Всем привет. Я – айтишник «за 30», и я люблю английский язык. Так получилось, что на протяжении многих лет английский никак не хотел полюбить меня. Перед вами живой пример человека с «плохой памятью», «неспособностью к языкам», богатейшим опытом неудачного изучения английского как на курсах, так и самостоятельно, упущенными из-за незнания языка шансами и возникшими на этой почве комплексами. Все, что можно было сделать в изучении иностранного языка плохо, я попытался сделать еще хуже. Не смотря на все это, перед вами история с хэппи эндом, которая, верю, поможет кому-то избежать глупых ошибок, сэкономить время, избавится от иллюзий и предрассудков по поводу изучения нового языка с около нулевого уровня.

Yury Kashnitsky @yorko
Principal Machine Learning Scientist
PyTorch — ваш новый фреймворк глубокого обучения
22 min

PyTorch — современная библиотека глубокого обучения, развивающаяся под крылом Facebook. Она не похожа на другие популярные библиотеки, такие как Caffe, Theano и TensorFlow. Она позволяет исследователям воплощать в жизнь свои самые смелые фантазии, а инженерам с лёгкостью эти фантазии имплементировать.
Данная статья представляет собой лаконичное введение в PyTorch и предназначена для быстрого ознакомления с библиотекой и формирования понимания её основных особенностей и её местоположения среди остальных библиотек глубокого обучения.
Автоэнкодеры в Keras, Часть 1: Введение
11 min
Tutorial
Содержание
- Часть 1: Введение
- Часть 2: Manifold learning и скрытые (latent) переменные
- Часть 3: Вариационные автоэнкодеры (VAE)
- Часть 4: Conditional VAE
- Часть 5: GAN (Generative Adversarial Networks) и tensorflow
- Часть 6: VAE + GAN
Во время погружения в Deep Learning зацепила меня тема автоэнкодеров, особенно с точки зрения генерации новых объектов. Стремясь улучшить качество генерации, читал различные блоги и литературу на тему генеративных подходов. В результате набравшийся опыт решил облечь в небольшую серию статей, в которой постарался кратко и с примерами описать все те проблемные места с которыми сталкивался сам, заодно вводя в синтаксис Keras.
Автоэнкодеры
Автоэнкодеры — это нейронные сети прямого распространения, которые восстанавливают входной сигнал на выходе. Внутри у них имеется скрытый слой, который представляет собой код, описывающий модель. Автоэнкодеры конструируются таким образом, чтобы не иметь возможность точно скопировать вход на выходе. Обычно их ограничивают в размерности кода (он меньше, чем размерность сигнала) или штрафуют за активации в коде. Входной сигнал восстанавливается с ошибками из-за потерь при кодировании, но, чтобы их минимизировать, сеть вынуждена учиться отбирать наиболее важные признаки.
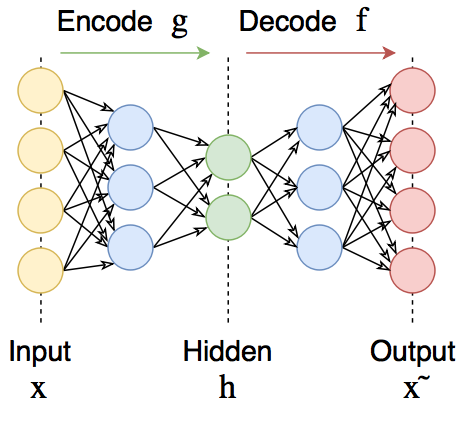
Кому интересно, добро пожаловать под кат
Четыре способа обмануть нейросеть глубокого обучения
6 min
Tutorial
Translation

Нейросети используются уже довольно широко. Чат-боты, распознавание изображений, преобразование речи в текст и автоматические переводы с одного языка на другой — вот лишь некоторые сферы применения глубокого обучения, которое активно вытесняет другие подходы. И причина в основном в более широких возможностях обобщения при обработке больших объёмов данных.
Бесплатная GPU Tesla K80 для ваших экспериментов с нейросетями
6 min

