
Я не знаю, что такое символьное программирование, но расскажу вам о нем на примере Wolfram Language
Кликбейтный заголовок, риторический вопрос и обещание раскрыть тайну! Не самый лучший набор, но нормального названия для статьи мне в голову не пришло. Что же здесь все-таки будет? Речь пойдет о реализации символьного программирования в Wolfram Language (WL). Я не буду рассказывать про отличия от других парадигм. А также здесь точно не будет общих определений. Вместо этого я попытаюсь ответить на несколько вопросов исходя из своего личного опыта и наблюдений. Вот эти вопросы
Почему все говорят, что WL реализует символьное программирование?
Что такое символьное программирование в WL по мнению респондентов?
Как эта парадигма реализована на самом деле в WL?
Внимание! Я не математик и не знаю haskell и lisp! И буду рад если меня поправят настоящие математики, которые с ними знакомы.
Что думают респонденты?
Я общался на тему символьного программирования с различными людьми напрямую, а так же читал посты, заметки и комментарии. И вот какое усредненное мнение дали мои наблюдения: символьное программирование это такая штука, которая позволяет получать формальные доказательства и совершать аналитические преобразования математических формул в виде кода. Т.е. для примера этот подход отлично работает для вычисления пределов функций. Либо для аналитического решения уравнений. Либо для взятия интегралов и вычисления производных. В общем все то, чем в повседневной жизни пользуются физики и математики.
Так ли это? Отчасти да. Где мы может наблюдать нечто подобное? Например, в замечательной библиотеке SymPy для языка программирования Python. На Хабре есть множество статей посвященных этой библиотеке. Мне например попадались статьи "Символьные вычисления средствами Python. Часть1. Основы" и "SymPy и симуляция физических процессов", где все довольно подробно объяснено. Большинство других статей и руководств к этой библиотеке акцентируют свое внимание именно на решении математических или логических задач. А пользователи видят применение символьному программированию только для решения задач математического анализа - т.е. аналитическое решение уравнений, взятие интегралов и т.д. На мой взгляд это слишком ограниченная точка зрения.
С чего все началось?
Мы будем говорить о WL и все примеры кода будут на нем. Раньше Mathematica преподносилась как система компьютерной алгебры. И действительно вышло так, что она началась именно с решения аналитических задач. Первое, что рассказывают студентам математических и физических специальностей - это то, как использовать Mathematica для работы с алгебраическими выражениями. Вот простейший пример:
Simplify[(x + 1)*(x - 1)]
(* -1 + x^2 *)Что делает эта функция? Очевидно она упрощает символьное выражение! Я уверен, что многие слышали про такие возможности WL. А вот еще пример:
D[x^2 + x + 1, x]
(* 1 + 2 x *)Эта функция дифференцирует символьное выражение по указанной переменной. В чем красота этих двух строчек кода? В том, что мы никак не объявили переменную x. Мы можем написать любой полином или формулу так, как если бы делали это в тетради на уроке математики. И оно будет работать! Кажется, что это очень просто и не имеет никакой реальной пользы, но давайте рассмотрим концепцию более подробно.
Атомы и выражения
Примеры кода выше - это выражения. В частном случае они представляют собой алгебраические выражения, которые, как я уже неоднократно повторял, нужны математикам. Выражение в WL - это составной объект, который можно сконструировать из других объектов, либо из примитивных типов - атомов. Всего существует 6 атомарных типов. Вот они:
Integer- целое числоReal- действительное число с плавающей точкойRational- рациональное число в виде отношения двух целыхComplex- комплексное числоString- строкаSymbol- собственно символы, ради которых мы все здесь собрались.
