Introduction
Openjob is a new distributed task scheduling framework based on Akka architecture. Supports multiple cronjob, delay task, workflow, lightweight distributed computing, unlimited horizontal scaling, with high scalability and fault tolerance. Also has complete management, powerful alarm monitoring, and support multiple languages
High reliability
Distributed with stateless design, using the Master/Worker architecture, supports multiple databases (MySQL/PostgreSQL/Oracle)
High performance
System uses a consistency sharding algorithm, lock-free design, task scheduling is accurate down to the second, supporting lightweight distributed computing and unlimited horizontal scaling
Cronjob
Supports distributed cronjob, fixed rate tasks, high-performance second tasks, and onetime tasks
Distributed computing
Supports multiple distributed programming models such as standalone, broadcast, Map, MapReduce, and sharding, easy to complete distributed computing for big data
Delay task
High performance delay task based on Redis , support multi-level storage, and provides rich statistics and reports
Workflow
Supports workflow scheduling engine, visual DAG design, and easy to complete complex task scheduling
Permission management
User management, supports menu, button, and data permission settings, flexible management of user permissions
Alarm monitoring
Overall monitoring metrics, rich and alarm in time, easy to locate and resolve online problem
Multiple languages
Support multiple languages such as Java, Go, PHP, and Python, as well as build with frameworks such as Spring Boot, Gin, and Swoft
If you are looking for a high-performance distributed task scheduling framework that supports cronjob, delay task, lightweight computing, workflow, and supports multiple programming languages, then Openjob is definitely the way to go.
Released
Openjob 1.0.7 newly supports H2/TiDB database and adds second delay task, fixed rate task, broadcast task, sharding task, and Map Reduce lightweight computing.
Second Delay
Second delay support scheduling at interval of 1 to 60 seconds. After each task execution is completed, scheduling will be triggered again at second intervals.
High reliability: Second delay have high reliability characteristics. If a machine goes down, it can be re-run on another machine.
Rich task types: Second delay belong to the cron type and can be applied to all task types and execution types.
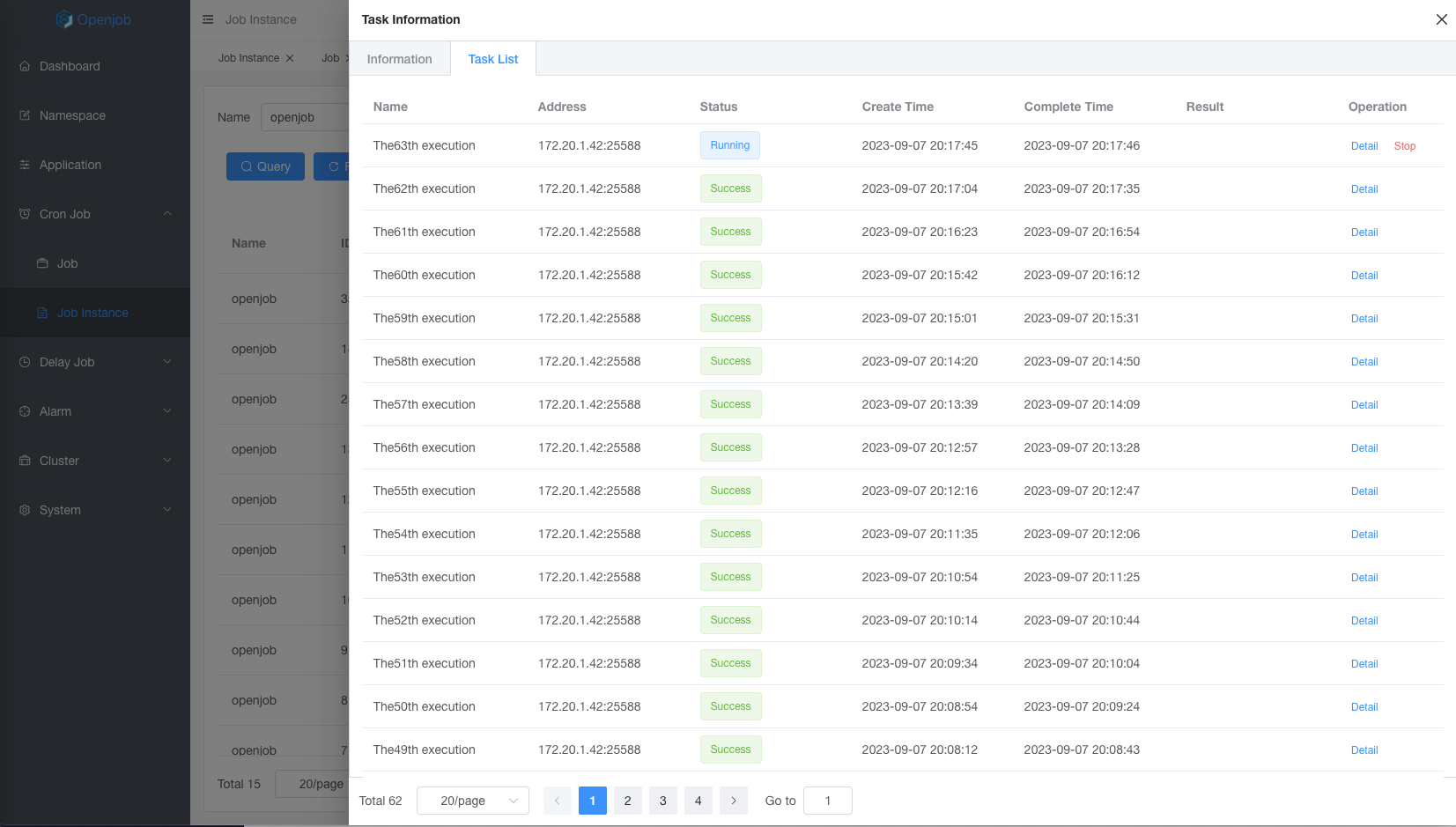
Fixed Rate
Crontab must be divisible by 60, if task executed every 50 minutes, Crontab cannot support it.

