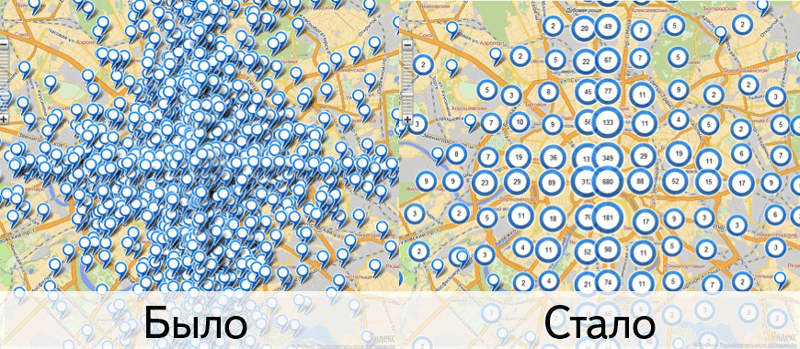
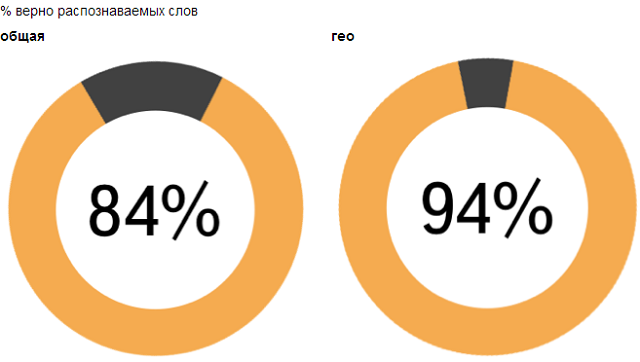
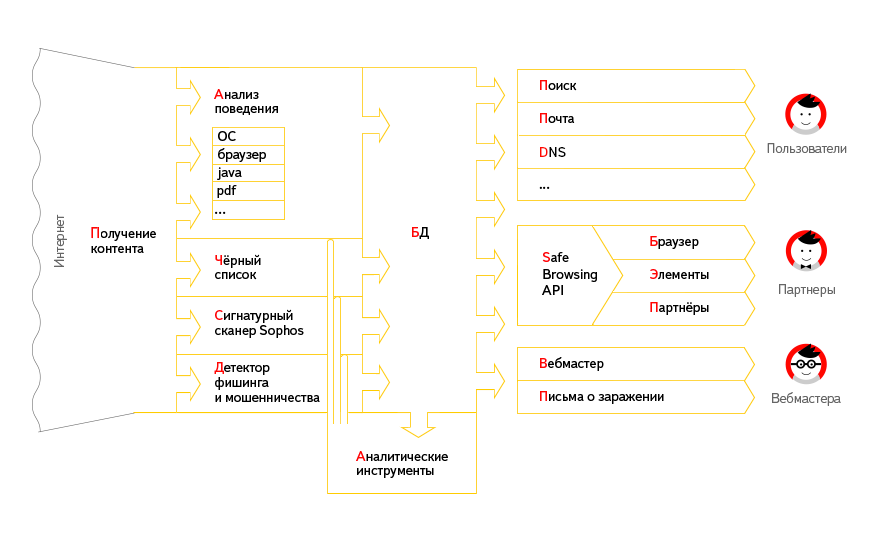
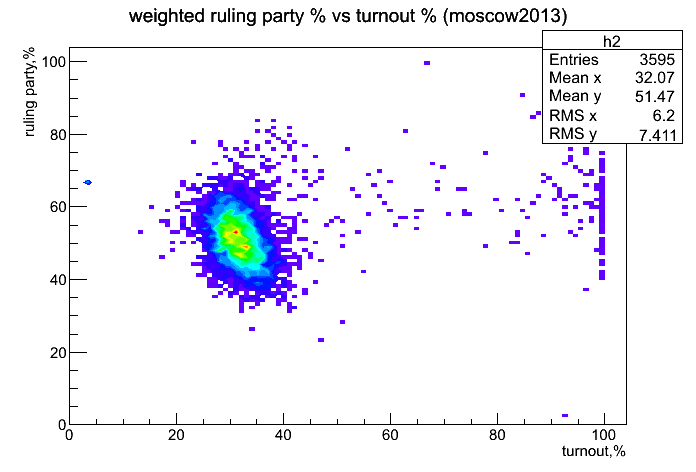
Для начала давайте кое о чем договоримся. Я воспринимаю интернет-проекты так же, как любое другое шоу. Конечно есть некоторая разница между телепрограммой и блогом, однако сходств значительно больше чем различий. По этой же причине и словарь мой состоит в основном из простых слов, не связанных с интернетом. Проводите аналогии, вы узнаете то же, что знаю я. Да, и упреждая вопрос «откуда я взялся такой умный» — я давно был. И количество шоу, которые я режиссировал перевалило за два десятка. А количество шоу, за которыми я пристально смотрел — думаю за две сотни.
