластера используется синхронная репликация, но, в отличие от обычной реплики, метрокластер позволяет обеим СХД работать в активном режиме. Т.е. у вас нет разделения на активный-резервный ЦОДы. Приложения работают одновременно с двумя СХД, которые физически расположены в разных ЦОД-ах. Даунтаймы при авариях в такой топологии очень невелики (RTO, как правило минуты). В этой статье мы не будем рассматривать нашу реализацию метрокластера, поскольку эта очень большая и емкая тема, поэтому ей мы посвятим отдельную, следующую статью, в продолжение этой.
Также очень часто, когда мы говорим о репликации средствами СХД, у многих возникает резонный вопрос: > «У многих приложений есть свои средства репликации, зачем же использовать репликацию на СХД? Это лучше или хуже?»
Тут нет однозначного ответа, поэтому приведем аргументы ЗА и ПРОТИВ:
Аргументы ЗА репликацию СХД:
- Простота решения. Одним средством вы можете реплицировать весь массив данных, независимо от типа нагрузки и приложений. Если использовать реплику от приложений, то настраивать придется каждое приложение в отдельности. Если их больше 2-х, то это крайне трудоёмко и дорого (репликация приложений требует, как правило, отдельную и не бесплатную лицензию на каждое приложение. Но об этом ниже).
- Можно реплицировать что угодно – любые приложения, любые данные – и они всегда будут консистентные. Многие (большинство) приложения не имеют средств репликации, и реплики со стороны СХД – единственное средство обеспечить защиту от катастроф.
- Не нужно переплачивать за функционал репликации приложений. Как правило, он стоит недешево, так же, как и лицензии на реплику СХД. Но за лицензию на репликацию СХД надо заплатить единожды, а лицензию на реплику приложений нужно покупать для каждого приложения отдельно. Если таких приложений много, то это влетает в копеечку и стоимость лицензий на репликацию СХД становится каплей в море.
Аргументы ПРОТИВ репликации СХД:
- Реплика средствами приложений имеет больше функциональности с точки зрения самих приложений, приложение лучше знает свои данные (что очевидно), поэтому вариантов работы с ними больше.
- Производители некоторых приложений не гарантируют консистентность своих данных, если делать репликацию сторонними средствами. *
*- спорный тезис. Например, известная компания-производитель СУБД, очень долго официально заявляла, что их СУБД может нормально реплицироваться только их средствами, а остальная репликация (в т. ч. и СХД-шная) это «не true». Но жизнь показала, что это не так. Скорее всего, (но это не точно) это просто не самая честная попытка допродать еще лицензий заказчикам.
В итоге в большинстве случаев репликация со стороны СХД лучше, т.к. это более простой и менее дорогой вариант, но есть сложные случаи, когда необходим специфический функционал приложений, и надо работать именно с репликацией уровня приложений.
С теорией закончили, теперь практика
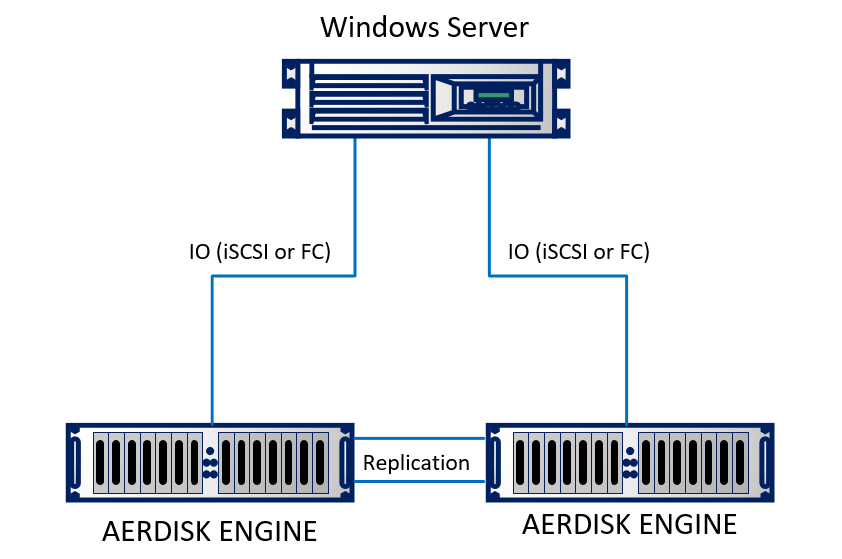
Настраивать реплику мы будем в нашей лабе. В лабораторных условиях мы эмулировали два ЦОДа (на самом деле, две рядом стоящие стойки, которые как будто стоят в разных зданиях). Стенд состоит из двух СХД Engine N2, которые соединены между собой оптическими кабелями. К обеим СХД подключен физический сервер с ОС Windows Server 2016 используя 10Gb Ethernet. Стенд довольно простой, но сути это не меняет.
Схематично он выглядит так:
Логически репликация организована следующим образом:
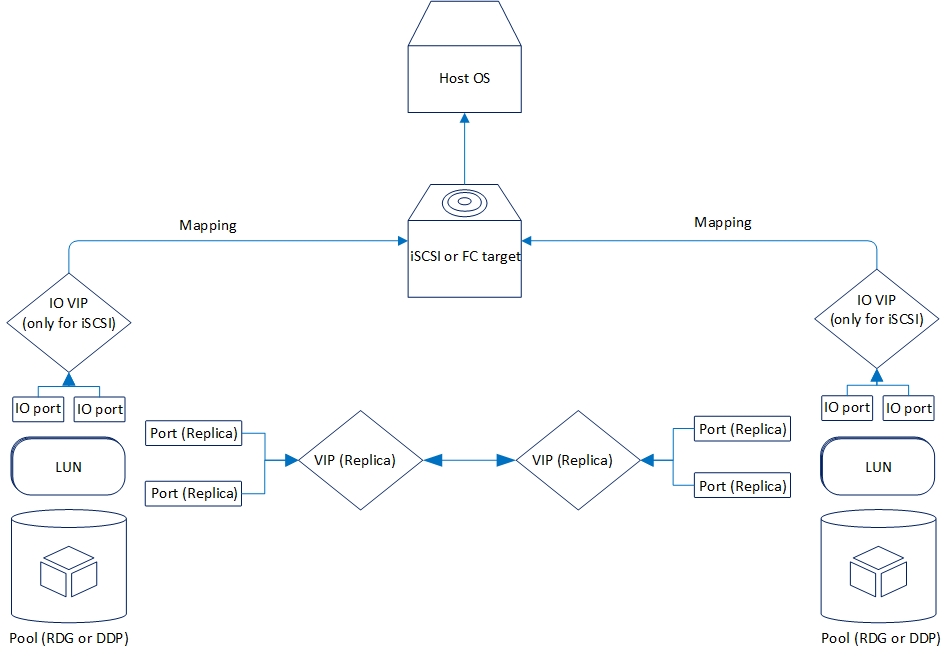
Теперь разберем функциональные возможности репликации, которые у нас есть сейчас.