Больше ничего в Wolfram Language нет. Абсолютно все выражения и конструкции языка представляют собой древовидную структуру состоящую из атомов. Как я могу это проверить? Очень просто, в WL есть функция, которая отображает выражение в виде синтаксического дерева так, что в узлах дерева располагаются только атомы:
TreeForm[a + b + c]
Слева представлено почти самое простое выражение, которое можно создать на WL. Проще будет только f[]. На нулевом уровне у него находится функция Plus, а на первом уровне три переменные, к которым эта функция применена. И каждый узел дерева является символом. Давайте посмотрим как выглядит что-нибудь более сложное:
TreeForm[Sin[Pi] + Sqrt[a + 2] - x^2 / z]
Ого, здесь уже не только символы но и числа. И все равно мы получили древовидную структуру. Кроме чисел и необъявленных переменных - символов, здесь так же есть функции для сложения, умножения и возведения в степень. Правда почему-то нет вычитания, деления и корня. Дело в том, что они однозначно выражаются через обратные операции. Sqrt[x] заменяется на Power[x, 1/2], т.е. по сути на x^1/2, а x - y заменяется на Plus[x, Times[-1, y]], т.е. на самом деле вычитание - это прибавление отрицательного числа. А если это не число, а выражение или символ, то чтобы получить его - мы просто умножаем все на -1. Вы обратили внимание, что арифметическиt операции тоже располагаются в узлах дерева и отображаются как символы? Все потому что они ими и являются. Все арифметические операции это просто функции языка, которые имеют псевдонимы для более короткой записи. Вот несколько примеров:
a + b === Plus[a, b]a * b === Times[a, b]a ^ b === Power[a, b]a && b === And[a, b]a || b === Or[a, b]
Такой способ хранения внутренних объектов языка дает полный доступ ко всей структуре любого выражения. Это означает, что мы можем менять части выражения, удалять и добавлять. Давайте посмотрим на простой пример. Создадим переменную и сохраним в нее выражение:
expr = a * b + c ^ dКак оно выглядит в ядре WL:
TreeForm[expr]
А теперь при помощи функции Part (expr[[i]]) попробуем извлечь части этого выражения. Если мы указываем индексы больше нуля, то извлекаем части внутри квадратных скобок - это тело выражения. Если мы берем нулевую часть - то нам возвращается то, что стоит перед квадратными скобками - это называется заголовок выражения. Еще заголовок можно получить при помощи функции Head.
expr[[0]]
(* Plus - заголовок *)
expr[[1]]
(* a*b == Times[a, b] - первая часть тела*)
expr[[2]]
(* c^d == Power[c, d] - вторая часть тела *)
expr[[1, 0]]
(* Times - заголовок первой части *)
expr[[1, 1]]
(* a *)
expr[[1, 2]]
(* b *)А так же мы можем присвоить новое значение части вот так:
expr[[1, 1]] = e;
expr[[1, 0]] = Power;
expr[[2]] = f;
TreeForm[expr]
Мы изменили выражение напрямую. Более того, мы заменили не только сами переменные, но и функции, которые к ним применены! Не в первый раз я уже использую слово заменили. Выше я использовал внутренние индексы, т.к. точно знал, что и в какой части синтаксического дерева располагается. Что если я не знаю, что внутри, или структура дерева намного больше? Для этого есть специальный синтаксис, который позволяет заменять части выражения не по расположению, а по значению! Это функции Rule и ReplaceAll. У них есть сокращенные записи:
Rule[a, b] === a -> b
ReplaceAll[a, b] === a /. bИ вот как они применяются:
expr
(* e^b + f *)
expr /. b -> g
(* e^g + f *)Выше мы заменили показатель степени. В сокращенной форме синтаксис легко читается как заменить в выражении слева от /. по правилу справа все встречающиеся символы b на символ g. Это и произошло. То, что мы сейчас пронаблюдали - это применение правила замены. Опять же, я очень долго тяну и никак не дойду до сути, но нам нужно запомнить эту штуку. Так как символы, правила и замены это САМАЯ важная часть языка Wolfram.