Около месяца назад Google сервис Colaboratory, предоставляющий доступ к Jupyter ноутбукам, включил возможность бесплатно использовать GPU Tesla K80 с 13 Гб видеопамяти на борту. Если до сих пор единственным препятствием для погружения в мир нейросетей могло быть отсутствие доступа к GPU, теперь Вы можете смело сказать, “Держись Deep Learning, я иду!”.
Я попробовал использовать Colaboratory для работы над kaggle задачами. Мне больше всего не хватало возможности удобно сохранять натренированные tensorflow модели и использовать tensorboard. В данном посте, я хочу поделиться опытом и рассказать, как эти возможности добавить в colab. А напоследок покажу, как можно получить доступ к контейнеру по ssh и пользоваться привычными удобными инструментами bash, screen, rsync.
Краткий курс машинного обучения или как создать нейронную сеть для решения скоринг задачи
28 min
Tutorial
Мы часто слышим такие словесные конструкции, как «машинное обучение», «нейронные сети». Эти выражения уже плотно вошли в общественное сознание и чаще всего ассоциируются с распознаванием образов и речи, с генерацией человекоподобного текста. На самом деле алгоритмы машинного обучения могут решать множество различных типов задач, в том числе помогать малому бизнесу, интернет-изданию, да чему угодно. В этой статье я расскажу как создать нейросеть, которая способна решить реальную бизнес-задачу по созданию скоринговой модели. Мы рассмотрим все этапы: от подготовки данных до создания модели и оценки ее качества.
Если тебе интересно машинное обучение, то приглашаю в «Мишин Лернинг» — мой субъективный телеграм-канал об искусстве глубокого обучения, нейронных сетях и новостях из мира искусственного интеллекта.
Вопросы, которые разобраны в статье:
• Как собрать и подготовить данные для построения модели?
• Что такое нейронная сеть и как она устроена?
• Как написать свою нейронную сеть с нуля?
• Как правильно обучить нейронную сеть на имеющихся данных?
• Как интерпретировать модель и ее результаты?
• Как корректно оценить качество модели?
Feature Engineering, о чём молчат online-курсы
7 min

Sherlock by ThatsWhatSheSayd
Чтобы стать великим сыщиком, Шерлоку Холмсу было достаточно замечать то, чего не видели остальные, в вещах, которые находились у всех на виду. Мне кажется, что этим качеством должен обладать и каждый специалист по машинному обучению. Но тема Feature Engineering’а зачастую изучается в курсах по машинному обучению и анализу данных вскользь. В этом материале я хочу поделиться своим опытом обработки признаков с начинающими датасаентистами. Надеюсь, это поможет им быстрее достичь успеха в решении первых задач. Оговорюсь сразу, что в рамках этой части будут рассмотрены концептуальные методы обработки. Практическую часть по этому материалу совсем скоро опубликует моя коллега Osina_Anya.
Один из популярных источников данных для машинного обучения — логи. Практически в любой строчке лога есть время, а если это web-сервис, то там будут IP и UserAgent. Рассмотрим, какие признаки можно извлечь из этих данных.
Лекции Техносферы. Нейронные сети в машинном обучении
3 min