Поддерживается два режима: асинхронный и синхронный. Логично, что синхронный режим ограничен расстоянием и каналом связи. В частности, для синхронного режима требуется использовать оптоволокно в качестве физики и 10 гигабитный Ethernet (или выше).
Поддерживаемое расстояние для синхронной репликации – 40 километров, значение задержек канала оптики между ЦОДами до 2 миллисекунд. Вообще работать будет и с большими задержками, но тогда будут сильные тормоза при записи (что тоже логично), поэтому если вы задумали синхронную репликацию между ЦОД-ами, следует проверить качество оптики и задержки.
К асинхронной репликации требования не такие серьезные. Точнее, их нет совсем. Подойдет любое работающее соединение по Ethernet.
На текущий момент в СХД AERODISK ENGINE поддерживается репликация для блочных устройств (LUNов) по протоколу Ethernet (по меди или по оптике). Для проектов, где обязательно требуется репликация через SAN-фабрику по Fibre Channel, мы сейчас дописываем соответствующее решение, но пока оно не готово, поэтому в нашем случае – только Ethernet.
Репликация может работать между любыми СХД серии ENGINE (N1, N2, N4) с младших систем на старшие и наоборот.
Функционал обоих режимов репликации полностью идентичен. Ниже подробнее о том, что есть:
- Репликация «one to one» или «один к одному», то есть классический вариант с двумя ЦОД-ами, основным и резервным
- Репликация «one to many» или «один к многим», т.е. один LUN можно реплицировать на несколько СХД сразу
- Активация, деактивация и «разворот» репликации, соответственно, для включения, выключения или изменения направления репликации
- Репликация доступна как для пулов RDG (Raid Distributed Group), так и для DDP (Dynamic Disk Pool). При этом LUN пула RDG можно реплицировать только в другой RDG. C DDP аналогично.
Есть ещё множество мелких особенностей, но перечислять их нет особого смысла, их мы будем упоминать по ходу настройки.
Настройка репликации
Процесс настройки достаточно прост и состоит из трех этапов.
- Настройка сети
- Настройка хранилища
- Настройка правил (связей) и маппинга
Важным моментом настройки репликации является то, что первые два этапа следует повторять на удаленной СХД, третий этап – только на основной.
Настройка сетевых ресурсов
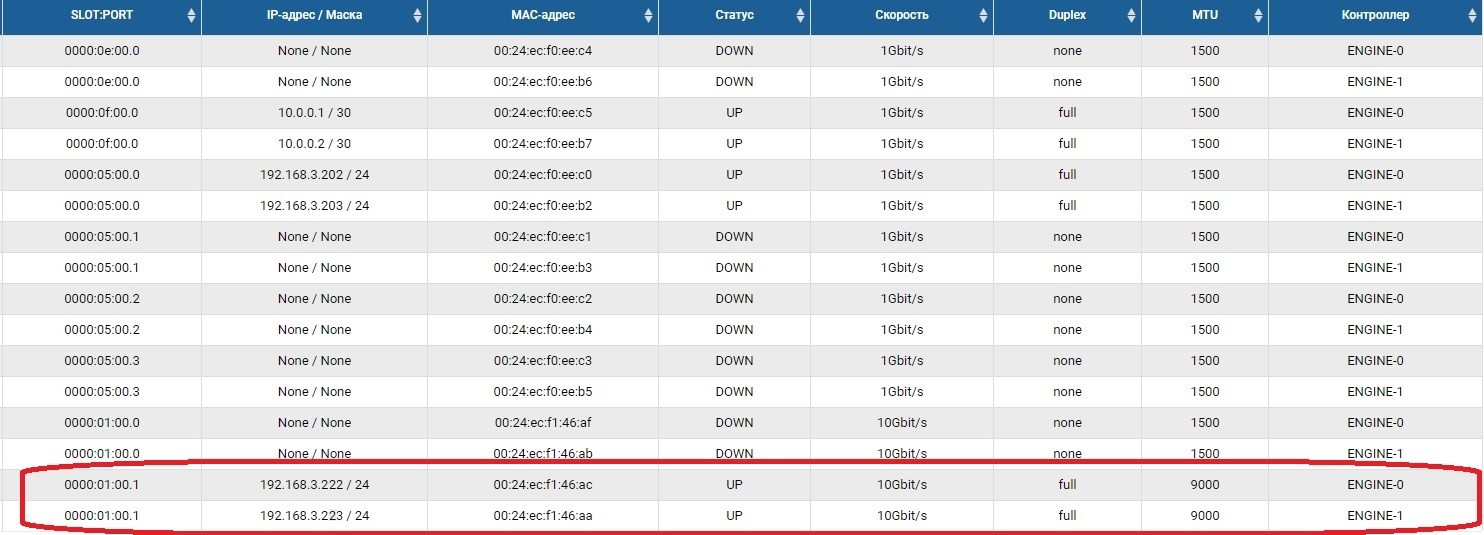
Первым делом нужно настроить сетевые порты, по которым будет передаваться трафик репликации. Для этого порты надо включить и задать на них IP-адреса в разделе Front-end адаптеры.
После этого нам нужно создать пул (в нашем случае RDG) и виртуальный IP для репликации (VIP). VIP — это плавающий IP-адрес, который привязан к двум «физическим» адресам контроллеров СХД (портам, которые мы настраивали только что). Он будет основным интерфейсом репликации. Также можно оперировать не VIP-ом, а VLAN-ом, если нужно работать с тегированным трафиком.
Процесс создания VIP-а для реплики мало чем отличается от создания VIP-а для ввода-вывода (NFS, SMB, iSCSI). VIP в данном случае мы создаем обычный (без VLAN), но обязательно указываем, что он для репликации (без этого указателя мы не сможем добавить VIP в правило на следующем шаге).