Давайте посмотрим на правила замены в других примерах. Допустим, я знаю правила дифференцирования простых функций. И я могу записать их вот так:
diffRules = {
Sin[x] -> Cos[x],
Cos[x] -> -Sin[x],
x^2 -> 2*x,
x -> 1,
Log[x] -> 1/x
}; Здесь фигурные скобочки просто означают список элементов. По сути я записал набор правил для дифференцирования. Где слева от стрелочки то, что мы дифференцируем, а справа то, что получаем. При этом и слева и справа записаны символьные выражения - то есть по сути это древовидные структуры из 6 типов атомов. По правде говоря и сам список правил и символ стрелочки - это такие же выражения. Теперь попробуем записать какое-нибудь выражение:
expr = Sin[x] - x^2 + Log[x]И применим к нему правила дифференцирования
expr /. diffRules
(* 1/x - 2 x + Cos[x] *)Все сработало! Мы продифференцировали функцию по нашим правилам!
Шаблоны
Теперь другой пример. Допустим у меня есть выражение:
expr = a^2 + 3 * b^3 - c^4 + 2 * x^2 - x + 4*c + 3И я хочу это выражение линеаризовать, т.е. отбросить все степени выше первой. Я могу сделать это напрямую, как в примерах выше:
expr /. {
a^2 -> 0,
b^3 -> 0,
c^4 -> 0,
x^2 -> 0
}
(* 3 + 4 c - x *)Но это слишком неудобно. Что если я не знаю ни точную степень, ни имя переменной? Как просто указать, что нужно заменить все места, где встречается возведение в степень на ноль? Это можно сделать при помощи шаблонов вот так:
expr /. Power[_, _] -> 0
(* 3 + 4 c - x *)Либо вот так:
expr /. _ ^ _ -> 0
(* 3 + 4 c - x *)В примерах выше я использовал символ подчеркивания так, будто бы это регулярное выражение в строке или безымянный символ, который означает "все что угодно". Это подчеркивание называется шаблоном. Мы использовали самый простой типа шаблона из всех существующих. Для того, чтобы лучше понять, что я умею ввиду - я скажу, как правильно прочитать последний код: заменить в выражении слева все внутренние подвыражения вида "любое выражение" в степени "любое выражение" на ноль. Для работы с шаблонами существует еще одна полезная функция, которая называется MatchQ. Она позволяет сравнить любое выражение на соответствие с шаблоном. Вот как она работает:
MatchQ[a^b, _^_] (* => True *)
MatchQ[f[x[y[z], g], h], _] (* => True *)
MatchQ[g[f], f[_]] (* => False *)То есть первым аргументом идет само выражение, а вторым шаблон, который "накладывают" сверху, чтобы понять соответствуют они друг-другу или нет. И получается, теперь мы можем понять как примерно сработала линеаризация в предыдущем примере. Ядро математики начиная сверху вниз спускается к самым дальним уровням и оттуда постепенно поднимается вверх. Затем на каждом узле происходит сравнение с шаблоном при помощи MatchQ. Если возвращается True, то текущий узел заменяется по указанному правилу.
Шаблоны могут быть более сложными. Их можно встроить в любое место выражения. Например вот так можно проверить, что математическая формула соответствует уравнению физического маятника:
MatchQ[x''[t] + w * x[t] == 0, _''[_] + _ * _[_] == 0]
(* True *)Есть еще множество видов шаблонов. По сути шаблоны можно назвать внутренним подъязыком для Wolfram Language. Например, вот так можно проверить, что выражение соответствует списку из двух целых элементов:
MatchQ[{1, 2}, {_Integer, _Integer}]
(* True *)А вот так проверить, что массив представляет собой чередующееся значения комплексных и рациональных чисел:
MatchQ[{1/2, I, 1/3, I/2}, {PatternSequence[_Rational, _Complex]..}]А еще шаблоны можно именовать вот так:
MatchQ[{1, 2, 1}, {x_, y_, x_}]
(* True *)
MatchQ[{1, 2, 3}, {x_, y_, x_}]
(* False так как указав имя говорим, что первый и третий элемент
хоть и могут иметь любое значнеие, но должны совпадать *)В принципе перечисленного достаточно, чтобы перейти к следующему шагу.
