
Введение
Сегодня одним из наиболее эффективных способов повышения производительности и минимизации затрат в системах баз данных является отказ от излишних операций, таких как чтение данных с уровня хранения (например, с дисков или из удаленного хранилища), их передача по сети или даже материализация данных при выполнении запроса. Apache Hive изначально улучшает выполнение распределенных запросов, передавая предикаты фильтров столбцов обработчикам подсистемы хранения, таким как HBase, или «читателям» данных в колоночном формате, например Apache ORC. Оценка этих предикатов вне механизма выполнения дает меньше данных для оценки запроса (сокращение данных) и приводит к уменьшению времени выполнения запроса и количества операций ввода-вывода.
Задача
Чтобы задействовать возможности сокращение данных, в современных колоночных форматах, такие как ORC и Parquet, поддерживаются индексы, фильтры Блума и статистика. Это позволяет определить, нужно ли вообще читать группу данных перед возвратом к механизму выполнения. Но даже несмотря на то, что эта статистика может значительно уменьшить количество операций ввода-вывода, запрос может потребовать декодирования множества дополнительных строк, которые вовсе не нужны для его оценки. Частично это связано с тем, что внутренняя обработка строк выполняется в колоночном формате группами (по тысячам или по строкам). Это делается для повышения эффективности сжатия и снижения затрат на индексацию и ведение статистики.
Фактически, после серии экспериментов в CDP Public Cloud с использованием Hive мы заметили, что даже для запросов с низкой избирательностью, таких как запрос 43 TPC-DS (Q43), при выборке около 7% от общего числа строк мы в конечном итоге тратим почти 30% времени ЦП на декодирование строк, которые в конечном итоге будут отброшены!
Ленивое декодирование
Вышеупомянутое наблюдение вдохновило на создание функции ленивого или отложенного декодирования (lazy decoding) или пробного кода (probecode), описанной в этом посте. Чтобы читать только те столбцы, которые являются обязательными для оценки, probedecode перед декодированием любого из оставшихся столбцов при сканировании больших таблиц использует существующие предикаты запроса. Таким образом минимизируется число материализованных строк, проходящих через конвейер оператора.
Поддержка отложенного декодирования, которая недавно была представлена в Apache Hive, добавлена в CDP Runtime 7.2.9 и CDP Public Cloud вместе с соответствующей функцией фильтрации на уровне строк в ORC.
Используя probedecode, Hive может избежать материализации данных, которые не нужны для оценки запроса, сэкономить циклы ЦП, уменьшить емкость выделяемой памяти и даже исключить операторы фильтра из конвейера. Для этого Hive использует существующие предикаты и условия соединения, которые теперь передаются операторам TableScan. Когда эта функция включена, прежде чем материализовать любой из оставшихся столбцов, оператор TableScan считывает заранее только подмножество столбцов, к которым применяются предикаты. После применения предикатов он отслеживает строки, которые действительно соответствуют запросу, и декодирует из оставшихся столбцов только выбранные строки (если они есть).
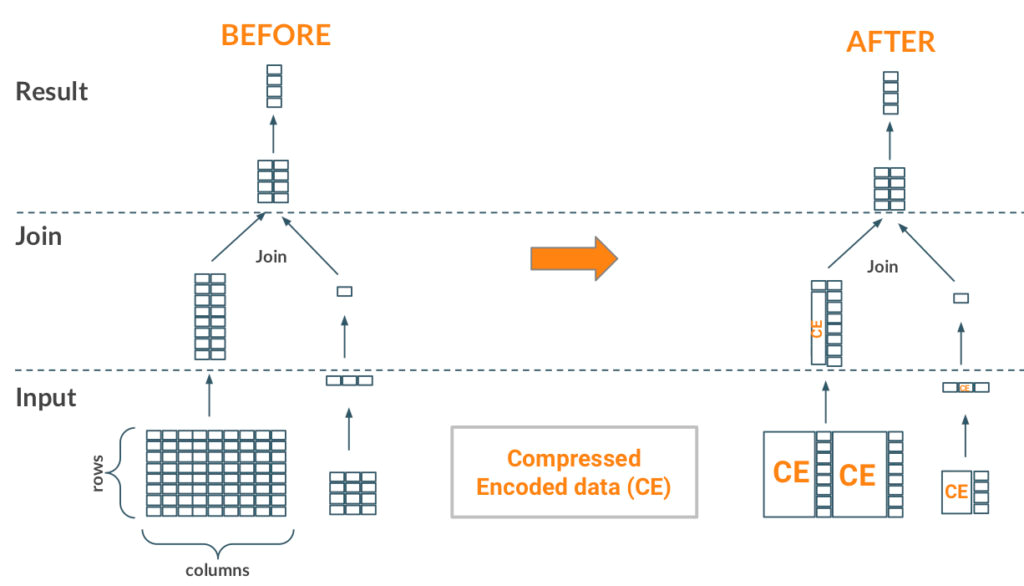
MapJoin может напрямую извлечь выгоду из функции probedecode. При объединении небольшой таблицы (правая сторона) и большой таблицы (левая сторона) мы обычно читаем всю маленькую таблицу и транслируем сгенерированную хеш-таблицу задачам, сканирующим большую таблицу. В таком сценарии задачи на стороне большой таблицы для декодирования только совпадающих ключей (строк) из оставшихся (неключевых) столбцов могут использовать ключи передаваемой таблицы на левой (потоковой) стороне. На приведенном выше рисунке можно заметить, что из двух проецируемых столбцов ключевой столбец декодируется раньше, чтобы найти только строку, соответствующую передаваемым ключам, и, таким образом, декодировать одну строку из второго столбца вместо того, чтобы декодировать все полностью.
