
Начинающие разработчики часто используют курсоры с параметрами по умолчанию. Это продолжается до тех пор, пока кто-нибудь из старших разработчиков или администраторов баз данных не подскажет, что с параметром FAST_FORWARD все будет работать гораздо быстрее. Возможно, вы и сами исследовали этот вопрос и читали пост Аарона Бертрана (Aaron Bertrand) о бенчмарке производительности курсоров с различными параметрами. Признаюсь, в течение многих лет мне было все равно, почему FAST_FORWARD иногда ускорял мои запросы. В названии было слово "FAST", и мне было этого достаточно.
Но недавно я столкнулся с проблемой в продакшене, когда использование правильных параметров курсора привело к 1000-кратному улучшению производительности. Я решил, что десяти лет невежества достаточно, и, наконец, провел небольшое исследование различных вариантов курсоров. Этот пост содержит воспроизведение и обсуждение возникшей проблемы.
Воспроизведение проблемы
Приведенный ниже код создает таблицу размером 16 ГБ. Столбец ID определен как первичный ключ, он же кластеризованный индекс. На столбце ID2 создан некластеризованный индекс. Вы можете уменьшить значение TOP для уменьшения количества строк и создания таблицы меньшего размера, но не делайте его меньше 200 000.
DROP TABLE IF EXISTS tbl_1;
CREATE TABLE tbl_1 (
ID BIGINT NOT NULL,
ID2 BIGINT NOT NULL,
PAGE_FILLER VARCHAR(5000) NOT NULL,
PRIMARY KEY (ID)
);
INSERT INTO tbl_1 WITH (TABLOCK)
SELECT RN, RN % 100000, REPLICATE('Z', 5000)
FROM
(
SELECT TOP (2000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) q
OPTION (MAXDOP 1);
CREATE INDEX IX2 ON tbl_1 (ID2);Упрощенный пример проблемного SELECT'а с продакшена выглядит следующим образом:
Select ID
from tbl_1
WHERE ID2 < 1
ORDER BY ID;Фильтр очень селективный: под условие попадают только 20 строк из 2 миллионов. Я ожидаю, что оптимизатор запросов будет использовать индекс на ID2 и запрос выполнится мгновенно. В приведенной ниже хранимой процедуре определяется курсор FAST_FORWARD, который получает эти 20 строк и просто итерируется по ним, не делая больше ничего:
CREATE OR ALTER PROCEDURE CURSOR_WITH_FF
AS
BEGIN
SET NOCOUNT ON;
Declare @ID BIGINT;
Declare FF Cursor FAST_FORWARD for
Select ID
from tbl_1
WHERE ID2 < 1
ORDER BY ID;
Open FF;
Fetch Next from FF into @ID;
WHILE @@FETCH_STATUS = 0
BEGIN
Fetch Next from FF into @ID;
END;
Close FF;
Deallocate FF;
END;На моей машине выполнение этой хранимой процедуры занимает около 2 мс. План запроса в этом случае, очень похож на план для простого SELECT. Хотя в нем и есть некоторый дополнительный мусор от курсора, но в данном случае это не влияет на производительность:
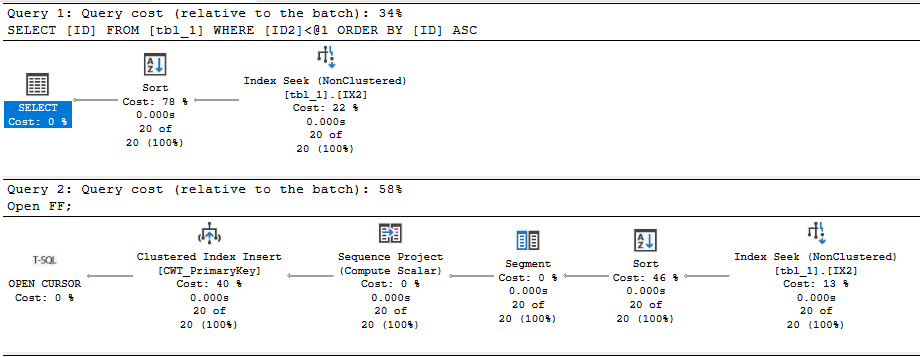
К сожалению, если убрать параметр FAST_FORWARD, то у меня этот код будет выполняться уже 50 секунд. Чем вызвана такая огромная разница?