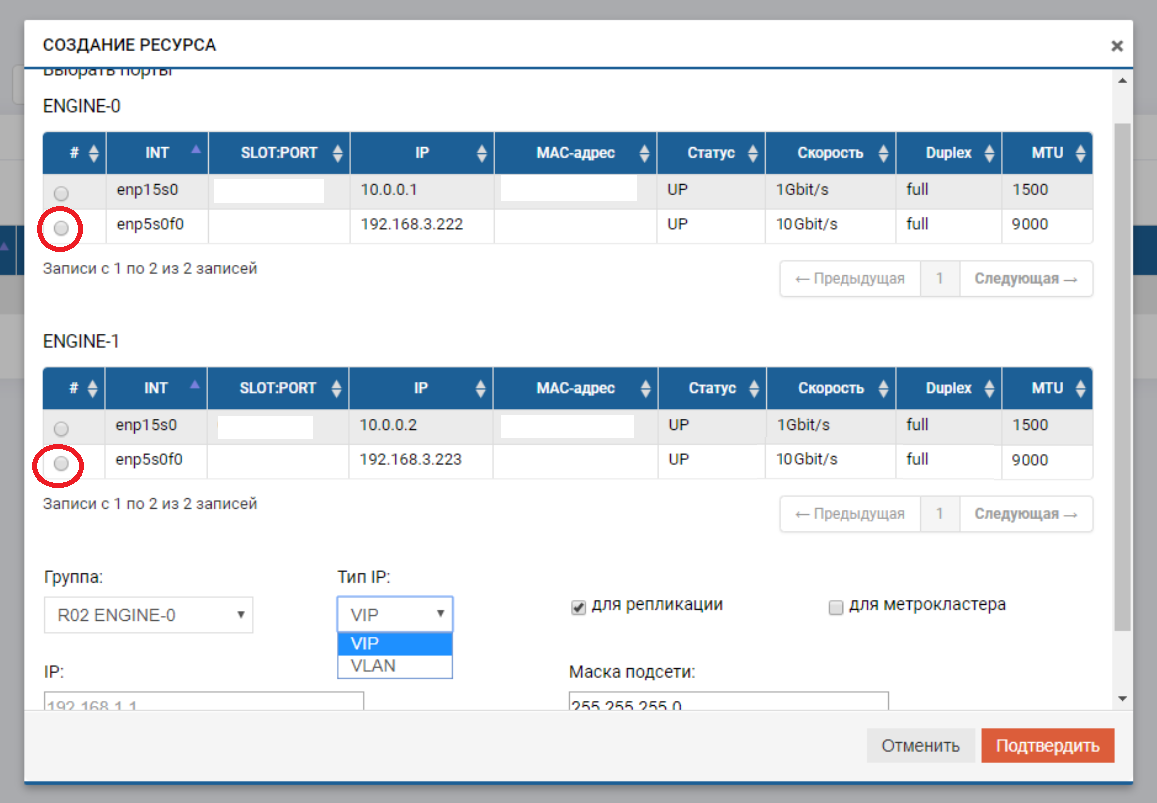
VIP обязательно должен быть в той же подсети, что и IP портов, между которыми он «плавает».

Повторяем эти настройки на удаленной СХД, с другим IP-шником, само собой.
VIP-ы с разных СХД могут быть в разных подсетях, главное, чтобы между ними была маршрутизация. В нашем случае как раз показан этот пример (192.168.3.XX и 192.168.2.XX)

На этом подготовка сетевой части завершена.
Настраиваем хранилища
Настройка хранилища под реплику отличается от обычного только тем, что маппинг мы делаем через специальное меню «Маппинг репликации». В остальном все так же, как с обычной настройкой. Теперь по порядку.
В ранее созданном пуле R02, требуется создать LUN. Создаём, называем его LUN1.
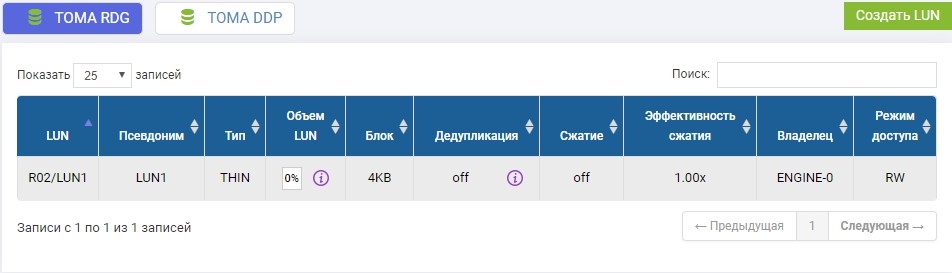
Также нам надо создать такой же LUN на удаленной СХД идентичного объема. Создаем. Чтобы избежать путаницы, удаленный LUN назовём LUN1R
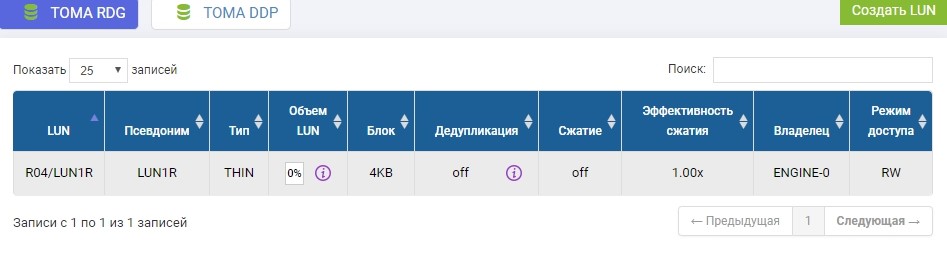
Если бы нам потребовалось взять LUN, который уже существует, то на время настройки реплики этот продуктивный LUN потребовалось бы отмнонтировать от хоста, а на удаленной СХД просто создать пустой LUN идентичного объема.
Настройка хранилища завершена, переходим к созданию правила репликации.
Настройка правил репликации или репликационных связей
После создания LUN-ов на СХД, которая будет на данный момент основной (Primary), настраиваем правило репликации LUN1 на СХД1 в LUN1R на СХД2.
Настройка производится в меню «Удаленная репликация»
Создаём правило. Для этого нужно указать получателя реплики. Там же задаём имя связи и тип репликации (синхронная или асинхронная).
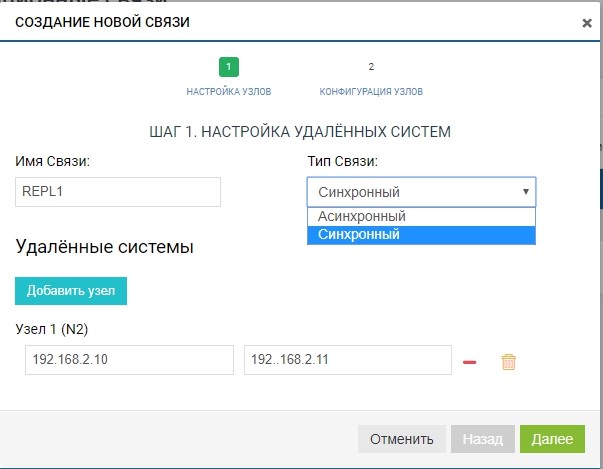
В поле «удаленные системы» добавляем нашу СХД2. Для добавления нужно использовать управляющие IP СХД (MGR) и имя удаленного LUN, в который мы будем выполнять репликацию (в нашем случае LUN1R). Управляющие IP нужны только на этапе добавления связи, трафик репликации через них передаваться не будет, для этого будет использоваться сконфигурированный ранее VIP.
Уже на этом этапе мы можем добавить более одной удаленной системы для топологии «one to many»: нажимаем кнопку «добавить узел», как на рисунке ниже.
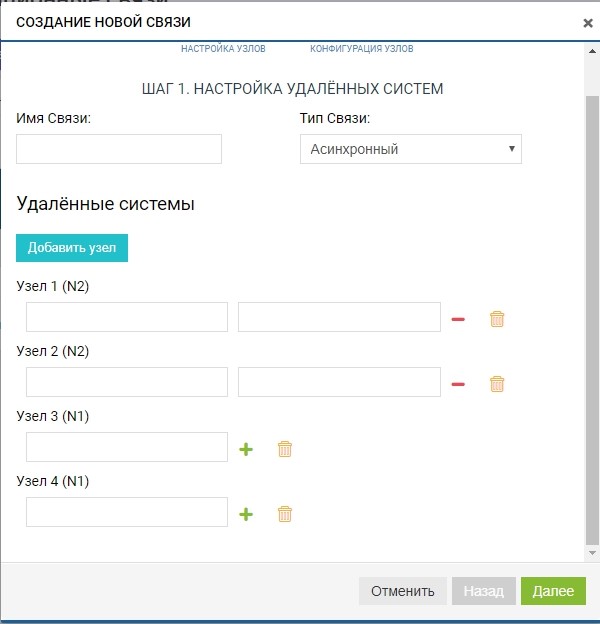
В нашем случае удаленная система одна, поэтому ограничиваемся этим.
