Я расскажу о том, как настроить автоматический запуск модульных тестов в сервисе Travis CI для .NET Core проекта, в котором используется PostgreSQL.
Можно использовать эту статью как пример для быстрого старта.


User
Я расскажу о том, как настроить автоматический запуск модульных тестов в сервисе Travis CI для .NET Core проекта, в котором используется PostgreSQL.
Можно использовать эту статью как пример для быстрого старта.
Этот туториал я пишу прежде всего для себя, для того чтобы иметь возможность быстро на основе начального шаблона ASP.NET Core приложения создать минимальное приложение с поддержкой npm, Webpack и TypeScript (у которого будет работать отладка из Visual Studio).
Вторая статья из серии о full-stack JS разработке.
JavaScript постоянно меняется, очень сложно угнаться за последними технологиями, ведь то, что было лучшей практикой полгода назад, сейчас уже устарело. Подобные утверждения во многом правда, но следует отметить, что это больше относится к клиентскому JavaScript. Для сервера все гораздо стабильнее и основательней.

Уважаемые хабравчане.
Поскольку дискуссия вокруг статьи идет весьма активно, Жан-Жак Дюбре (он читает комментарии) решил организовать чаты в gitter.
Вы можете пообщаться с ним лично в следующих чатах:
https://gitter.im/jdubray/sam
https://gitter.im/jdubray/sam-examples
https://gitter.im/jdubray/sam-architecture
Также автор статьи разместил примеры кода здесь: https://bitbucket.org/snippets/jdubray/
По поводу кода он оставил следующий комментарий:
I don't code for a living, so I am not the best developer, but people can get a sense of how the pattern works and that you can do the exact same thing as React + Redux + Relay with plain JavaScript functions, no need for all these bloated library (and of course you don't need GraphQL).
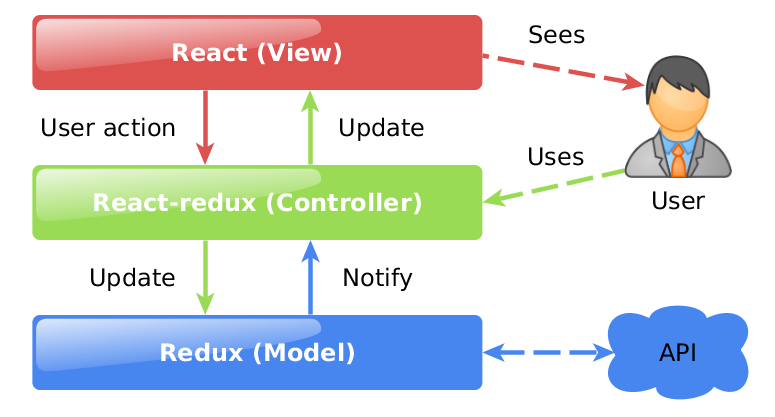
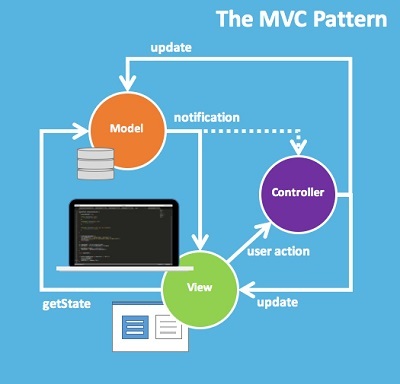
React и Redux, в последнее время одни из самых популярных buzz-words в мире фронтенда. Поэтому когда мне потребовалось сделать веб-приложение, которое бы отображало данные, полученные с сервера, а также позволяло бы ими манипулировать (создавать, удалять и изменять), я решил построить его на основе связки React и Redux. Множество getting-started руководств покрывают только функционал создания компонентов, action creators и reducers. Но как только дело касается обмена с сервером, начинаются сложности — растет количество необходимых action creator, редьюсеров. Причем они очень похожи друг на друга, с миниальными отличиями. В большинстве случаев — только в типе (имени) активности. После того, как я создал третий одинаковый набор креаторов и редьюсеров, то появилось желание что-то изменить. Так родилась идея реализации redux-redents.
Это седьмая статья из цикла «Теория категорий для программистов». Предыдущие статьи уже публиковались на Хабре:
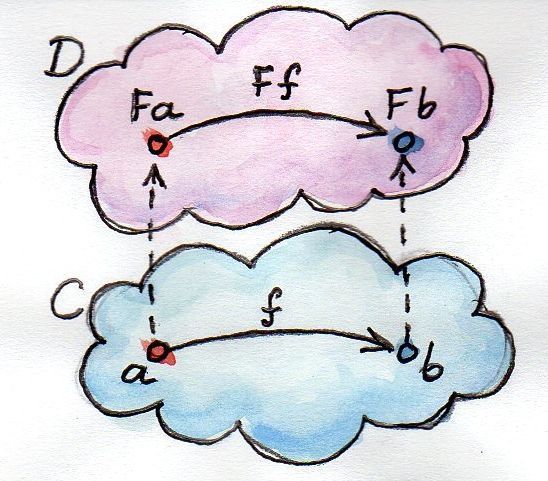
За понятием функтора стоит очень простая, но мощная идея (как бы заезжено это ни прозвучало). Просто теория категорий полна простых и мощных идей. Функтор есть отображение между категориями. Пусть даны две категории C и D, а функтор F отображает объекты из C в объекты из D — это функция над объектами. Если a — это объект из C, то будем обозначать его образ из D как F a (без скобок). Но ведь категория — это не только объекты, но еще и соединяющие их морфизмы. Функтор также отображает и морфизмы — это функция над морфизмами. Но морфизмы отображаются не как попало, а так, чтобы сохранять связи. А именно, если морфизм f из C связывает объект a с объектом b,
f :: a -> bто образ f в D, F f, связывает образ a с образом b:
F f :: F a -> F b(Надеемся, что такая смесь математических обозначений и синтаксиса Haskell понятна читателю. Мы не будем писать скобки, применяя функторы к объектам или морфизмам.)