Что происходит
Начнем с плана выполнения запроса для курсора по умолчанию:

Оптимизатор запросов решил выполнить Clustered Index Scan вместо использования индекса IX2. Мы получаем все строки от курсора, поэтому нам приходится читать всю таблицу. Это 20 сканирований, каждое из которых охватывает около 5% таблицы. Определенно стоит ожидать, что это менее эффективно плана с FAST_FORWARD. Но 50 секунд — это уж слишком медленно. Посмотрим на статистику ожиданий:

Неудивительно, что ввод-вывод вносит наибольший вклад во время ожидания (а как же иначе?). Но почему так много? У меня быстрое локальное хранилище со средней задержкой менее 1 мс. Для сравнения я решил попробовать принудительно использовать план запроса, выбранный курсором, но запустить его вне курсора. Следующий запрос выполнился на моей машине примерно за 8 секунд:
CHECKPOINT;
DBCC DROPCLEANBUFFERS;
Select ID
from tbl_1 WITH (INDEX(1))
WHERE ID2 < 1
ORDER BY ID
OPTION (MAXDOP 1);Используя sys.dm_io_virtual_file_stats, я обнаружил, что курсор выполнял около 240 000 операций ввода-вывода в среднем по 66 КБ на одну операцию. Одиночный SELECT выполнял около 10 000 операций ввода-вывода со средним размером операций ввода-вывода 1,7 МБ. Ключевое отличие заключается в том, что только первое выполнение запроса с курсором может выполнять упреждающее чтение (read-ahead reads):
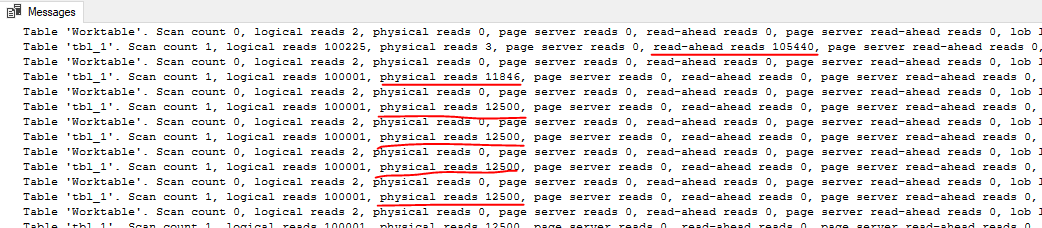
В случае с курсором упреждающее чтение (read-ahead reads) не выполняется для 95% операций ввода-вывода, необходимых для выполнения запроса. Даже задержка ввода-вывода менее миллисекунды может быть болезненной, когда вам нужно выполнить 240 000 операций ввода-вывода. Получается, что для эффективного поиска 20 строк курсор с FAST_FORWARD способен использовать индекс. Курсор с параметрами по умолчанию выполняет около 15 ГБ операций ввода-вывода, которые не могут быть использованы для упреждающего чтения.
При использовании облаков ситуация, конечно, будет намного хуже. При задержке в 5–10 мс для управляемых экземпляров общего назначения, можно ожидать, что курсор с параметрами по умолчанию будет выполняться от 20 до 40 минут. Ради забавы я решил протестировать это на управляемом экземпляре с 4 виртуальными ядрами. Курсор с параметром FAST_FORWARD выполнялся около 120 мс. С параметрами по умолчанию — около 70 минут. Вот статистика ожидания выполнения:

Но здесь есть и положительная сторона: использование правильных параметров курсора повысило производительность управляемого экземпляра в 35000 раз.
Почему это происходит
Начну с того, что я не хочу быть экспертом в области использования курсоров. Я бы предпочел быть экспертом по отказу от их использования. Я часто сталкивался со сложностями объяснения, почему у курсора по умолчанию такой плохой план запроса, но, к счастью, я нашел статью двенадцатилетней давности. Процитирую весь раздел о динамических планах (dynamic plan), потому что никогда не знаешь, когда исчезнет пост в блоге Microsoft:
«Динамический план может обрабатываться инкрементально. Для этого в SQL Server мы сериализуем состояние выполнения запроса в то, что мы называем "маркером". Позже мы можем построить новое дерево выполнения запроса, используя маркер для изменения положения операторов. Более того, динамический план может перемещаться вперед и назад относительно своей текущей позиции. Динамические планы используются как динамическими, так и некоторыми fast_forward-курсорами.
Динамический план состоит только из динамических операторов — операторов, поддерживающих маркеры и перемещение вперед и назад. Это соответствует, хотя и не в полной мере, обработке запросов потоковыми операторами (в отличие от stop-and-go). Но не все потоковые операторы динамические. В SQL Server динамический означает:
1. Оператор может быть перепозиционирован в текущее положение с помощью маркера или в относительное положение (следующее или предыдущее) по отношению к текущему.
2. Состояние оператора должно быть небольшим, чтобы маркер был маленьким. В операторе не могут храниться данные строки. В частности, отсутствуют таблица сортировки (sort table), хеш-таблица (hash table) и рабочая таблица (work table). Нельзя сохранить даже одну строку, поскольку одна строка может быть очень большой.