0. Есть разные способы измерять успешность шоу, однако для каждого шоу мерило успешности одно. Для блога это посещаемость, для интернет-магазина — продаваемость товара, для телевикторины — количество людей, которые не бегут на кухню во время рекламы. Так вот, определите мерило успешности вашего шоу, следите за ним, измеряйте его. Только так вы научитесь понимать какие ваши действия приводят к каким результатам.
1. Самый сложный совет, особенно для тех, кто уже начал своё шоу. Очень важно понимать что и зачем вы делаете. Как не странно это совсем не очевидно. Допустим вы ведете блог о летающих тарелках. Ответьте себе на вопросы: зачем вы это делаете? какова конечная цель шоу? кто ваша аудитория. Если ответы для вас не очевидны — шоу обречено на провал.
2. Следите за аудиторией, но не потакайте ей. Типовая ошибка многих шоу — прислушиваться к каждому фидбеку зрителя, к каждой критике со стороны. Не забывайте, большая часть ваших зрителей дилетанты в шоу, они не знают того, что знаете вы. Если вы плохо переносите прикладную психологию — попробуйте просто игнорировать критику, используйте только положительный фидбек. Есть две причины делать именно так: во-первых зритель, довольный шоу очень ленив и не полезет звонить-писать что-то о том, как ему понравилось. Если уж он написал вам “это было круто!!11” — значит это было действительно круто, задумайтесь. Во-вторых люди, критика которых заслуживает уважения и рассмотрения, очень редко бывает бесплатной, да и этих людей вы сами уже знаете и можете пересчитать по пальцам. Я надеюсь одной руки.
3. Играйте с аудиторией, она это любит. Этот совет подходит не всем, но явному большинству шоу. “Скандалы, интриги, расследования” — это один из лучших способов привлечения новых людей. Только боже вас упаси перепутать “играйте” с “заигрывайте”.
4. Если вы активный участник шоу — выберите себе имидж, опишите его и придерживайтесь его до конца, чего бы вам это не стоило. Зрители посещают ваше шоу не для того, чтобы увидеть как вы изменились. Если конечно ваше шоу не о том, как вы меняетесь.
5. Никогда не раскрывайте публично всех секретов вашего шоу. Магия, мистика, загадка, назовите это как хотите — но шоу без этого превращается в фарс, а иногда и в фарш.
Только записав всё это как на духу я понял, что все хорошие шоу подчиняются правилу сериалов. Этих правил всего три:
1. Есть сквозная сюжетная линия, которая обычно вмещается в пару-тройку предложений. В течении всего сериала эта сюжетная линия и раскрывается
2. Каждая серия должна заканчиваться примерно там же, где начиналась. Все основные персонажи переходят из серии в серию неизменными.
3. Одна из 12ти серий должна нарушать правило 2, чтобы следовать правилу 1.
Думаю на этом сегодня можно поставить точку с запятой. Если у вас есть свежие мысли по этому поводу — выкладывайте. А то не дай бог я напишу еще.