Пользователи Hive могут проверить, как оптимизация probedecode применяется к их запросам MapJoin, используя свои стандартные планы пояснения запросов. Например, в приведенном ниже плане можно найти новое поле probeDecodeDetails оператора TableScan. В этом конкретном запросе оператор будет декодировать столбец ss_item_sk, затем выполнит поиск в хэш-таблице MAPJOIN_48 (транслируемой) и, наконец, будет декодировать только совпадающие строки из столбца ss_ext_sales_price, как в приведенном выше примере (обратите внимание, что ss_sold_date_sk является столбцом раздела).
Map 1 <- Map 4 (BROADCAST_EDGE), Map 5 (BROADCAST_EDGE)
Reducer 2 <- Map 1 (SIMPLE_EDGE)
Reducer 3 <- Reducer 2 (SIMPLE_EDGE)
Vertices:
Map 1
Map Operator Tree:
TableScan
alias: store_sales
probeDecodeDetails: cacheKey:MAPJOIN_48, bigKeyColName:ss_item_sk
Statistics: Num rows: 82510879939 Basic stats: COMPLETE Column stats:COMPLETE
TableScan Vectorization:
native: true
Select Operator
expressions: ss_item_sk (type: bigint), ss_ext_sales_price (type: decimal(7,2)), ss_sold_date_sk (type: bigint)
outputColumnNames: _col0, _col1, _col2
Select Vectorization:
className: VectorSelectOperator
native: true
projectedOutputColumnNums: [1, 14, 22]
Statistics: Num rows: 82510879939 Basic stats: COMPLETE Column stats:COMPLETE
Map Join Operator
condition map:
Inner Join 0 to 1
keys:
0 _col2 (type: bigint)
1 _col0 (type: bigint)
Map Join Vectorization:
bigTableKeyColumns: 22:bigint
className: VectorMapJoinInnerBigOnlyLongOperator
input vertices:
1 Map 4Производительность
Хотя запросы, выполняемые с включенной функцией probedecode, всегда используют меньше строк, генерируемых операторами сканирования, преимущество гораздо более выражено в высокоселективных запросах с большим количеством проецируемых столбцов, отличных от тех, которые используются в предикатах (большее количество столбцов приводит к большей экономии ресурсов ЦП. ).
В серии тестов мы наблюдали улучшения времени выполнения в диапазоне от 5% до 50%, а ниже также показаны некоторые результаты теста TPC-DS. Тест был выполнен с коэффициентом масштабирования 10, данные хранились в формате ORC, а Hive выполнялся в публичном облаке CDP Public Cloud с 4 узлами.
Как показано на рисунках ниже, в TPC-DS Q43 функция probedecode сокращает количество генерируемых строк на 40%, одновременно улучшая время выполнения до 35%. Также примечательно, выигрыш может зависеть от типа ключа соединения, так как некоторые типы данных более затратны при десериализации и поиске, чем при других операциях (см. Multikey). Для Q43 при использовании разных типов ключей соединения улучшение варьируется от 24% для длинного ключа соединения до 28% для строкового ключа соединения и до 35% для более сложного ключа соединения, такого как временная метка для этого конкретного запроса.


Доступность функций
Начиная с CDP 7.2.9 в CDP Public Cloud у пользователей, выполняющих запросы MapJoin в таблицах ORC, данный функционал будет включен по умолчанию. Мы настоятельно рекомендуем выполнить обновление, чтобы получить эту функцию и многие другие улучшения производительности. Для дополнительных сведений об оптимизации ознакомьтесь с перечисленными ниже тикетами Hive и ORC и посмотрите наш доклад на ApacheCon!
Также на подходе поддержка ленивой материализации для статических предикатов, наряду с другим блогом и новыми результатами, так что следите за обновлениями!
Ссылки