Переход к функциям
До сих пор мы игрались именно с тем, о чем я сказал в самом начале - то есть простенькие задачки из математического анализа. Выше я заявил, что символьное программирование - это не только решение дифур и аналитические интегралы. Но пока ничего другого уважаемые читатели так и не увидели! Что ж.. у нас на данный момент есть:
6 типов атомов
Синтаксические деревья состоящие из них и только из них
Правила и замены
Шаблоны
Причем стоит учесть, что правила, замены и шаблоны - это тоже выражения состоящие из атомов. Как из всего этого создать функцию? Давайте рассмотрим на примере сортировки пузырьком. Создаем выражение из символа и чисел:
arr = {1, 0, 1, 0, 0, 1, 0}Создаем правило сортировки:
sortRule = {first___, 1, 0, rest___} :> {first, 0, 1, rest}И применим это правило один раз к массиву:
arr /. sortRule
(* {0, 1, 1, 0, 0, 1, 0} *)Одна пара поменялась местами! А что если применить правило замены еще несколько раз:
arr /. sortRule /. sortRule /. sortRule /. sortRule /. sortRule /.
sortRule /. sortRule /. sortRule
(* {0, 0, 0, 0, 1, 1, 1} *)Тогда мы получим полностью отсортированный список! Как это можно сделать для любых чисел? Нам понадобится повторяющаяся замена ReplaceRepeated ( //. ) и условие применения Condition ( /; ) и вот код стандартной пузырьковой сортировки:
bubbleSortRule = {f___, x_, y_, r___} :> {f, y, x, r} /; y < xВот как этот код будет работать:
{1, 2, 3, 4, 3, 2, 1} //. bubbleSortRule
(* {1, 1, 2, 2, 3, 3, 4} *)В общем-то все готово. Осталось только сказать ядру WL, чтобы он применял это правило замены всякий раз к любому выражению, которое нужно отсортировать. Мы можем сделать это при помощи стандартного синтаксиса языка Wolfram:
bubbleSort[arr_List] := arr //. bubbleSortRule
bubbleSort[{1, 2, 3, 4, 3, 2, 1}]
(* {1, 1, 2, 2, 3, 3, 4} *)Выше мы создали функцию. Но как мы это сделали? Слева от знака := находится шаблон!! А справа находится выражение! Подождите, ведь это же слишком похоже на то, что создание функций - это просто процесс добавление в ядро пар шаблон + правило замены! Точно так же, как у нас выше было сделано для bubbleSortRules! Просто там мы вызывали замену самостоятельно, а здесь за нас это делает ядро! Как я могу это доказать? Очень просто! Я знаю где находится хранилище с определениями функций. Это хранилища совершенно неожиданно тоже является символом и называется DownValues:
DownValues[bubbleSort]
(* {HoldPattern[bubbleSort[arr_List]] :> (arr //. bubbleSortRule)} *)Да мы это только что обсуждали! Это такое же шаблон и правило замены. Используются чуть-чуть другие функции, но их назначение тоже самое. Давайте возьмем напрямую этот шаблон и попробуем понять чему он соответствует:
MatchQ[
myFunc[{1, 2, 3}],
HoldPattern[myFunc[arr_List]]
]
(* True *)То есть ядро математики сравнивает ЛЮБОЙ пользовательский ввод с шаблоном, который обернут в HoldPattern и если результат сравнения True, то пользовательский ввод заменяется по указанному правилу! Т.е. ядро в автоматическом режиме делает вот так:
myFunc[{1, 2, 3}] /. HoldPattern[myFunc[arr_List]] :> Total[arr]
(* 6 *)Это полностью равнозначно созданию и вызову вот такой функции:
myFunc[arr_List] := Total[arr]
myFunc[{1, 2, 3}]
(* 6 *)Ну и причем здесь символьное программирование?!
Наконец мы дошли до этой секции. Еще раз резюмируя все то, что я написал выше. Символьное программирование - манипуляции с символьными выражениями, где переменные или символы могут не иметь конкретных значений, а использоваться как есть. Это очень полезно в задачах математического анализа и по моим представлениям появилось именно с целью их решения.
