Привет, хаброчеловек!
В этой статье мы обсудим путь среднестатистического обывателя в Machine Learning, а именно — как стать ML-инженером. Поговорим о специфике области, какие требуются знания и скиллы, что нужно делать и с чего начать.

Data scientist | Academic | Amateur photographer
Привет, хаброчеловек!
В этой статье мы обсудим путь среднестатистического обывателя в Machine Learning, а именно — как стать ML-инженером. Поговорим о специфике области, какие требуются знания и скиллы, что нужно делать и с чего начать.

Попала мне в руки на некоторое время 10-е издание книги Кристофера Негуса «Библия Linux». Поскольку в повседневной деятельности мне приходится работать с системами под управлением различных дистрибутивов, работающих на базе GNU/Linux, столько увесистый труд (масса его 1202 грамм), не мог не вызвать живого интереса. Ну а если, после названия данной книги, взглянуть на ее стоимость, то начинаешь ожидать от нее «откровений».
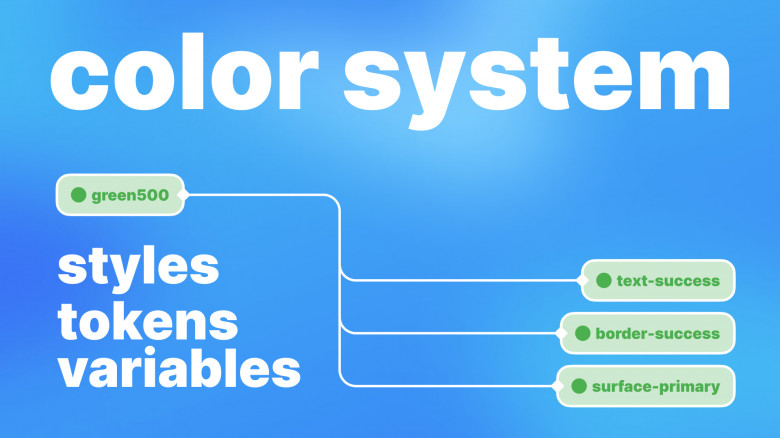
В этой статье я расскажу как упорядочить цвета в макетах и в уже готовом продукте; как перейти от стилей к токенам (variables), а также поделюсь рекомендациями для тех, кто только собирается внедрять стили и переменные для цветов.
Дал ему подборку книг, он приходит месяца через два, и с порога такой сразу:
— Я с друзьями не могу разговаривать.
— Ну да есть такой, недостаточек.
интервью Жака Фреско