Правило готово. Обратите внимание, что добавляется оно автоматически на всех участниках репликации (в нашем случае их два). Таких правил можно создать сколько угодно, для любого количества LUN-ов и в любые стороны. К примеру, мы можем для балансировки нагрузки часть LUN-ов реплицировать с СХД1 на СХД2, а другую часть наоборот – с СХД2 на СХД1.
СХД1. Сразу после создания началась синхронизация.
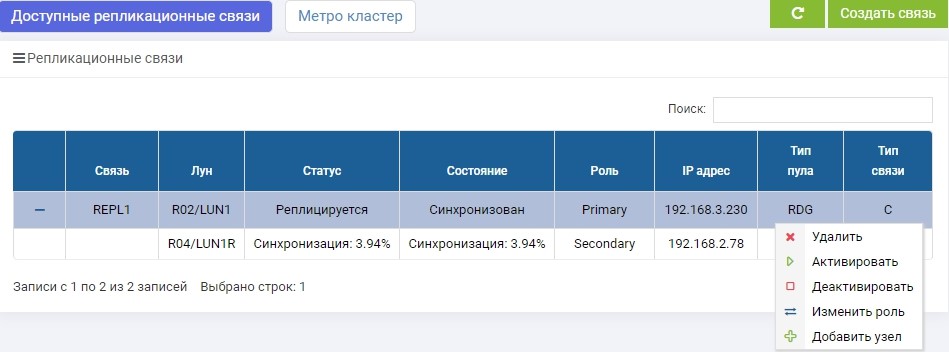
СХД2. Видим то же правило, но уже закончилась синхронизация.
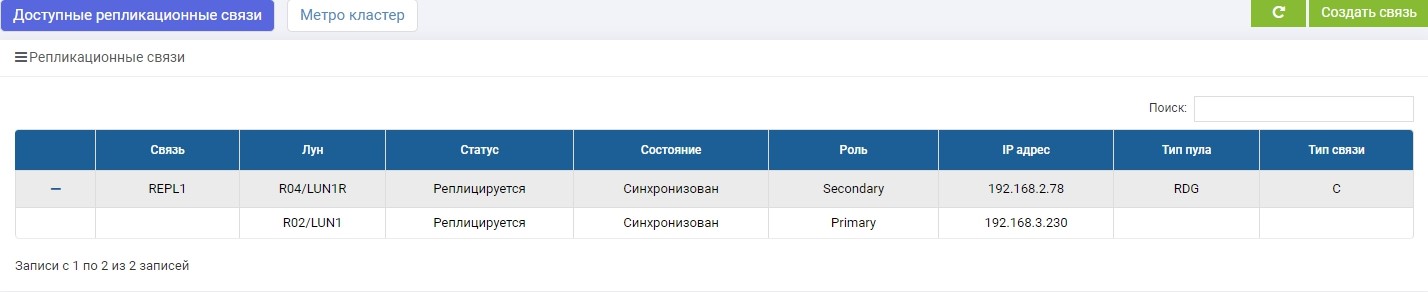
LUN1 на СХД1 находится в роли Primary, то есть он является активным. LUN1R на СХД2 находится в роли Secondary, то есть он находится на подхвате, на случай отказа СХД1.
Теперь мы можем подключить наш LUN к хосту.
Будем делать подключение по iSCSI, хотя можно делать и по FC. Настройка маппинга по iSCSI LUN-а в реплике практически не отличается от обычного сценария, поэтому подробно тут рассматривать это не будем. Если что, этот процесс описан в статье «Быстрая настройка».
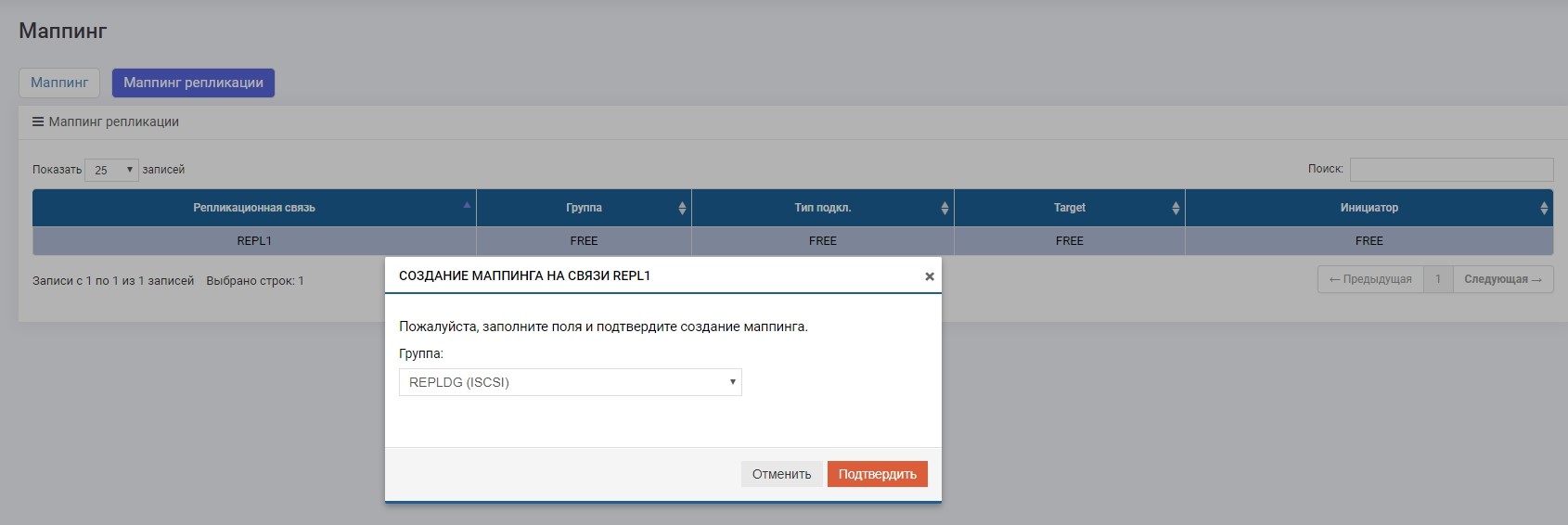
Единственное отличие – маппинг создаем в меню «Маппинг репликации»
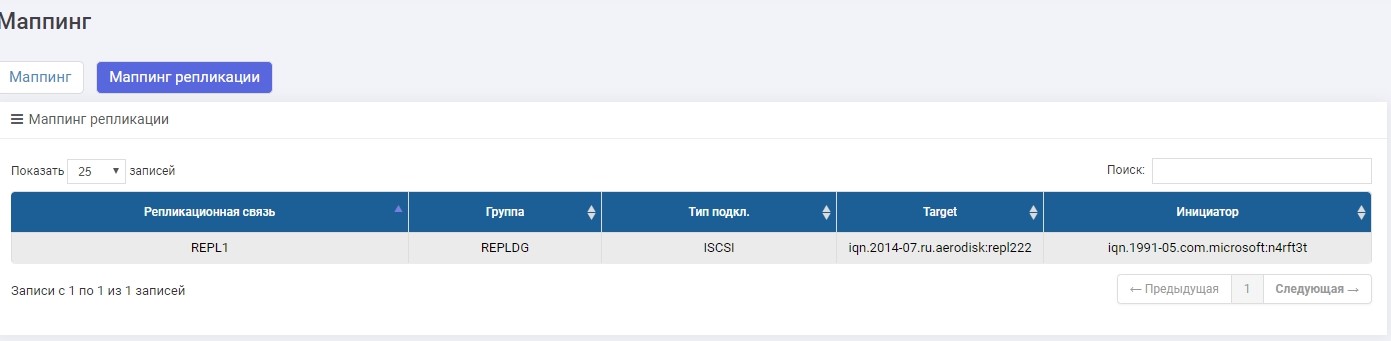
Настроили маппинг, отдали LUN хосту. Хост увидел LUN.