Без динамического плана курсору потребуется временное хранилище для хранения набора результатов запроса (или его набора ключей). Динамический план ничего подобного не делает! Однако некоторые операторы дисквалифицируются, например, hash join, hash agg, compute sequence и sort. Это приводит к неоптимальным планам.»
Короче говоря, вы можете считать динамический план похожим на план без блокирующих операторов, но с некоторыми дополнительными ограничениями. Из надежных источников мне стало известно, что курсор с параметрами по умолчанию всегда будет выбирать динамический план, если он доступен. Для нашего SELECT динамический план действительно доступен. Можно использовать упорядоченный кластеризованный индекс для получения отсортированных строк без выполнения явной сортировки. Индекс IX2 нельзя использовать для сортировки, потому что я фильтрую по условию с неравенством по ID2. Изменение условия на равенство позволит использовать динамический план с индексом IX2:
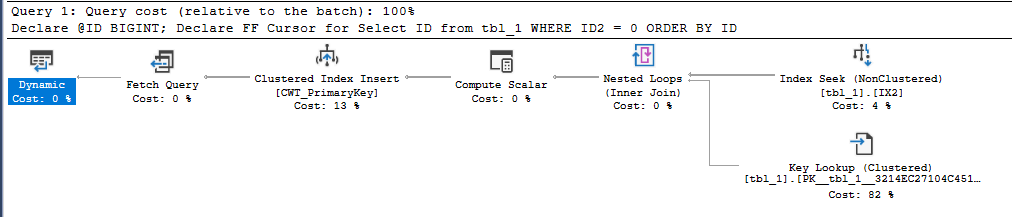
А что насчет других параметров курсоров? Если вернуться к исходному запросу, то указание параметра STATIC или KEYSET позволяет избежать плохого плана запроса и использовать индекс IX2 с Index Seek. Оба этих параметра записывают набор данных курсора в таблицу базы данных tempdb, поэтому интуитивно понятно, что не будет какого-либо ограничения, вызывающего Clustered Index Scan.
Указание параметра FAST_FORWARD позволяет оптимизатору запросов выбирать между статическим и динамическим планом. В данном случае статический план, очевидно, намного эффективнее, и оптимизатор запросов знает об этом. Он выбирает статический план, который не выполняет Clustered Index Scan.
Для полноты картины, указание параметра READ_ONLY также приводит к Index Seek, если не указан параметр DYNAMIC.
В общем, я бы сказал, что FAST_FORWARD по-прежнему остается хорошей отправной точкой для ваших курсоров, если связанные с ним ограничения допустимы в вашем приложении. Для получения производительности, аналогичной обычному SELECT, одного FAST_FORWARD не всегда достаточно. Как отмечает Эрик, при использовании этого параметра вы получите запрос с MAXDOP 1. Оптимизатор запросов также может выбрать худший динамический план вместо статического плана, если предполагаемая стоимость плана запроса не соответствует действительности. Использование STATIC вместо FAST_FORWARD в некоторых случаях может быть весьма полезным, но чтобы знать наверняка необходимо протестировать ваш курсор. Конечно, вы можете написать код и без использования курсора.
Уменьшение прав доступа
Я постоянно ищу интересные примеры и обратил внимание на следующий момент в документации:
Если в DECLARE CURSOR не указать READ_ONLY, OPTIMISTIC или SCROLL_LOCKS, то значения по умолчанию выглядят следующим образом:
Если инструкция SELECT не поддерживает обновления (недостаточно разрешений, доступ к удаленным таблицам, не поддерживающих обновление, и т. д.), то курсор становится READ_ONLY.
Смогу ли я повысить производительность, запустив код под пользователем с меньшими привилегиями? К сожалению, у меня не получилось это воспроизвести. Я создал логин 'erik', который не может изменять данные в таблице, но получил такой же план запроса, как и раньше. Также не было никаких изменений в столбце properties в sys.dm_exec_cursors.
Не знаю, может это ошибка в документации или я что-то сделал не так своей стороны. Было бы интересно посмотреть на работающий пример этого.
Заключение
Некоторые запросы могут иметь крайне низкую производительность с параметрами курсора по умолчанию. Вы можете идентифицировать подобные запросы, отсортировав их по общему количеству логических чтений в стандартных отчетах Query Store в SSMS. В нашей продуктивной среде у нас было несколько курсоров, которые выполняли гораздо больше логических чтений, чем все остальные, поэтому обнаружить их было не сложно. Мы значительно ускорили некоторые из них, просто добавив параметр FAST_FORWARD.
Всех заинтересованных приглашаем завтра в 20:00 на открытый урок OTUS на тему «Использование и оптимизация хранимых процедур в MS SQL Server». На занятии рассмотрим вечный вопрос: "где логика?" В приложении или в базе данных? Поговорим, чем полезны хранимые процедуры и как оптимизировать их производительность в MS SQL Server.