В этой статье я кратко расскажу о своих любимых инструментах для Kubernetes, уделяя особое внимание новейшим и малоизвестным, которые, как мне кажется, скоро станут популярными.
В основе этого списка — мой личный опыт, и чтобы избежать предвзятости, я расскажу и об альтернативных инструментах, чтобы вы могли всё сравнить и принять решение, исходя из своих потребностей. Постараюсь дать информацию сжато и привести источники, чтобы при желании вы могли изучить всё самостоятельно. Описывая инструменты для различных задач разработки ПО, я хотел ответить на вопрос: «Как я могу сделать X в Kubernetes?»
> С 10 апреля 2024, 3 месяца спустя,
> данная статья заблокирована РКН на территории РФ,
> но доступна с IP других стран, а также через веб-архив.
На фоне прошлогоднего обострения цензуры в РФ, статьи автора MiraclePTR стали глотком свободы для многих русскоязычных айтишников. Я же хочу приоткрыть дверь к свободной информации чуть шире и пригласить «не‑технарей» («чайников»), желающих поднять личный прокси‑сервер для обхода цензуры, но дезориентированных обилием информации или остановленных непонятной технической ошибкой.
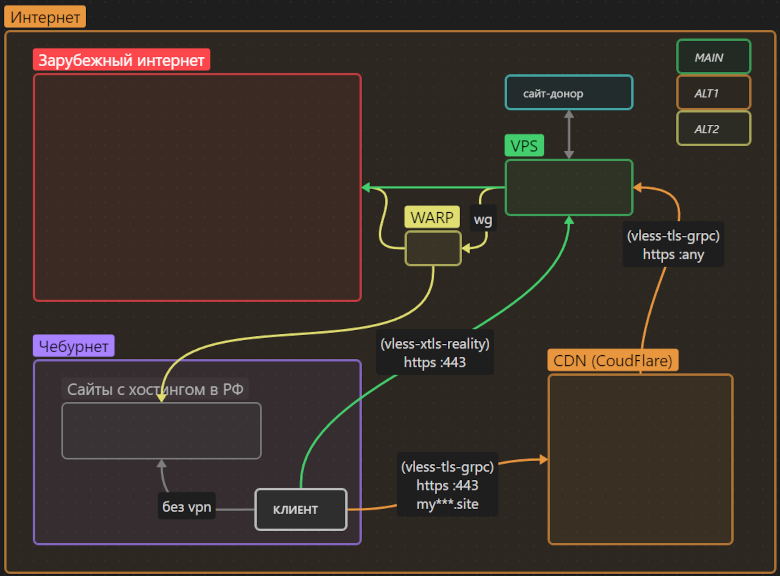
В этой статье я описал универсальное решение, которое обеспечивает прозрачный доступ к международному интернету в обход цензуры, использует передовые технологии маскировки трафика, не зависит от воли одной корпорации и главное — имеет избыточный «запас прочности» от воздействия цензоров.
Статья рассчитана на «чайников», не знакомых с предметной областью. Однако и люди «в теме» могут найти нечто полезное (например, чуть более простую настройку проксирования через CloudFlare без необходимости поднимать nginx на VPS).
Если у вас ещё нет личного прокси для обхода цензуры — это знак.


Сегодня ровно 20 лет, как я начал программировать профессионально. За эти годы я:
• Получил одобрение на петицию по грин‑карте за выдающиеся способности в науке.
• Стал Google Developer Expert.
• Стал IEEE Senior Member.
• Был операционным директором в компании со 100 сотрудниками.
• Написал код, который скачали 135 миллионов раз.
• Выступал перед аудиторией в 2000 человек, дважды.
• Стал самым честным человеком в России по версии НТВ.
Но упустил я гораздо больше и делал всё это слишком долго. Думаю, этот путь можно было бы пройти «на скорость» лет за 5 с теми подходами, принципами и приоритетами, которым я научился. Если вы только начинаете свой путь, этот текст может сэкономить вам 15 лет жизни.