Форматируем его в локальную файловую систему.
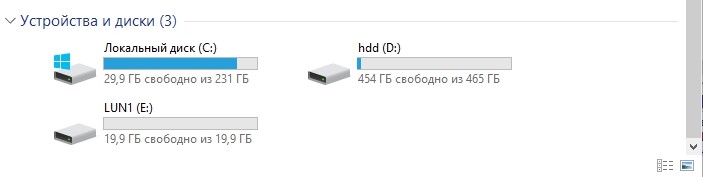
Все, на этом настройка завершена. Дальше пойдут тесты.
Тестирование
Тестировать мы будем три основных сценария.
- Штатное переключение ролей Secondary > Primary. Штатное переключение ролей нужно на случай, если, например, в основном ЦОД-е нам нужно выполнить какие-либо профилактические операции и на это время, чтобы данные были доступны, мы переводим нагрузку в резервный ЦОД.
- Аварийное переключение ролей Secondary > Primary (отказ ЦОД-а). Это основной сценарий, ради которого существует репликация, который может помочь пережить полный отказ ЦОД, не остановив работу компании на продолжительный срок.
- Обрыв каналов связи между ЦОД-ами. Проверка корректного поведения двух СХД в условиях, когда по каким-либо причинам недоступен канал связи между ЦОД-ами (например, экскаватор копнул не там и порвал тёмную оптику).
Для начала мы начнем писать данные на наш LUN (пишем файлы с рандомными данными). Сразу смотрим, что утилизируется канал связи между СХД. Это легко понять если открыть мониторинг нагрузки портов, которые отвечают за репликацию.
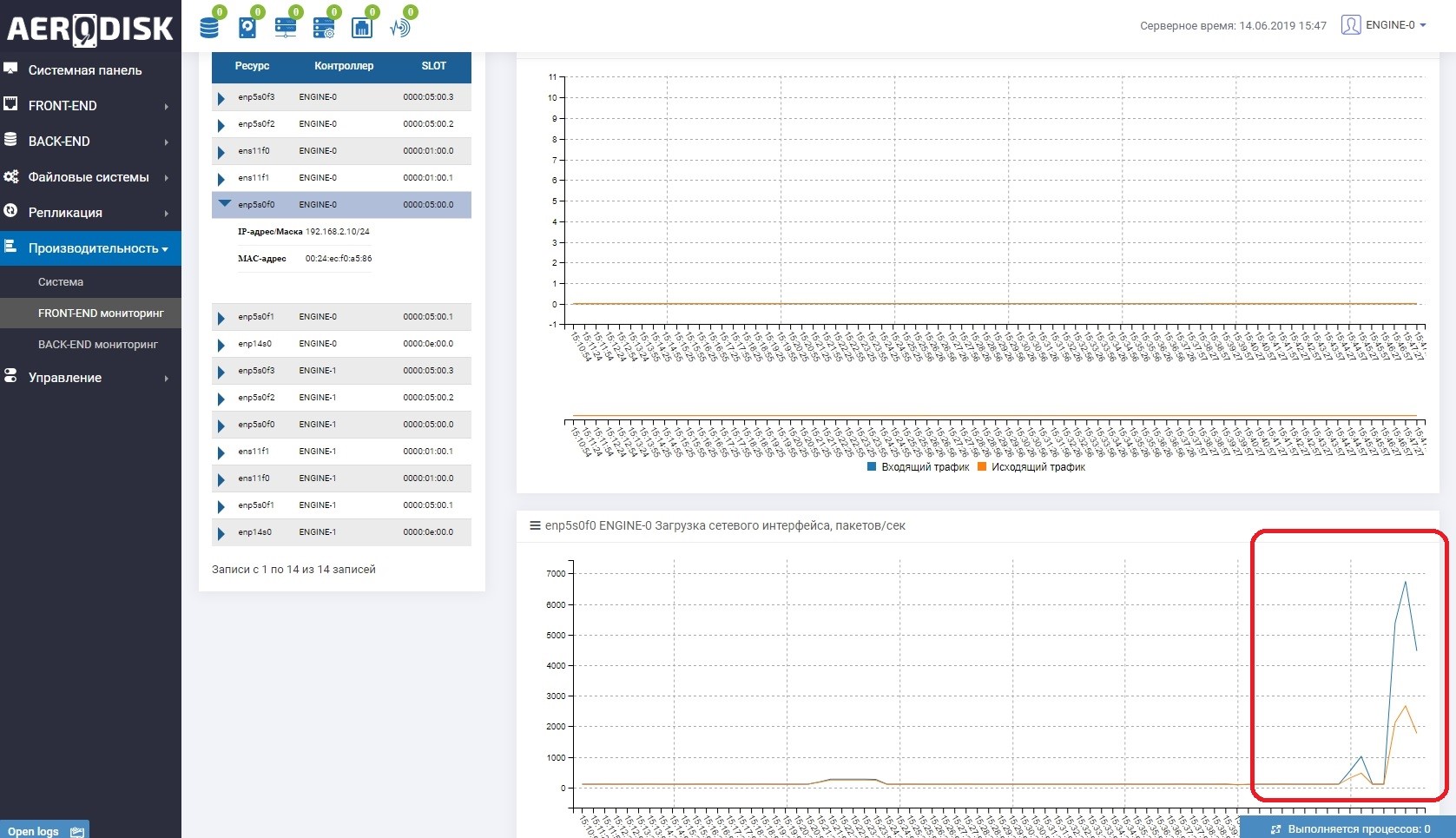
На обеих СХД есть теперь «полезные» данные, можем начинать тест.
![]()
На всякий случай, посмотрим хэш-суммы одного из файлов и запишем.
