Предисловие для читателей Хабра — статья о поиске работы на рынке разработки в Украине (который в основном об аутсорсе на иностранных заказчиков), поэтому некоторые вещи могут показаться странными (LinkedIn, собеседования с заказчиками, обязательное требование разговорного английского, обсуждение ЗП в долларах) или нерелевантными для РФ. Тем не менее, статья имела большой успех на локальных ресурсах, и читатели попросили меня перевести её на русский.
Этой статьей я хочу начать цикл рассказов о том, как я на протяжении нескольких месяцев проходил собеседования в примерно 20-и разных компаниях на разные должности. Тут будут мои мысли о рынке труда, процессе найма, советы а так же несколько самых интересных историй. Цикл будет состоять из нескольких частей — HR собеседования, технические собеседования, финальные собеседования. Итак, первая часть.
Немного о себе. Программирую со школьного возраста, за деньги работаю 10 с хвостиком лет. Работал админом, программистом, тимлидом, РМ-ом, линейным менеджером. Выполнял обязанности SRE/DevOps, архитекта, HR, офис-менеджера, эникейщика.
Работал в кровавом энтерпрайзе, в стартапе, в аутсорсе. В основном занимался формошлёпством и крудами, имел дело с Java и бэкендом. За последние несколько лет пересел на фуллстек микс из Java, Ruby/RoR, Python, Node.js.
На собеседованиях я позиционировал себя как Senior и выше разработчика, поэтому все ниженаписанное будет актуально для такого уровня и выше. На других позициях опыт может отличаться.
Всего я прошел примерно 20 собеседований с рекрутерами: половина из которых были из агенств и половина — штатные рекрутеры/HR компаний. Так что, могу сказать что некоторая статистика у меня есть.





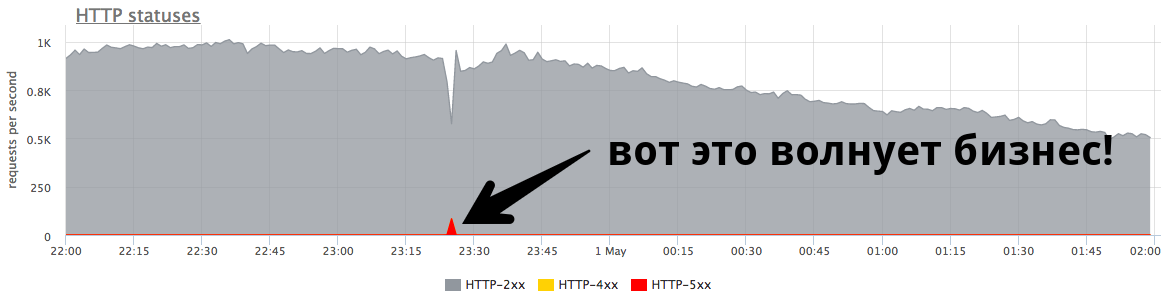
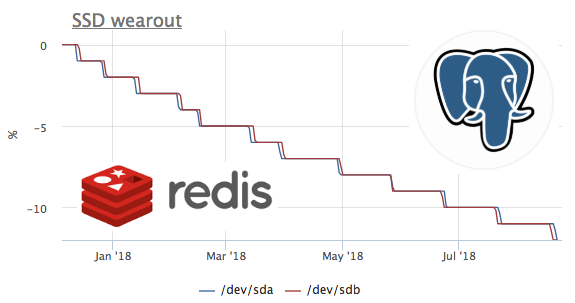
 Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.
Чтобы сделать мониторинг полезным, нам приходится прорабатывать разные сценарии вероятных проблем и проектировать дашборды и триггеры таким образом, чтобы по ним сразу была понятна причина инцидента.