Сообщество Distributed Proofreaders («Распределённые корректоры») больше десяти лет занимается сканированием книг для проекта «Гутенберг». Сотни добровольцев помогают вычитывать тексты и исправлять ошибки.
После автоматического распознавания чаще всего ошибки встречаются в символах, которые похожи друг на друга, как I, l и 1, O и 0, и так далее. Если пользоваться обычным шрифтом вроде Times, то такие ошибки можно и не заметить. Поэтому для проекта Distributed Proofreaders был создан специальный шрифт, в котором «похожие» символы как можно сильнее отличаются друг от друга.
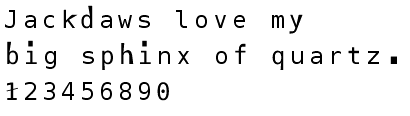
После автоматического распознавания чаще всего ошибки встречаются в символах, которые похожи друг на друга, как I, l и 1, O и 0, и так далее. Если пользоваться обычным шрифтом вроде Times, то такие ошибки можно и не заметить. Поэтому для проекта Distributed Proofreaders был создан специальный шрифт, в котором «похожие» символы как можно сильнее отличаются друг от друга.