14го декабря в одном из самых авторитетных общенаучных журналов Nature была опубликована статья с, кажется, сенсационным заголовком: «ИИ-модели Google DeepMind превосходят математиков в решении нерешённых проблем». А в блогпосте дочки гугла и вовсе не постеснялся указать, что это — первые находки Больших Языковых Моделей (LLM) в открытых математических проблемах. Неужели правда? Или кликбейт — и это в Nature? А может мы и вправду достигли техносингулярности, где машины двигают прогресс? Что ж, давайте во всём разбираться!
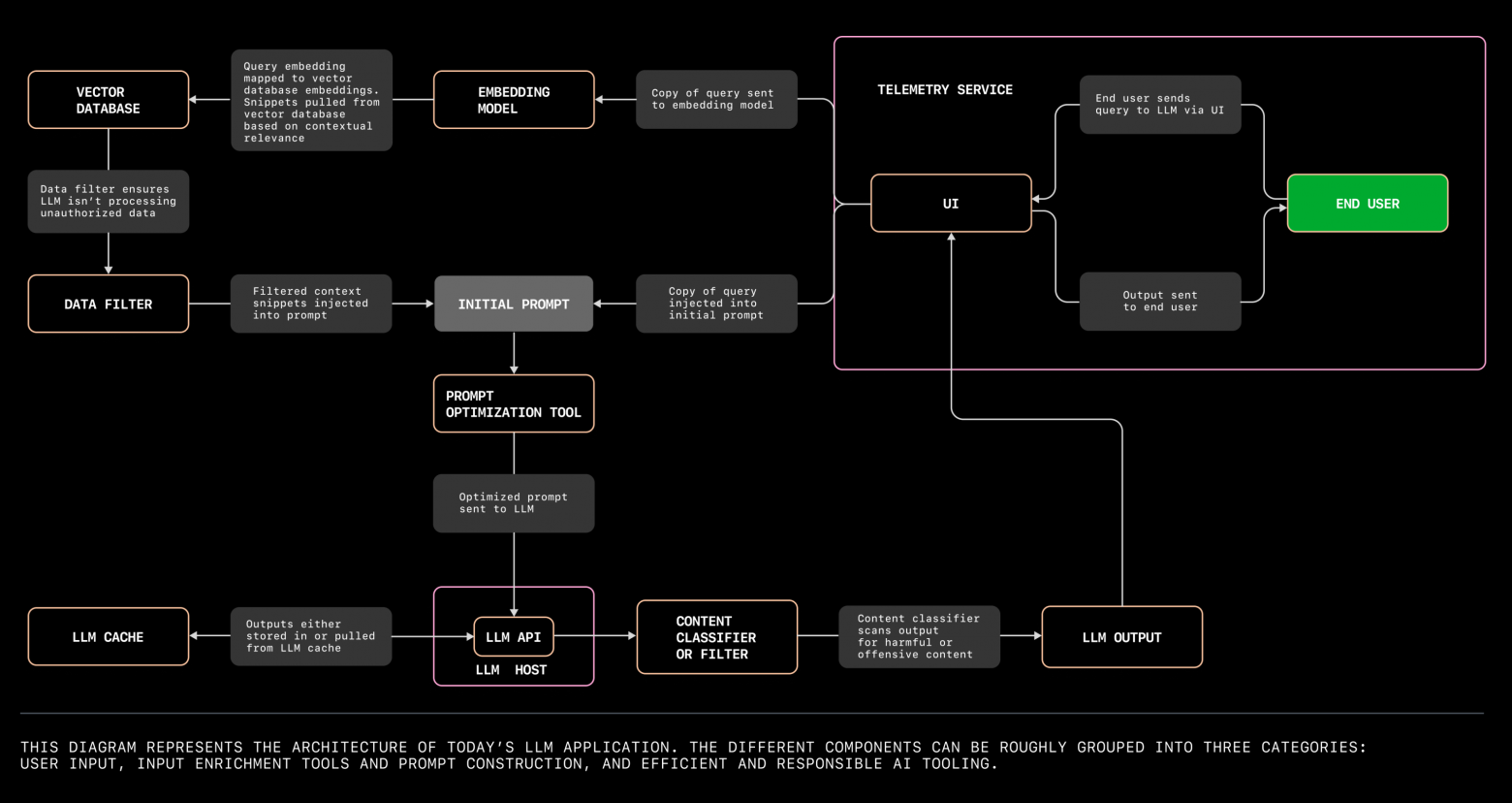
В этом посте мы рассмотрим пять наиболее важных этапов, который нужно пройти при разработке собственного приложения на основе LLM, формирующиеся общепринятые подходе к разработке таких приложений и предметные области, на которые стоит обратить внимание.
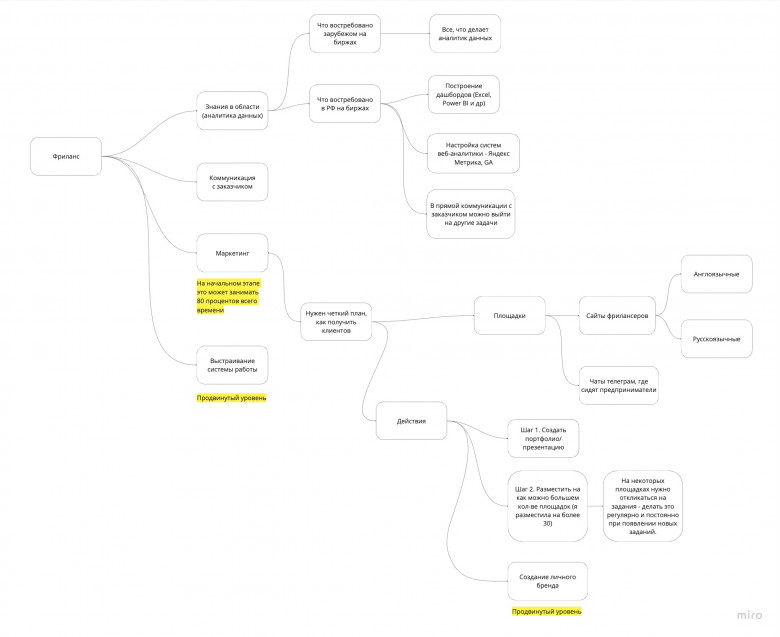
За 7 дней я получила 16 заказов на фрилансе и в этой статье поделюсь своим опытом: как именно мне удалось это сделать, с каких ресурсов пришли заказы.
Статья будет полезна:
• Если вы хотите использовать фриланс для получения первого опыта и положить выполненные фриланс-задачи в портфолио (40% работодателей отмечают, что фриланс - это лучший способ получить первый опыт)
• Если вы хотите серьезно заняться фрилансом и сделать из фриланса "жизненную философию"