Представляем вашему вниманию очередную порцию лекций Техносферы. На курсе изучается использование нейросетевых алгоритмов в различных отраслях, а также отрабатываются все изученные методы на практических задачах. Вы познакомитесь как с классическими, так и с недавно предложенными, но уже зарекомендовавшими себя нейросетевыми алгоритмами. Так как курс ориентирован на практику, вы получите опыт реализации классификаторов изображений, системы переноса стиля и генерации изображений при помощи GAN. Вы научитесь реализовать нейронные сети как с нуля, так и на основе библиотеке PyTorch. Узнаете, как сделать своего чат-бота, как обучать нейросеть играть в компьютерную игру и генерировать человеческие лица. Вы также получите опыт чтения научных статей и самостоятельного проведения научного исследования.
AlphaGo Zero совсем на пальцах
12 min
Завтра искусственный интеллект поработит Землю и станет использовать человеков в качестве смешных батареек, поддерживающих функционирование его систем, а сегодня мы запасаемся попкорном и смотрим, с чего он начинает.
19 октября 2017 года команда Deepmind опубликовала в Nature статью, краткая суть которой сводится к тому, что их новая модель AlphaGo Zero не только разгромно обыгрывает прошлые версии сети, но ещё и не требует никакого человеческого участия в процессе тренировки. Естественно, это заявление произвело в AI-коммьюнити эффект разорвавшейся бомбы, и всем тут же стало интересно, за счёт чего удалось добиться такого успеха.
По мотивам материалов, находящихся в открытом доступе, Семён sim0nsays записал отличный стрим:
А для тех, кому проще два раза прочитать, чем один раз увидеть, я сейчас попробую объяснить всё это буквами.
Сразу хочу отметить, что стрим и статья собирались в значительной степени по мотивам дискуссий на closedcircles.com, отсюда и спектр рассмотренных вопросов, и специфическая манера повествования.
Ну, поехали.
19 октября 2017 года команда Deepmind опубликовала в Nature статью, краткая суть которой сводится к тому, что их новая модель AlphaGo Zero не только разгромно обыгрывает прошлые версии сети, но ещё и не требует никакого человеческого участия в процессе тренировки. Естественно, это заявление произвело в AI-коммьюнити эффект разорвавшейся бомбы, и всем тут же стало интересно, за счёт чего удалось добиться такого успеха.
По мотивам материалов, находящихся в открытом доступе, Семён sim0nsays записал отличный стрим:
А для тех, кому проще два раза прочитать, чем один раз увидеть, я сейчас попробую объяснить всё это буквами.
Сразу хочу отметить, что стрим и статья собирались в значительной степени по мотивам дискуссий на closedcircles.com, отсюда и спектр рассмотренных вопросов, и специфическая манера повествования.
Ну, поехали.
Как у нас устроено A/Б-тестирование. Лекция Яндекса
12 min
A/Б-тестирование на сервисах Яндекса проводится постоянно. «Раскатить на такую-то долю аудитории» и посмотреть на реакцию людей — настолько стандартная практика, что ни у кого в команде не возникает вопроса, зачем это нужно. А чтобы не было проблем с самим тестированием, у нас есть специальная инфраструктура для экспериментов. Подробности рассказывают разработчики Сергей Мыц и Данил Валгушев.
Сергей:
— Я попробую упрощенно описать задачу A/Б-тестирования. Есть абстрактная система с пользователями, в нее мы вносим какие-то изменения, и нужно уметь измерять в ней пользу. Пока все просто, но слишком абстрактно. Пример. Есть веб-сервис по сравнению пары фотографий котов. Пользователь должен выбрать наиболее понравившуюся фотографию. При этом он может выбрать не только левый или правый снимок, но и «против всех». Значит, мы подобрали картинки не очень хорошо. Наша задача — обоснованно улучшать сервис, доказывая это цифрами.
Сергей:
— Я попробую упрощенно описать задачу A/Б-тестирования. Есть абстрактная система с пользователями, в нее мы вносим какие-то изменения, и нужно уметь измерять в ней пользу. Пока все просто, но слишком абстрактно. Пример. Есть веб-сервис по сравнению пары фотографий котов. Пользователь должен выбрать наиболее понравившуюся фотографию. При этом он может выбрать не только левый или правый снимок, но и «против всех». Значит, мы подобрали картинки не очень хорошо. Наша задача — обоснованно улучшать сервис, доказывая это цифрами.
Математический детектив: поиск положительных целых решений уравнения
9 min
Translation
«Я экспериментировал с задачами кубического представления в стиле предыдущей работы Эндрю и Ричарда Гая. Численные результаты были потрясающими…» (комментарий на MathOverflow)Вот так ушедший на покой математик Аллан Маклауд наткнулся на это уравнение несколько лет назад. И оно действительно очень интересно. Честно говоря, это одно из лучших диофантовых уравнений, которое я когда-либо видел, но видел я их не очень много.
Я нашёл его, когда оно начало распространяться как выцепляющая в сети нердов картинка-псевдомем, придуманная чьим-то безжалостным умом (Сридхар, это был ты?). Я не понял сразу, что это такое. Картинка выглядела так:
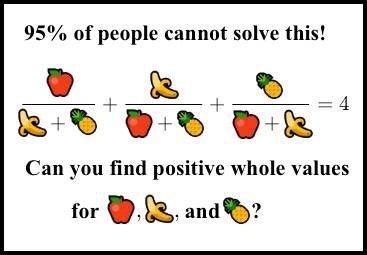
«95% людей не решат эту загадку. Сможете найти положительные целочисленные значения?»
Вы наверно уже видели похожие картинки-мемы. Это всегда чистейший мусор, кликбэйты: «95% выпускников МТИ не решат её!». «Она» — это какая-нибудь глупая или плохо сформулированная задачка, или же тривиальная разминка для мозга.
Но эта картинка совсем другая. Этот мем — умная или злобная шутка. Примерно у 99,999995% людей нет ни малейших шансов её решить, в том числе и у доброй части математиков из ведущих университетов, не занимающихся теорией чисел. Да, она решаема, но при этом по-настоящему сложна. (Кстати, её не придумал Сридхар, точнее, не он полностью. См. историю в этом комментарии).
Вы можете подумать, что если ничего другое не помогает, то можно просто заставить компьютер решать её. Очень просто написать компьютерную программу для поиска решений этого кажущегося простым уравнения. Разумеется, компьютер рано или поздно найдёт их, если они существуют. Большая ошибка. Здесь метод простого перебора компьютером будет бесполезен.
Поиск лучшего места в мире для ветряка
9 min
История о том, как NASA, ESA, Датский Технологический Университет, нейронные сети, деревья решений и прочие хорошие люди помогли найти мне лучший бесплатный гектар на Дальнем Востоке, а также в Африке, Южной Америке и других “так себе” местах.
Про Гауди — разработчика из девятнадцатого века, добившегося всего, чего может добиться разработчик
8 min
Вот что строил испанский архитектор Антонио Гауди:

Его здания описывают как «бионические дома», некоторые говорят о «летящей пластичной материи». За морем восторгов художников и дизайнеров, как мне показалось, упущена некоторая невероятная рационализация и прагматичность. Гауди был в первую очередь отличным разработчиком, математиком и геометром. Но чтобы объяснить это, сначала я покажу другую картинку:

Это два крепления. Первое производится серийно — оно просто в проектировании, просто в изготовлении, дёшево и невероятно уродливо. Второе красивое, и требует на 25% меньше материала для того, чтобы выдержать тот же вес (то есть — куда прочнее). Только его трудно рассчитать, оно будет дороже в серии — и придётся подумать.
Примерно то же самое делал Гауди. Ему пришлось обойтись без математического аппарата и современных материалов. И ещё действовать в рамках строго ограниченного бюджета. Он, фактически, заложил новые принципы всего от фасада до последней дверной ручки, создал шедевры оптимизации — в общем смёл все стереотипы как сухие листья, создал с нуля теорию и воплотил её. В девятнадцатом веке всё то, что он делал, было просто диким. Некоторые даже считали его сумасшедшим.
Его здания описывают как «бионические дома», некоторые говорят о «летящей пластичной материи». За морем восторгов художников и дизайнеров, как мне показалось, упущена некоторая невероятная рационализация и прагматичность. Гауди был в первую очередь отличным разработчиком, математиком и геометром. Но чтобы объяснить это, сначала я покажу другую картинку:
Это два крепления. Первое производится серийно — оно просто в проектировании, просто в изготовлении, дёшево и невероятно уродливо. Второе красивое, и требует на 25% меньше материала для того, чтобы выдержать тот же вес (то есть — куда прочнее). Только его трудно рассчитать, оно будет дороже в серии — и придётся подумать.
Примерно то же самое делал Гауди. Ему пришлось обойтись без математического аппарата и современных материалов. И ещё действовать в рамках строго ограниченного бюджета. Он, фактически, заложил новые принципы всего от фасада до последней дверной ручки, создал шедевры оптимизации — в общем смёл все стереотипы как сухие листья, создал с нуля теорию и воплотил её. В девятнадцатом веке всё то, что он делал, было просто диким. Некоторые даже считали его сумасшедшим.
Лекции от Яндекса для тех, кто хочет провести каникулы с пользой. Дискретный анализ и теория вероятностей
3 min
Tutorial
Для тех, кому одного курса на праздники мало и кто хочет больше, продолжаем нашу серию курсов от Школы анализа данных Яндекса. Сегодня подошла очередь курса «Дискретный анализ и теория вероятностей» – даже более фундаментального, чем предыдущий. Но без него нельзя представить ещё большую часть современной обработки данных.
В рамках курса рассматриваются основные понятия и методы комбинаторного, дискретного и асимптотического анализа, теории вероятностей, статистики и на примере решения классических задач демонстрируется их применение.