Но как реализовано символьное программирование конкретно в WL? При помощи древовидных выражений состоящих из атомом, шаблонов и правил замен! Но что мы знаем теперь? Внутреннее хранилище определений ВСЕХ функций языка это точно такие же шаблоны и правила замены, которые работают с символьными выражениями! Абсолютно весь язык построен на такой модели выполнения. Там конечно же есть дополнительные тонкости, но основа языка заключается именно в последовательном применении правил замены к символьным древовидным выражениям.
Преимущество Wolfram Language и Mathematica в том, что такая концепция вычисления выражений в стенах WRI развивается уже долее 35 лет. Движок для работы с выражениями за это время стал очень мощным и производительным. Настолько, что скорость выполнения аналогичных функций вполне сравнима с другими популярными языками программирования, вот только выполнение абсолютно всех программ в нем идет совершенно неоптимальным способом! Да, разбор синтаксического дерева не такая уж редкая вещь, но бесконечно применение правил замен - это довольно необычная модель, согласитесь?
Не только DownValues
Внутреннее хранилище функций языка имеет и другие разделы. Вот самые основные из них:
OwnValues- переменныеx, y, z, ..DownValues- функцииf[x, y, ..]UpValues- переопределенияg[f[..]]SubValues- многоуровневые функцииf[x][y]..
4 хранилища выше покрывают все возможные виды конструкций, которые можно составить из символов и квадратных скобочек. Есть другие менее важные внутренние разделы, но нам они пока что не интересны. Давайте лучше рассмотрим как происходит выполнение кода.
По ветвям дерева
Когда ядро Wolfram Language, т.е. интерпретатор языка встречает любое выражение на своем пути, то тут же начинает его вычислять. Как это происходит? Пусть мы открыли консоль ядра и написали вот такую строчку:
f[x_, y_] := x^2 - yСначала выполняется первая строка - создается определение и в списке DownValues появляется вот такое правило:
DownValues[f]
(* {HoldPattern[f[x_, y_]] :> x ^ 2 - y} *)Затем вызываем эту функцию:
f[2, 3]Эта строчка в неизменном виде (в данном случае) попадает в ядро. Далее ядро при помощи внутреннего матчера быстро пробегается по всем сохраненным шаблонам и находит, что:
MatchQ[f[2, 3], f[x_, y_]] === TrueТогда в текущем положении стека вызова происходит замена:
f[2, 3] :> 2 ^ 2 - 3Полученное выражение приводится вот в такую полную форму:
Plus[Power[2, 2], -3]Нам удобнее посмотреть на него в древовидной форме:

Затем интерпретатор начинается спускаться от корня к ветвям этой древовидной структуры до самого конца. Последний уровень - это два целых числа 2 и 2. Когда интерпретатор достигнет их он поймет, что это атомы. Причем эти атомы являются числами, а значит не хранят определений. С этого момента ядро начинает подниматься наверх. Сначала оно встречает на своем пути вот такую функцию:
Power[2, 2]Точно так же отправляется в DownValues и ищет определение и с помощью правила заменяет Power[2, 2] :> 4. Тогда древовидная структура становится вот такой:

Поднимаемся еще на уровень вверх, ищем определение Plus и выполняем замену выражения Plus[4, -3] :> 1. В результате у нас остается только один атом без определения, который и возвращается.