"Если хочешь идти быстро — иди один. Если хочешь идти далеко — идите вместе." (с)
С этой лирической строки в данной статье я буду рассуждать о том, как правильно организовать код в вашем приложении, чтобы оно могло расти в высоту и в ширь. Если вы хотите, чтобы продукт вашей мозговой активности был мощнее, чем у ваших конкурентов, то вам неизбежно придется приглашать новых программистов в вашу команду. А если не положить вектор масштабируемости, то порывы энтузиазма через год превратятся в лапшу-код и командная работа превратит каждого сотрудника от злости в маленького сатану.
Так вот… Для того, чтобы ваши бойцы чувствовали себя комфортно вместе в одном проекте, надо чтобы они не мешали друг другу и писали свои буквы в разных не пересекающихся участках кода. Для этого им нужно будет писать "Самостоятельные" компоненты.


http://example.comwww.example.com//www.example.commailto:user@example.com
step, и возвращающая новую функцию step.step⁰ → step¹
step, в свою очередь, принимает текущий результат и следующий элемент, и должна вернуть новый текущий результат. При этом тип данных текущего результата не уточняется.result⁰, item → result¹
step¹, нужно вызвать функцию step⁰, передав в нее старый текущий результат и новое значение, которое мы хотим добавить. Если мы не хотим добавлять значение, то просто возвращем старый результат. Если хотим добавить одно значение, то вызываем step⁰, и то что он вернет возвращаем как новый результат. Если хотим добавить несколько значений, то вызываем step⁰ несколько раз по цепочке, это проще показать на примере реализации трансдьюсера flatten:function flatten() {
return function(step) {
return function(result, item) {
for (var i = 0; i < item.length; i++) {
result = step(result, item[i]);
}
return result;
}
}
}
var flattenT = flatten();
_.reduce([[1, 2], [], [3]], flattenT(append), []); // => [1, 2, 3]
step несколько раз, каждый раз сохраняя текущий результат в переменную, и передавая его при следующем вызове, а в конце вернуть уже окончательный.step, вызывает другую, а та следующую, и так до последней служебной функции step, которая уже сохраняет результат в коллекцию (append из первой части). Привет Хабр! Примерно год назад я представил вашему вниманию первую версию open-source библиотеки FileAPI, предназначенную для работы с файлами на клиенте и последующей загрузки на сервер.
Привет Хабр! Примерно год назад я представил вашему вниманию первую версию open-source библиотеки FileAPI, предназначенную для работы с файлами на клиенте и последующей загрузки на сервер.