Декорирование функций - это, наверное, самая сложная среди базовых и самая простая среди продвинутых фич языка Python. С декораторами, наверное, знакомы все джуны (хотя бы в рамках подготовки к собеседованиям). Однако, крайне мало разработчиков пишут их правильно. Особенно принимая во внимания тенденции последних нескольких лет к аннотированию всего и вся. Даже популярные open-source проекты (если основная часть их кода была написана до 2018 года) вряд ли дадут вам примеры декораторов, отвечающих всем современным требованиям к коду.
Так давайте разбираться!
Материал полностью написан на основе моего опыта по работе над OSS проектами, поэтому в нем вы найдете примеры достаточно сложных кейсов, которые никогда не рассматриваются в других подобных гайдах. В то же время я постарался подвести к ним максимально "мягко", чтобы было понятно даже начинающим питонистам.
В рамках статьи мы разберемся с декорированием функций в Python от простого к самому сложному. Рассмотрим, как их правильно писать и аннотировать, чтобы другие потребители вашего кода не страдали от близкого знакомства с ним. Уверен, что даже если вы чрезвычайно опытный разработчик, вы найдете для себя полезные советы (хотя и можете пропустить солидную часть материала).

Возникла задача проверки нескольких типов пользовательских документов Excel. Проверка должна покрывать такие аспекты как корректность шаблона (наличие ожидаемых страниц, колонок таблиц) и корректность данных (присутствие обязательных значений, корректность значений точки зрения форматов, отсутствие дубликации, итд).
Пользователю нужно возвращать информацию "что не так с файлом": какую проверку не прошел файл и где конкретно в файле проблемные данные.
Эта задача - про качество данных и очень напоминает тестирование. Так почему не использовать фреймворк тестирования pytest, и не написать тесты на каждый проверяемый аспект и для каждого типа файлов? Однако, есть небольшое "но". проверка должна быть реализована в качестве сервиса, чтобы встраиваться в более широкий процесс обработки пользовательских документов.
Давайте посмотрим, как заставить pytest работать внутри сервиса. Это не так тривиально, как может показаться на первый взгляд.