Если во время движения по синтаксическому дереву на каком-то узле встречается символ, у которого нет определений, то та часть дерева, которая была под ним и выполнилась остается неизменной. Это же выражение в неизменном виде передается интерпретатору дальше. И это же выражение как полноценный объект используется в дальнейших вычислениях. Допустим я пытаюсь выполнить вот такой код:
1 + g[2, 3 + 4, 5 - 6^7]В древовидной форме код выше выглядит вот так:
TreeForm[Hold[1 + g[2, 3 + 4, 5 - 6^7]]]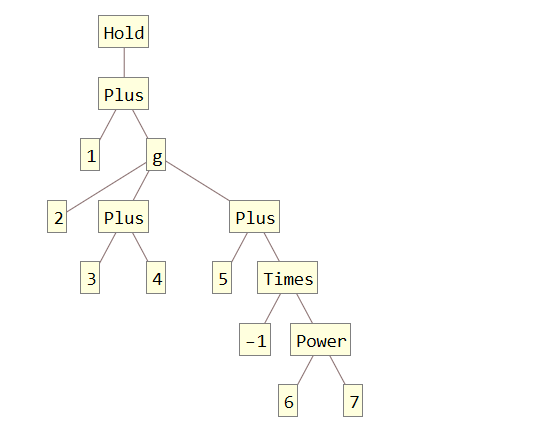
Мы знаем, что у g нет определений, значит в результате выполнения это небольшое выражение должно остаться. И вот как выглядит результат:
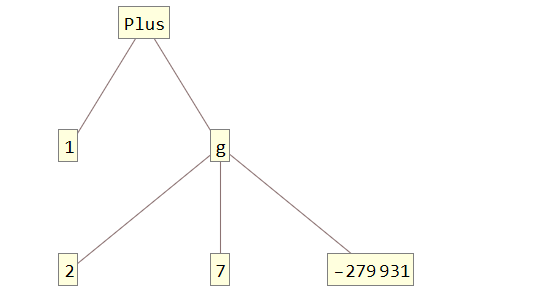
Т.е. узел с g не был ни на что заменен. А функции, которые являются заголовком для g ничего не смогли сделать, так как у них нет определений на этот случай. В итоге одно символьное выражение преобразовалось в другое. А все преобразования производились внутри ядра при помощи правил замен.
В чем же магия этого подхода?
Вся уникальности работы с кодом как с синтаксическим деревом заключается в полном доступе к этому самому коду. Если я знаю где хранятся определения, я могу их извлекать, анализировать и изменять прямо на ходу. А так же я могу эти же определения пересылать по интернету, сохранять в файл, экспортировать в языки разметки или преобразовывать в другие языки программирования!
Но конечно же всегда лучше рассматривать конкретные примеры. Как при помощи символьного программирования добавить логирование для любой функции, но при этом не затронуть все остальные. Задача очень проста: у меня есть сложный код и там вызывается много функций, но при этом он просто выполняется и возвращает результат. Я хочу сделать так, чтобы во время вызова одной конкретной функции кусок кода внутри этой функции напечатал дополнительный лог. Вот моя функция:
ClearAll[numberInterpreter]
numberInterpreter = Interpreter["Number", NumberPoint -> ","];
ClearAll[currencyToAssoc]
currencyToAssoc[
XMLElement[
"Valute", {"ID" -> id_}, {XMLElement["NumCode", _, {numCode_}],
XMLElement["CharCode", _, {charCode_}],
XMLElement["Nominal", _, {nominal_}],
XMLElement["Name", _, {name_}],
XMLElement["Value", _, {value_}], ___}]] := <|"CurrencyId" -> id,
"CurrencyCode" -> numberInterpreter[numCode],
"CurrencyIso" -> charCode, "Nominal" -> numberInterpreter[nominal],
"Name" -> name, "Rate" -> numberInterpreter[value]|>
ClearAll[currencyRates]
currencyRates[] :=
Module[{request, response, bodyByteArray, body, xml, result},
request = HTTPRequest["http://www.cbr.ru/scripts/XML_daily.asp"];
response = URLRead[request];
bodyByteArray = response["BodyByteArray"];
body = ByteArrayToString[bodyByteArray, "WindowsCyrillic"];
xml = ImportString[body, "XML"];
result =
Map[currencyToAssoc]@
FirstCase[xml, XMLElement["ValCurs", _, rates : {__} ..] :> rates];
Return[result]]Название функции говорит самом за себя - она просто получает курсы валют с сайта центрального банка. Вот как ее можно вызвать:
currencyRates[]В результате мы получим вот такой список курсов валют:

Но что будет если у меня есть такая функция, я не могу ее менять, но при этом хочу вставить в середину ее кода логирование? Например печатать HTTPRequest везде где он используется. Вот как это я могу сделать:
DownValues[newCurrencyRates] = DownValues[currencyRates] /. {
currencyRates :> newCurrencyRates,
HoldPattern[HTTPRequest[data___]] :> Echo[HTTPRequest[data], "Request"]
}И теперь вызовем функцию повторно:
Dataset[newCurrencyRates[]]
Теперь вместе с результатом напечатался и объект с HTTP-запросом, который мы отправили. Т.е. мы только что внедрили дополнительное действие непосредственно в код сторонней функции. Пусть конкретно эта демонстрация не выглядит впечатляющей, но сами возможности изменить любой код в любой момент разобрав синтаксическое дерево очень впечатляют.