Читает курс Андрей Райгородский. Доктор физико-математических наук. Профессор кафедры математической статистики и случайных процессов механико-математического факультета МГУ им. М. В. Ломоносова. Заведующий кафедрой Дискретной математики ФИВТ МФТИ. Профессор и научный руководитель бакалавриата кафедры «Анализ данных» факультета инноваций и высоких технологий МФТИ. Руководитель отдела теоретических и прикладных исследований компании «Яндекс». (Ещё больше можно узнать в статье о нём на Википедии).
В рамках курса рассматриваются основные понятия и методы комбинаторного, дискретного и асимптотического анализа, теории вероятностей, статистики и на примере решения классических задач демонстрируется их применение.
Читает курс Андрей Райгородский. Доктор физико-математических наук. Профессор кафедры математической статистики и случайных процессов механико-математического факультета МГУ им. М. В. Ломоносова. Заведующий кафедрой Дискретной математики ФИВТ МФТИ. Профессор и научный руководитель бакалавриата кафедры «Анализ данных» факультета инноваций и высоких технологий МФТИ. Руководитель отдела теоретических и прикладных исследований компании «Яндекс». (Ещё больше можно узнать в статье о нём на Википедии).
Яндекс открывает технологию машинного обучения CatBoost
6 min
Сегодня Яндекс выложил в open source собственную библиотеку CatBoost, разработанную с учетом многолетнего опыта компании в области машинного обучения. С ее помощью можно эффективно обучать модели на разнородных данных, в том числе таких, которые трудно представить в виде чисел (например, виды облаков или категории товаров). Исходный код, документация, бенчмарки и необходимые инструменты уже опубликованы на GitHub под лицензией Apache 2.0.

CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
CatBoost – это новый метод машинного обучения, основанный на градиентном бустинге. Он внедряется в Яндексе для решения задач ранжирования, предсказания и построения рекомендаций. Более того, он уже применяется в рамках сотрудничества с Европейской организацией по ядерным исследованиям (CERN) и промышленными клиентами Yandex Data Factory. Так чем же CatBoost отличается от других открытых аналогов? Почему бустинг, а не метод нейронных сетей? Как эта технология связана с уже известным Матрикснетом? И причем здесь котики? Сегодня мы ответим на все эти вопросы.
Введение в алгоритм A*
10 min
Translation
При разработке игр нам часто нужно находить пути из одной точки в другую. Мы не просто стремимся найти кратчайшее расстояние, нам также нужно учесть и длительность движения. Передвигайте звёздочку (начальную точку) и крестик (конечную точку), чтобы увидеть кратчайший путь. [Прим. пер.: в статьях этого автора всегда много интерактивных вставок, рекомендую сходить в оригинал статьи.]
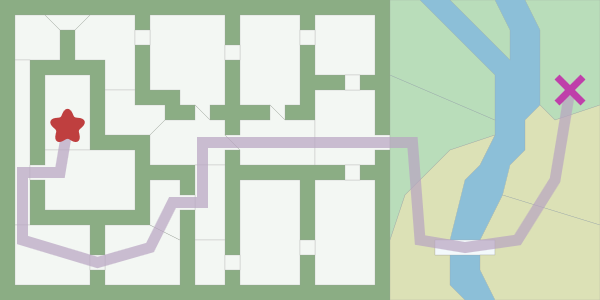
Для поиска этого пути можно использовать алгоритм поиска по графу, который применим, если карта представляет собой граф. A* часто используется в качестве алгоритма поиска по графу. Поиск в ширину — это простейший из алгоритмов поиска по графу, поэтому давайте начнём с него и постепенно перейдём к A*.
Для поиска этого пути можно использовать алгоритм поиска по графу, который применим, если карта представляет собой граф. A* часто используется в качестве алгоритма поиска по графу. Поиск в ширину — это простейший из алгоритмов поиска по графу, поэтому давайте начнём с него и постепенно перейдём к A*.
Типичные распределения вероятности: шпаргалка data scientist-а
11 min
Translation
У data scientist-ов сотни распределений вероятности на любой вкус. С чего начать?
Data science, чем бы она там не была – та ещё штука. От какого-нибудь гуру на ваших сходках или хакатонах можно услышать:«Data scientist разбирается в статистике лучше, чем любой программист». Прикладные математики так мстят за то, что статистика уже не так на слуху, как в золотые 20е. У них даже по этому поводу есть своя несмешная диаграмма Венна. И вот, значит, внезапно вы, программист, оказываетесь совершенно не у дел в беседе о доверительных интервалах, вместо того, чтобы привычно ворчать на аналитиков, которые никогда не слышали о проекте Apache Bikeshed, чтобы распределённо форматировать комментарии. Для такой ситуации, чтобы быть в струе и снова стать душой компании – вам нужен экспресс-курс по статистике. Может, не достаточно глубокий, чтобы вы всё понимали, но вполне достаточный, чтобы так могло показаться на первый взгляд.
{kind=link}
Лекции Техносферы. 1 семестр. Алгоритмы интеллектуальной обработки больших объемов данных
3 min
Tutorial
Продолжаем публиковать материалы наших образовательных проектов. В этот раз предлагаем ознакомиться с лекциями Техносферы по курсу «Алгоритмы интеллектуальной обработки больших объемов данных». Цель курса — изучение студентами как классических, так и современных подходов к решению задач Data Mining, основанных на алгоритмах машинного обучения. Преподаватели курса: Николай Анохин (@anokhinn), Владимир Гулин (@vgulin) и Павел Нестеров (@mephistopheies).
Объемы данных, ежедневно генерируемые сервисами крупной интернет-компании, поистине огромны. Цель динамично развивающейся в последние годы дисциплины Data Mining состоит в разработке подходов, позволяющих эффективно обрабатывать такие данные для извлечения полезной для бизнеса информации. Эта информация может быть использована при создании рекомендательных и поисковых систем, оптимизации рекламных сервисов или при принятии ключевых бизнес-решений.
Объемы данных, ежедневно генерируемые сервисами крупной интернет-компании, поистине огромны. Цель динамично развивающейся в последние годы дисциплины Data Mining состоит в разработке подходов, позволяющих эффективно обрабатывать такие данные для извлечения полезной для бизнеса информации. Эта информация может быть использована при создании рекомендательных и поисковых систем, оптимизации рекламных сервисов или при принятии ключевых бизнес-решений.
Bash-скрипты, часть 6: функции и разработка библиотек
9 min
Translation
Bash-скрипты: начало
Bash-скрипты, часть 2: циклы
Bash-скрипты, часть 3: параметры и ключи командной строки
Bash-скрипты, часть 4: ввод и вывод
Bash-скрипты, часть 5: сигналы, фоновые задачи, управление сценариями
Bash-скрипты, часть 6: функции и разработка библиотек
Bash-скрипты, часть 7: sed и обработка текстов
Bash-скрипты, часть 8: язык обработки данных awk
Bash-скрипты, часть 9: регулярные выражения
Bash-скрипты, часть 10: практические примеры
Bash-скрипты, часть 11: expect и автоматизация интерактивных утилит
Занимаясь разработкой bash-скриптов, вы рано или поздно столкнётесь с тем, что вам периодически приходится использовать одни и те же фрагменты кода. Постоянно набирать их вручную скучно, а копирование и вставка — не наш метод. Как быть? Хорошо бы найти средство, которое позволяет один раз написать блок кода и, когда он понадобится снова, просто сослаться на него в скрипте.

Оболочка bash предоставляет такую возможность, позволяя создавать функции. Функции bash — это именованные блоки кода, которые можно повторно использовать в скриптах.
Работа с ветками SVN
6 min
Прежде чем приступать вообще к использованию веток, и даже если вы и не думаете их использовать, необходимо прочесть Этот Священный Талмуд.
После того как вы прочли статью о ветках в svnbook, вы уже понимаете для чего нужны ветки, как с ними работать и в каких случаях их необходимо использовать. В принципе, после этого, то, что написано под катом вам уже скорее всего не нужно. Но если вам было лень читать, то может текст ниже вас заинтересует, и вы все таки прочтете статью документации. А может, просто поможет вам лучше понять то, что только что прочли в svnbook-е.
После того как вы прочли статью о ветках в svnbook, вы уже понимаете для чего нужны ветки, как с ними работать и в каких случаях их необходимо использовать. В принципе, после этого, то, что написано под катом вам уже скорее всего не нужно. Но если вам было лень читать, то может текст ниже вас заинтересует, и вы все таки прочтете статью документации. А может, просто поможет вам лучше понять то, что только что прочли в svnbook-е.