Старые программы покрываются коркой сомнительных фич.
ls просто создаёт список файлов, cat просто выводит содержимое файлов, grep просто фильтрует данные, wc просто подсчитывает слова и так далее. У каждой программы есть несколько опций, меняющих её поведение, но не слишком сильно. Например: wc можно сконфигурировать для подсчёта строк или слов, но не для подсчёта количества абзацев или вхождений какой-то фразы.wc, если с этим уже способна справиться grep?
Scripts/ на Github есть файлы .Rmd, генерирующие показанные ниже графики. Для их работы требуются R, RStudio и пакет rmarkdown.
Однажды на работе возник вопрос — насколько вероятно, что в случайно сгенерированном идентификаторе (отдаваемом пользователю, к примеру) вдруг обнаружится плохое слово. Приблизительная оценка была дана достаточно быстро, а вот точное решение — уже не так тривиально.
Я решил всерьёз выяснить, чему равна эта вероятность в зависимости от длины случайной строки? Можно ли получить явную математическую формулу для ответа? Что, если взять другое слово? Что, если взять другой алфавит?
Обо всём по порядку.

Перевод туториала по фреймворку для построения TUI (текстовых интерфейсов). Кроссплатформенность, возможность вывода в веб, а также олдскульность.

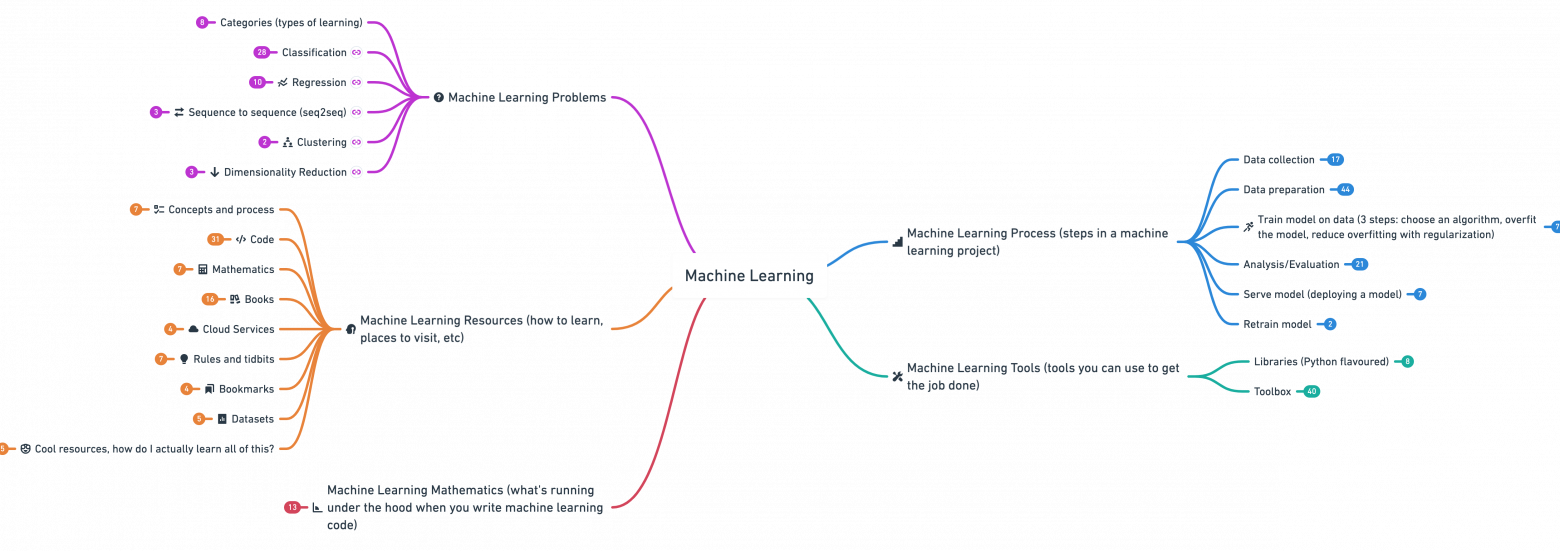
Всем доброго времени суток. Я давно обещала выложить сюда подробный гайд на тему того, как можно изучать Machine Learning самостоятельно, не тратя деньги на платные курсы, и, наконец, выполняю свое обещание. Надеюсь, этот гайд станет подсказкой, которая поможет найти правильное направление новичкам, которые хотят погрузиться в нашу область.