Мета-программирование
В популярных языках программирования очень часто для пользователя есть доступ к внутренней структуре кода через рефлексию. В WL никакой рефлексии по сути нет, так как нет каких-то определенных функций для взаимодействия со структурой языка. Ведь нет никакой разницы между данными и кодом. С кодом можно работать точно также как и с данными. И один из примеров применения этой концепции - это простая кодогенерация. Имея набор данных можно естественным образом без вызова специальных функций языка превратить данные в определения функций. Причем сделать это по сути можно любым подходящим способом. Как через создание DownValues напрямую, так и с помощью превращения строки в выражение, так и создавая определения классическим способом. Пусть у нас есть строка с описанием методов и параметров:
apiSchema = "{
\"paths\": {
\"method1\": {\"x\": \"number\", \"s\": \"string\"},
\"method2\": {\"d\": \"timestamp\"}
}
}"Мы можем ее импортировать:
paths = ImportString[apiSchema, "RawJSON"]["paths"]
(* <|"method1" -> <|"x" -> "number", "s" -> "string"|>,
"method2" -> <|"d" -> "timestamp"|>|> *)Теперь создаем функцию-генератор. Т.е. ту функцию, которая из набора данных конструирует другое определение:
makeMyApiFunc[methodName_String, paramsData_Association] :=
With[{method = ToExpression[methodName],
params =
KeyValueMap[
Pattern[#1, Blank[#2]] /. {number -> Real,
timestamp -> DateObject, string -> String} &] @
Association @
KeyValueMap[ToExpression[#1] -> ToExpression[#2] &] @
paramsData
},
Evaluate[method @@ params] = apiFunc[methodName, paramsData]
]Применим эту функцию к набору данных:
KeyValueMap[makeMyApiFunc, paths]После чего в текущей сессии будет создано определение:
?method1
Выводы
Вместо выводов краткая констатация ответов на вопросы из самого начала.
Язык Wolfram действительно реализует символьное программирование, но большинство считает, что это относится только к алгебраическим выражениям и аналитическим задачам.
Символьное программирование изначально зародилось как инструмент для аналитического решения математических задач. В том числе сам язык Wolfram появился благодаря этому. Поэтому "по старой памяти" многие люди, которых я знаю лично символьным программированием называют только подкласс задач связанных с математическим анализом
Но на самом деле весь язык Wolfram построен всего лишь из трех основных блоков: символьные выражения, шаблоны и правила замены. И именно эти три возможности делают язык таким, какой он есть - т.е. полностью символьным языком.
Исторический экскурс
Фундаментальная работа Стивена Хьюговича Вольфрама A New Kind of Science посвящена клеточным автоматам. Именно клеточные автоматы являются прототипом той самой модели выполнения кода, о которой я писал выше. Клеточный автомат - например игра жизнь - по сути во время своей работы заменяет один набор байт на другой. Все этим шаблоны и правила замены работают точно так же, только набор байт здесь отображается в виде имени символа или шаблона, а правила применяются точно так же.
Лично я как большой поклонник WL считаю, что вся эта идея, реализация языка и сам дизайн языка программирования Wolfram абсолютно гениален. Я отлично знаю про все его проблемы и недостатки, но все равно считаю, что это язык программирования с лучшим дизайном, который я когда либо видел.
Всем спасибо за внимание!