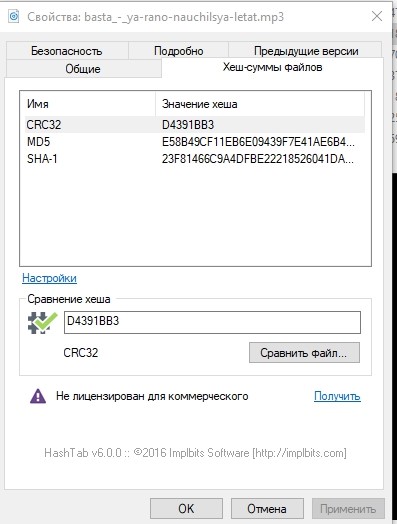
Штатное переключение ролей
Операцию по переключению ролей (изменению направления репликации) можно делать с любой СХД, но все равно сходить нужно будет на обе, поскольку на Primary нужно будет отключить маппинг, а на Secondary (которая станет Primary) включить его.
Возможно, сейчас возникает резонный вопрос: а почему бы это не автоматизировать? Отвечаем: все просто, репликация – это простое средство катастрофоустойчивости, основанное исключительно на ручных операциях. Для автоматизации этих операций существует режим метрокластера, он полностью автоматизирован, но его настройка значительно сложнее. О настройке метрокластера мы напишем в следующей статье.
На основной СХД отключаем маппинг, чтобы гарантированно остановить запись.
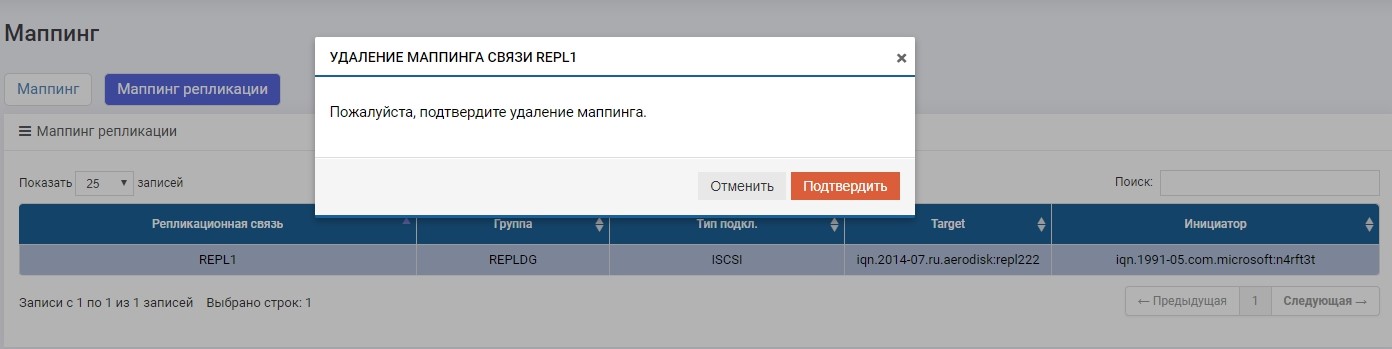
Потом на одной из СХД (не важно, на основной или резервной) в меню «Удаленная репликация» выбираем нашу связь REPL1 и нажимаем «Изменить роль».
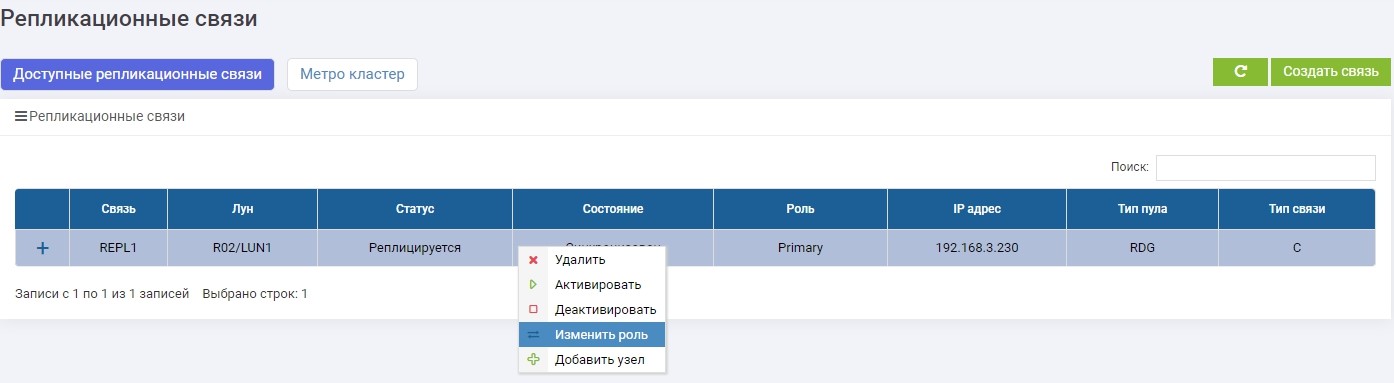
Через несколько секунд LUN1R (резервная СХД), становится Primary.
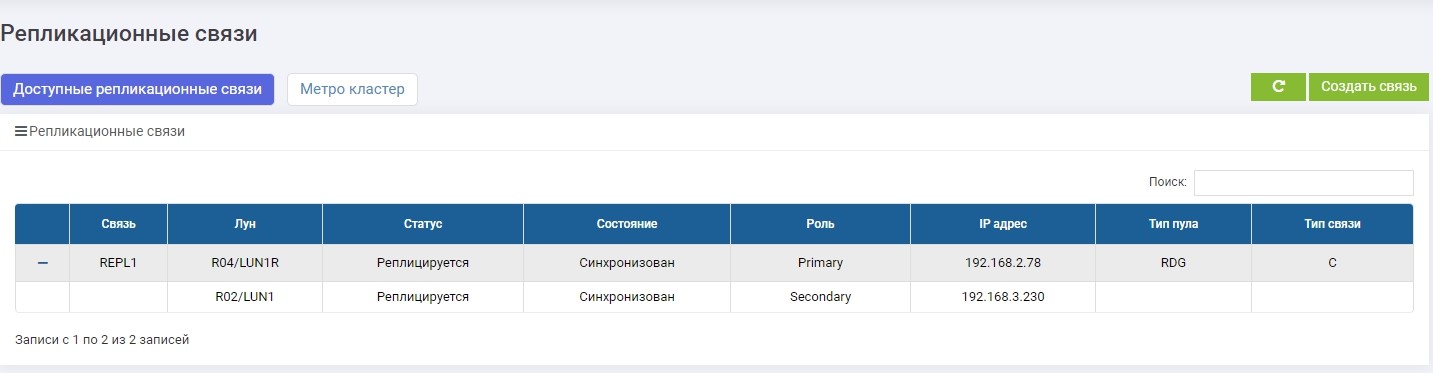
Делаем маппинг LUN1R с СХД2.
После этого на хосте автоматически цепляется наш диск E:, только на этот раз он «прилетел» с LUN1R.
На всякий случай, сравниваем хэш-суммы.