Map Reduce
MapReduce is a lightweight distributed batch task. Implemented by the MapProcessor or MapReduceProcessor. Compared with big data batch task (such as Hadoop, Spark, etc.), MapReduce does not need to import data into the big data platform, and has no additional storage and computing costs. It can realize second data processing and the advantages of low cost, fast speed and programming.
Example
Define executor by annotation as follows:
/**
* @author stelin swoft@qq.com
* @since 1.0.7
*/
@Component("mapReduceTestProcessor")
public class MapReduceTestProcessor implements MapReduceProcessor {
private static final Logger logger = LoggerFactory.getLogger("openjob");
private static final String TWO_NAME = "TASK_TWO";
private static final String THREE_NAME = "TASK_THREE";
@Override
public ProcessResult process(JobContext context) {
if (context.isRoot()) {
List<MapChildTaskTest> tasks = new ArrayList<>();
for (int i = 1; i < 5; i++) {
tasks.add(new MapChildTaskTest(i));
}
logger.info("Map Reduce root task mapList={}", tasks);
return this.map(tasks, TWO_NAME);
}
if (context.isTask(TWO_NAME)) {
MapChildTaskTest task = (MapChildTaskTest) context.getTask();
List<MapChildTaskTest> tasks = new ArrayList<>();
for (int i = 1; i < task.getId()*2; i++) {
tasks.add(new MapChildTaskTest(i));
}
logger.info("Map Reduce task two mapList={}", tasks);
return this.map(tasks, THREE_NAME);
}
if (context.isTask(THREE_NAME)) {
MapChildTaskTest task = (MapChildTaskTest) context.getTask();
logger.info("Map Reduce task three mapTask={}", task);
return new ProcessResult(true, String.valueOf(task.getId() * 2));
}
return ProcessResult.success();
}
@Override
public ProcessResult reduce(JobContext jobContext) {
List<String> resultList = jobContext.getTaskResultList().stream().map(TaskResult::getResult)
.collect(Collectors.toList());
logger.info("Map Reduce resultList={}", resultList);
return ProcessResult.success();
}
@Data
@AllArgsConstructor
@NoArgsConstructor
public static class MapChildTaskTest {
private Integer id;
}
}
Sharding
Sharding model includes static sharding and dynamic sharding:
Static sharding: The main scenario is to process a fixed number of sharding. For example, there are 256 databases in sub-databases, which requires many worker to be processed in a distributed.
Dynamic sharding: The main scenario is distributed processing of unknown data. For example, a large table is constantly changing and requires distributed batch running.
Feature
Compatible with elastic-job’s static sharding.
Supports languages: Java, PHP, Python, Shell, and Go.
High availability: When the worker that executes a sharding task becomes abnormal, it will be dynamically assigned to other normal worker to execute the task.
Flow control: You can set the number of concurrent subtasks for a single worker. For example, if there are 100 sharding and a total of 3 worker, up to 5 sharding can be controlled to execute concurrently, and the others are waiting in the queue.
Retry on failure: Automatically retry when subtask execution fails.
Example
Define executor by annotation as follows:
/**
* @author stelin swoft@qq.com
* @since 1.0.7
*/
@Component
public class ShardingAnnotationProcessor {
private static final Logger logger = LoggerFactory.getLogger("openjob");
@Openjob("annotationShardingProcessor")
public ProcessResult shardingProcessor(JobContext jobContext) {
logger.info("Sharding annotation processor execute success! shardingId={} shardingNum={} shardingParams={}",
jobContext.getShardingId(), jobContext.getShardingNum(), jobContext.getShardingParam());
logger.info("jobContext={}", jobContext);
return ProcessResult.success();
}
}
Broadcast
Broadcast task instance will be broadcast to all workers to the application for execution. Task will be completed when all workers have completed execution. If any worker execute fail, the task will fail.
Application scenarios
Batch operation
Broadcast to all workers to run a script.
Broadcast to all workers to cleaning data regularly.
Dynamically start a service on each worker
Data aggregation
Initialize using JavaProcessor->preProcess
When each worker executes the process, it returns the result according to the business.
Execute postProcess to obtain the execution results of all workers.
Feature
There are many types of broadcast tasks, such as script or Java Processor. If Java processor, it can supports preProcess and postProcess advanced features.
preProcess will be executed before each worker execute process, and will only be executed once.
process is the actual task execution.
postProcess will be executed once after the process execution on each worker is completed and successfully executed, and the results can be returned as data transmission.
Example
Define executor by annotation as follows:
/**
* @author stelin swoft@qq.com
* @since 1.0.7
*/
@Component("broadcastPostProcessor")
public class BroadcastProcessor implements JavaProcessor {
private static final Logger logger = LoggerFactory.getLogger("openjob");
@Override
public void preProcess(JobContext context) {
logger.info("Broadcast pre process!");
}
@Override
public ProcessResult process(JobContext context) throws Exception {
logger.info("Broadcast process!");
return new ProcessResult(true, "{\"data\":\"result data\"}");
}
@Override
public ProcessResult postProcess(JobContext context) {
logger.info("Broadcast post process taskList={}", context.getTaskResultList());
System.out.println(context.getTaskResultList());
return ProcessResult.success();
}
}
More
Official website: https://openjob.io
Live demo: https://demo.openjob.io
username: openjob
password: openjob.io