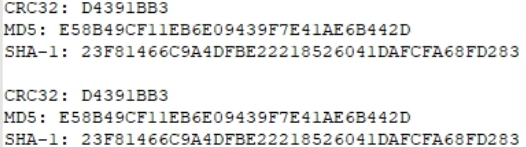
Идентично. Тест пройден.
Аварийное переключение. Отказ ЦОД-а
В данный момент основной СХД после штатного переключения является СХД2 и LUN1R, соответственно. Для эмуляции аварии мы отключим питание на обоих контроллерах СХД2.
Доступа к ней больше нет.
Смотрим, что происходит на СХД 1 (резервной на данный момент).

Видим, что Primary LUN (LUN1R) недоступен. Появилось сообщение об ошибке в логах, в информационной панели, а также в самом правиле репликации. Соответственно, данные с хоста сейчас недоступны.
Изменяем роль LUN1 на Primary.
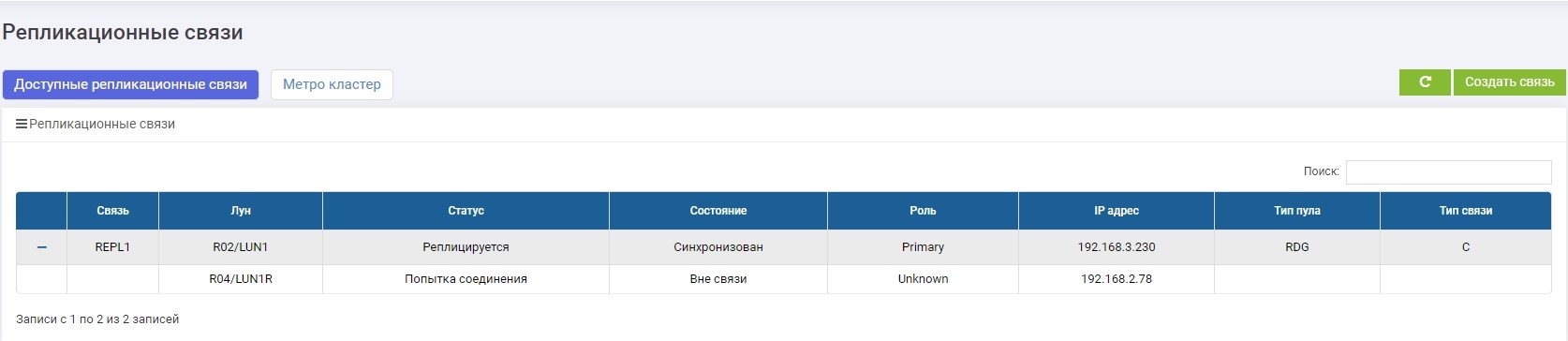
Делам маппинг к хосту.

Убеждаемся, что диск E появился на хосте.
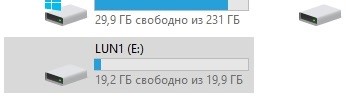
Проверяем хэш.
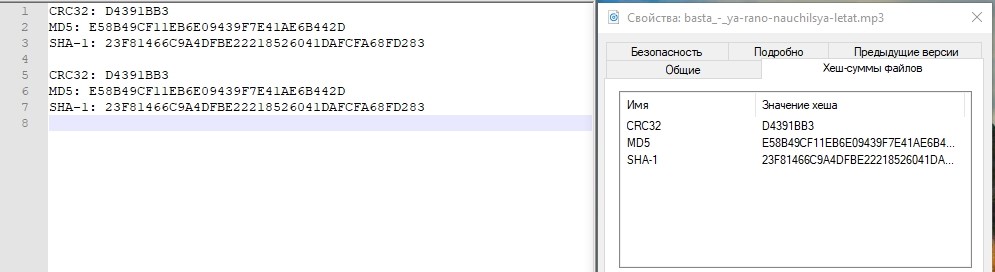
Все в порядке. Падение ЦОД-а, который был активный, СХД пережила успешно. Примерное время, которое мы потратили на подключение «разворота» репликации и подключение LUN-а из резервного ЦОД-а составило около 3-х минут. Понятно, что в реальном продуктиве все намного сложнее, и кроме действий с СХД нужно выполнить ещё множество операций в сети, на хостах, в приложениях. И в жизни этот промежуток времени будет значительно дольше.
Тут хочется написать, что все, тест успешно завершён, но не будем спешить. Основная СХД «лежит», мы знаем, что когда она «падала», она была в роли Primary. Что произойдет, если она внезапно включится? Будут две роли Primary, что равно порче данных? Сейчас проверим.
Идем внезапно включать лежащую СХД.
Она загружается несколько минут и после этого возвращается в строй после недолгой синхронизации, но уже в роли Secondary.

Все ок. Split-brain-а не случилось. Мы об этом подумали, и всегда после падения СХД поднимается в роли Secondary, независимо от того, в какой роли она была «при жизни». Теперь точно можно сказать, что тест на отказ ЦОД-а прошёл успешно.
Отказ каналов связи между ЦОД-ами
Главная задача этого теста – убедиться в том, что СХД не начнет чудить, если у неё временно пропадут каналы связи между двумя СХД, а потом появятся вновь.
Итак. Отключаем провода между СХД (представим, что их копнул экскаватор).
На Primary видим, что нет связи с Secondary.
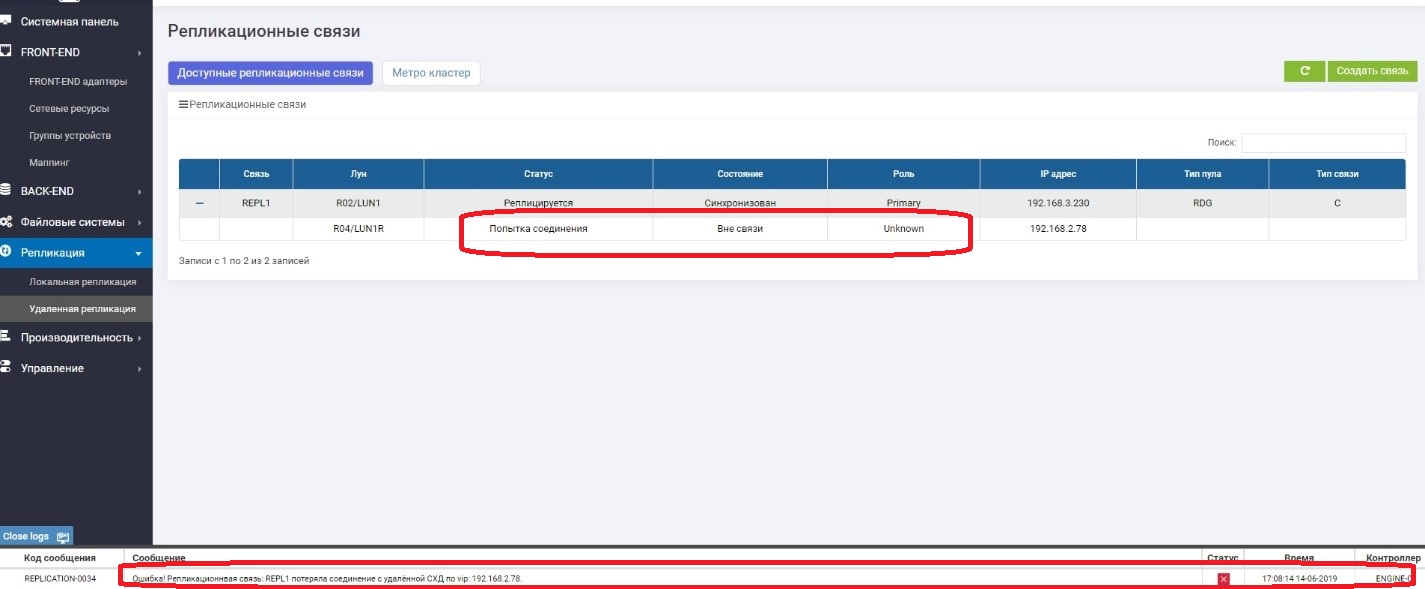
На Secondary видим, что нет связи с Primary.
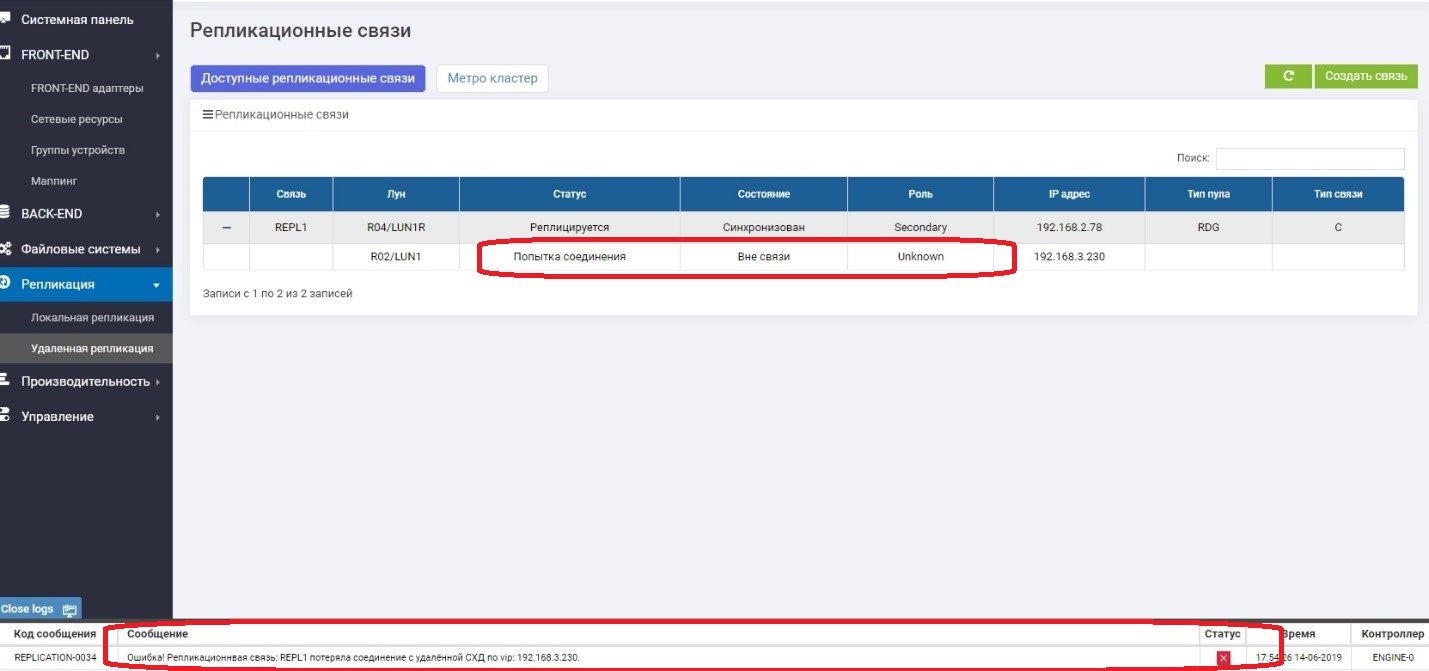
Работает все нормально, и мы продолжаем писать данные на основную СХД, то есть, они с резервной уже гарантировано отличаются, то есть «разъехались».
Через несколько минут «чиним» канал связи. Как только СХД друг друга увидели, автоматически включается синхронизация данных. Тут от администратора ничего не требуется.

Через некоторое время синхронизация завершается.
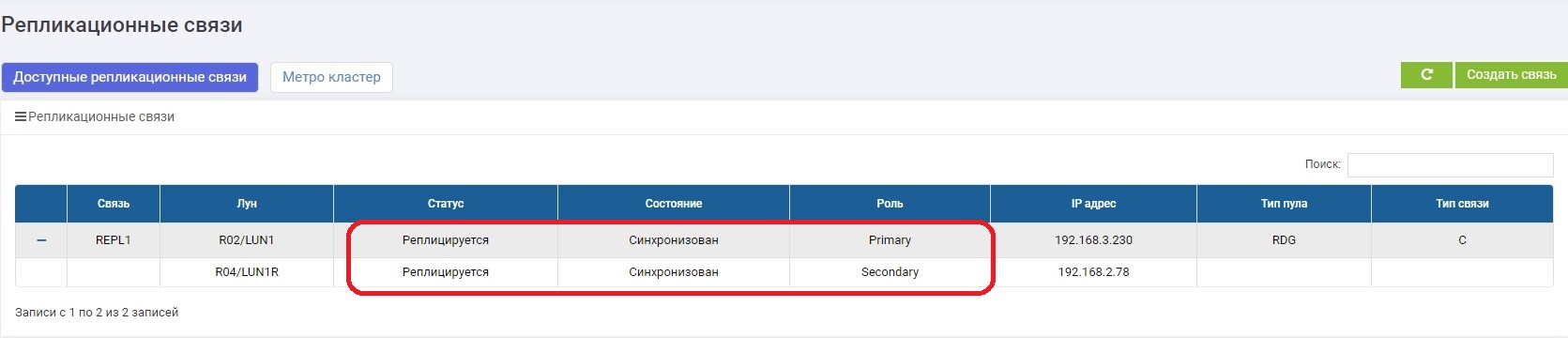
Соединение восстановлено, никаких нештатных ситуаций обрыв каналов связи не вызвал, а после включения автоматически прошла синхронизация.
Выводы
Мы разобрали теорию – что и зачем нужно, где плюсы, а где минусы. Потом настроили синхронную репликацию между двумя СХД.
Далее были проведены основные тесты на штатное переключение, отказ ЦОД-а и обрыв каналов связи. Во всех случаях СХД отработала хорошо. Потерь данных нет, административные операции сведены к минимуму для ручного сценария.
В следующий раз мы усложним ситуацию и покажем как вся эта логика работает в автоматизированном метрокластере в режиме active-active, то есть когда обе СХД являются основными, а поведение при отказах СХД полностью автоматизировано.
Пишите пожалуйста комментарии, будем рады здравой критике и дельным советам.
До новых встреч.
